크롬 드라이버 다운로드하기
Selenium은 크롬 드라이버를 통해 웹 페이지 크롤링을 진행하기에 자신의 크롬 버전과 같은 크롬 드라이버를 받아야한다.
- 드라이버 다운로드 페이지 접속
- 크롬 정보 보기
2-1. 크롬 실행
2-2. 설정(우측 위 점3개 클릭 후 설정)
2-3. 왼쪽 위 설정 정보 열기

2-4. 맨 아래 Chrome 정보
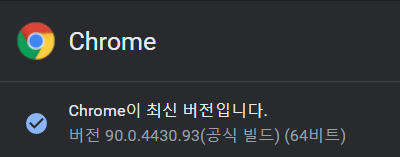
2-5. 크롬 버전 확인
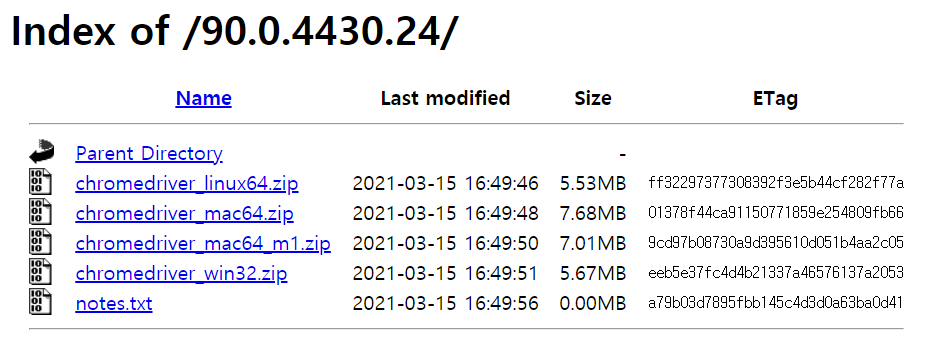
- 크롬 드라이버 다운로드
- 파이썬 파일(.ipynb or .py)과 같은 경로상에 크롬 드라이버 두기
코드 설명
1. 초기 설정
# 초기설정
chromedriver = './chromedriver.exe' # 크롬 드라이버 경로
options = webdriver.ChromeOptions()
options.add_argument('headless') # 실행했을 때 웹 브라우저를 띄우지 않는 headless chrome 옵션 적용
options.add_argument('disable-gpu') # GPU 사용 안함 --> headless 설정, gpu 사용 안함 : 속도 향상
options.add_argument('lang=ko_KR') # 언어 설정
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko") # 봇 차단을 막기 위한 우회
driver = webdriver.Chrome(chromedriver, options=options) # 옵션 적용
driver.implicitly_wait(100) # 위 설정을 적용하는 데 시간이 걸리기 때문에 기다려주기 (최대 100초를 기다리되, 중간에 완료되면 바로 넘어감)
- 사이트 접속 및 이름, 경로, 작가 받아오기
# 사이트 접속 및 이름, 경로, 작가 받아오기
driver.get("http://webtoon.daum.net/#sort=free&genre=&tab=finish") # driver.get : () 링크로 접속 --> 다음 완결 웹툰 페이지 접속
data_name = driver.find_elements_by_class_name('tit_wt') # 웹툰 이름 크롤링
data_link = driver.find_elements_by_class_name('link_wt') # 웹툰 경로 크롤링
data_author = driver.find_elements_by_class_name('txt_info') # 웹툰 작가 크롤링
# 무료 완결 웹툰에서 크롤링을 하면 마지막에 연재웹툰 1~5위 완결웹툰 1~5위 링크가 추가로 나옴
# --> 링크가 이름보다 10개 많음(다 무료 완결 아니니 신경 X)
find_elements_by_class_name : 파라미터 값의 클래스 이름을 가진 태그를 모두 가져옴
▶ 다른 태그 찾는 방법
find_elements_by_tag_name
find_elements_by_xpath
find_elements_by_id
find_elements_by_class_name
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_css_selector
- 웹툰 상세내용 크롤링
# 웹툰 상세내용 크롤링 (웹툰 스토리, 장르, 썸네일(모바일버전이 화질이 좋음)
import csv
f = open("write_temp.csv","w", encoding = "utf-8") # write.csv 파일 열기 (파일이 없어도 알아서 만들어줌)
# 파일 경로는 현재 파이썬 파일 경로와 같음
wr = csv.writer(f) # csv 파일을 수정할 것을 선언
for i in range(0, len(data_name)):# 반복의 기준은 완결 웹툰 이름 (링크는 갯수가 다름)
webtoonName = data_name[i].text # 태그의 내용 (<span> 내용 </span>)을 읽어올 땐 .text
driver_temp = webdriver.Chrome(chromedriver, options=options) # 옵션 적용
driver_temp.implicitly_wait(100)
link = "http://m." + data_link[i].get_attribute('href')[7:] # 모바일 링크로 변경
last_link = link.replace(" ", "") # 위 코드에서 생기는 공백 제거 ( http://m, 과 링크 사이에 공백이 생김)
driver_temp.get(last_link) # 완결 웹툰 상세페이지 받아오기
if data_name[i].text[0:2] == "성인": # 성인웹툰은 이름 크롤링시 웹툰 이름 앞에 성인이 붙음
webtoonName = webtoonName[3:]
# --> 웹툰 이름 앞 두글자가 성인이면 성인웹툰으로 판단 후 제외
# --> 성인이 아닐 시 if문 내용(if문은 지우지 말고)을 주석처리
driver_temp.find_element_by_class_name("link_login.link_klogin").click()
driver_temp.find_element_by_name('email').send_keys(kakao_id)
driver_temp.find_element_by_name('password').send_keys(kakao_password)
driver_temp.find_element_by_class_name('btn_g.btn_confirm.submit').click()
# print("login_end \n")
webtoonGenre = "" #변수선언
print(webtoonName) # 웹툰 이름 출력
print("작가 : ", data_author[i].text) # 작가 출력
webtoonStory = driver_temp.find_element_by_class_name('txt_story') # 스토리 받아오기
print(webtoonStory.text) # 웹툰 스토리 출력
webtoonGenre = driver_temp.find_element_by_class_name('txt_genre') # 장르 받아오기
print("장르 : ", webtoonGenre.text) # 웹툰 장르 출력
data_thumb = driver_temp.find_element_by_class_name('img_thumb') # 웹툰 썸네일 -> 모바일 웹툰 상세페이지에서 받으면 배경이 없음
print("썸네일 : ", data_thumb.get_attribute('src')) # 썸네일링크 출력 - 썸네일 다운로드
# 썸네일 다운로드
import urllib
import re
url_image = data_thumb.get_attribute('src')
webtoonName_pre = re.sub('[^\s0-9a-zA-Zㄱ-힗!@#$%*()]', '', str(webtoonName)) # 저장이 안되는 특수기호 제거
save1 = "D:/thumb_daum/" + webtoonName_pre + ".png" # 이미지를 저장 할 경로
# 주소 앞에 자신한테 맞는 주소로 변경 -> 파일 만들어져있지 않으면 오류남 (D 드라이브에 thumb 폴더가 있는 상태로 실행)
hdr = {'User-Agent': 'Mozilla/5.0'} # 봇 차단 방지를 위한 헤더 추가 (파이어폭스로 설정)
req = urllib.request.Request(url_image, headers = hdr);
file_temp = urllib.request.urlopen(req).read()
file_save = open(save1,'wb') # w : 쓰기, r : 읽기 , a : 더하기, wb : 바이너리로 쓰기
file_save.write(file_temp)
file_save.close()
link = "http://m." + data_link[i].get_attribute('href')[7:] # 모바일 링크로 변경
last_link = link.replace(" ", "") # 위 코드에서 생기는 공백 제거 ( http://m, 과 링크 사이에 공백이 생김)
print("링크 : ", last_link) # 링크 출력
print("") #구분을 위한 줄 띄우기
wr.writerow([webtoonName,data_author[i].text,data_thumb.get_attribute('src'),webtoonGenre.text,webtoonStory.text,last_link])
#csv_writer.writerow((data_name[i].text, data_author[i].text, img_thumb, txt_genre, txt_story, last_link))
driver_temp.quit()
f.close()
driver.quit()