
🔍 비지도 학습: 데이터 내재 패턴 탐색
데이터 학습 방식은 지도 학습과 비지도 학습으로 구분된다. 각 방식의 특징은 다음과 같다.
지도 학습 (Supervised Learning): 입력 데이터와 정답(Target)이 함께 제공되며, 알고리즘은 이를 통해 예측 모델을 구축한다. 스팸 메일 분류 및 주택 가격 예측 등이 주요 예시로 제시된다.
비지도 학습 (Unsupervised Learning): 입력 데이터만을 활용하여 데이터 내부에 숨겨진 구조, 패턴, 그룹을 자율적으로 발견한다. 고객 세분화, 이상 탐지, 추천 시스템 등이 해당 방식의 적용 사례에 해당한다.
최근 수행된 미니 프로젝트를 통해 비지도 학습의 중요성이 확인되었다. 타이타닉 데이터는 명확한 Target 변수를 포함하여 지도 학습이 적용 가능했으나, 건강검진 데이터는 Target이 부재했다. 이에 비지도 학습을 도입하여 데이터 내에서 의미 있는 그룹을 식별하였으며, 이는 통찰 도출에 기여하였다. 학번, 도서 코드, 전자제품 모델명 등은 계층적 군집화(Hierarchical Clustering)를 통해 분류 및 구조화될 수 있는 비지도 학습의 예시로 파악된다.
🧠 딥러닝: 인공지능 발전의 핵심 동력
딥러닝(Deep Learning)은 인공지능 분야의 핵심 기술로, 인간 뇌의 신경망 구조를 모방한 머신러닝의 한 영역으로 정의된다. 딥러닝 모델은 입력층, 은닉층, 출력층으로 구성되며, 각 층의 깊이 및 뉴런 수가 모델 성능에 영향을 미치는 주요 파라미터로 작용한다.
주요 딥러닝 아키텍처는 다음과 같다.
MLP (Multi-Layer Perceptron): 가장 기본적인 신경망 구조에 해당한다.
CNN (Convolutional Neural Network): 이미지 처리 및 컴퓨터 비전 분야에 특화되어 있다.
RNN (Recurrent Neural Network): 시계열 및 순차 데이터 처리에 강점을 가진다.
Transformer: 시퀀스 데이터의 병렬 처리를 혁신하여 LLM 발전에 중대한 기여를 하였다.
GPT, GEMINI 등 대규모 언어 모델(LLM)은 Transformer 아키텍처를 기반으로 발전하였다. Transformer는 어텐션(Attention) 메커니즘을 통해 문장 내 장거리 의존성을 효과적으로 포착하며, 병렬 처리 능력으로 대규모 모델 학습을 가능케 하였다. 이는 딥러닝 분야의 핵심 전환점으로 평가된다.
Transformer 기반 LLM은 토큰화(Tokenization) 과정을 거쳐 학습되며, 강화학습(RLHF: Reinforcement Learning from Human Feedback) 및 파인 튜닝(Fine-tuning)을 통해 사용자 의도에 부합하는 응답을 생성하도록 정교화될 수 있다.
모델 발전과 동시에, 강력한 연산을 지원하는 하드웨어(GPU 등)의 발전과 안정적인 전력 공급의 중요성 또한 확인된다. 모델 자체의 성능 최적화뿐 아니라 효율적인 인프라 구축 및 관리에 대한 고려가 필수적이다.
📊 Tensor: 딥러닝 데이터 구조의 근간
텐서(Tensor)는 딥러닝의 핵심 데이터 구조이자 연산의 기본 단위이다. 스칼라, 벡터, 행렬을 포괄하는 다차원 배열의 개념으로, 이미지, 텍스트 등 다양한 형태의 데이터를 표현하는 데 사용된다.
텐서는 딥러닝 모델의 입출력을 정의하며, 모델 내부의 모든 수학적 연산은 텐서 간의 연산으로 구성된다. GPU/TPU와 같은 하드웨어 가속기에서 대규모 연산을 효율적으로 병렬 처리하기 위한 핵심 요소이다.
딥러닝 학습의 핵심인 역전파(Backpropagation) 과정에서 모델 가중치 업데이트를 위한 기울기(Gradient) 계산 역시 텐서 연산을 통해 이루어진다. PyTorch, TensorFlow 등 딥러닝 프레임워크는 텐서를 기본으로 하여 이러한 계산을 자동화한다. 텐서에 대한 이해는 딥러닝 모델의 효과적인 구축 및 최적화를 위해 필수적이다.
📈 MLP 실습: 온도 예측 모델 구축 사례

최근 실습 프로젝트에서는 MLP 아키텍처를 활용한 온도 데이터 예측 작업이 수행되었다. 과거 온도 데이터를 입력받아 미래의 특정 온도 값을 예측하는 것이 목표였다.

데이터 분할 시 test_size는 0.2로 설정되었다. 테스트 세트 비율이 과도하게 낮을 경우 모델의 과적합 위험이 증가하므로, 통상적으로 0.2 ~ 0.3 비율이 권장된다.
Batch Size (배치 크기)는 1회 모델 업데이트에 사용되는 데이터 샘플의 개수를 의미한다. 이 파라미터는 학습 안정성 및 속도에 영향을 미치므로, 적절한 값 설정이 중요하다.

상기 코드는 TempPredictor MLP 모델의 구조를 정의한다. n_steps는 입력 피처의 개수로, 이전 시점의 온도 데이터를 의미한다.
모델은 n_steps개 입력 특성으로 시작하여, 1024개, 512개 뉴런으로 구성된 은닉층을 거친다.
최종 출력층은 1개의 뉴런으로 구성되어 있으며, 이는 단일 온도 값 예측을 위한 회귀 문제 해결을 의미한다.

Learning Rate (lr, 학습률)은 옵티마이저가 모델 가중치를 업데이트할 때의 보폭 크기를 나타낸다. 기울기(Gradient)에 승산되어 실제 파라미터 업데이트 크기를 결정한다.
lr이 과도하게 높을 경우 학습 불안정 및 발산 가능성이 존재한다.
lr이 과도하게 낮을 경우 수렴 속도 저하 또는 지역 최저점(Local Minima)에 갇힐 위험이 있으며, 이는 자원 낭비를 초래할 수 있다.
따라서 데이터 및 모델에 적합한 lr 값 설정이 중요하게 고려된다.

Epoch (에폭)은 모델이 전체 학습 데이터셋을 반복 학습하는 횟수를 의미한다. 각 에폭 동안 모델은 미니 배치 단위로 순전파, 손실 계산, 역전파, 가중치 업데이트 과정을 반복 수행한다.
에폭 수가 부족할 경우 과소적합, 과도할 경우 학습 데이터 노이즈까지 학습하여 과적합(Overfitting) 문제를 야기할 수 있다.
에폭 수 증가는 학습 시간 증가로 이어진다.
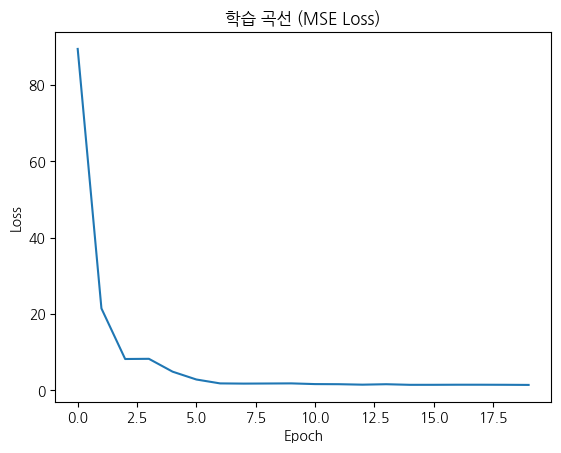
따라서 MSE Loss 그래프 등 학습 지표를 모니터링하여 적절한 에폭 수를 결정하는 것이 중요하다. 상기 그래프에서는 약 10 에폭에서 손실이 안정화되는 경향이 관찰된다.
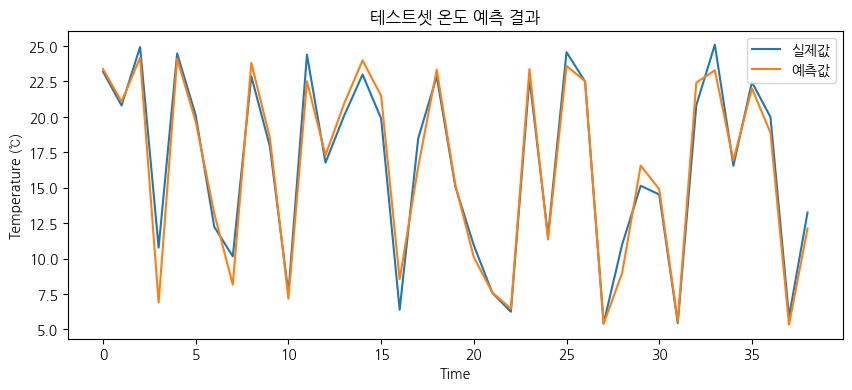
모델 학습 완료 후, 실제 값과 예측 값을 비교하고, MSE (평균 제곱 오차), MAE (평균 절대 오차), R2 Score (결정 계수) 등의 지표를 활용하여 모델 성능을 정량적으로 평가한다.
2025 스마트농업 AI 경진대회

스마트팜 기술에 대한 관심에 기반하여 '2025 스마트농업 AI 경진대회'에 참가하게 되었다. 장기 프로젝트 수행을 선호하는 점을 고려할 때, 본 대회는 의미 있는 기회로 판단된다. 이에 따라 현업 농장주를 포함한 10명으로 구성된 '데이터 아뜰리에' 팀을 조직하였다.
현재 본선 진출을 위한 사전 테스트 및 예선이 예정되어 있다. 우리 팀은 기존 수업 및 Dacon 플랫폼을 통한 다양한 모델 학습과 데이터 기반 예측 모델 구축 경험을 보유하고 있다. 이러한 경험을 토대로 사전 테스트에서 Top 30 내 진입하여 예선에 통과할 것으로 전망한다.
본 대회를 통해 스마트팜 전문 지식뿐 아니라, 코딩, 데이터 분석, 예측 모델 구축, 프로젝트 매니징 역량 등 다방면의 역량 강화를 목표로 한다.
'데이터 아뜰리에' 팀, 화이팅!!

팀 언급 자제좀요;;