
스마트농업 AI 경진대회

7월 30일(수) ~ 7월 31일(목)에 경진대회 사전테스트를 진행했다. x_train, y_train, x_test, submission 총 4개 csv파일을 받았다. x_train, y_train 데이터를 통해 학습을 하고 x_test 데이터를 보고 co2 final(submission) 값을 유추하는 과제이다.
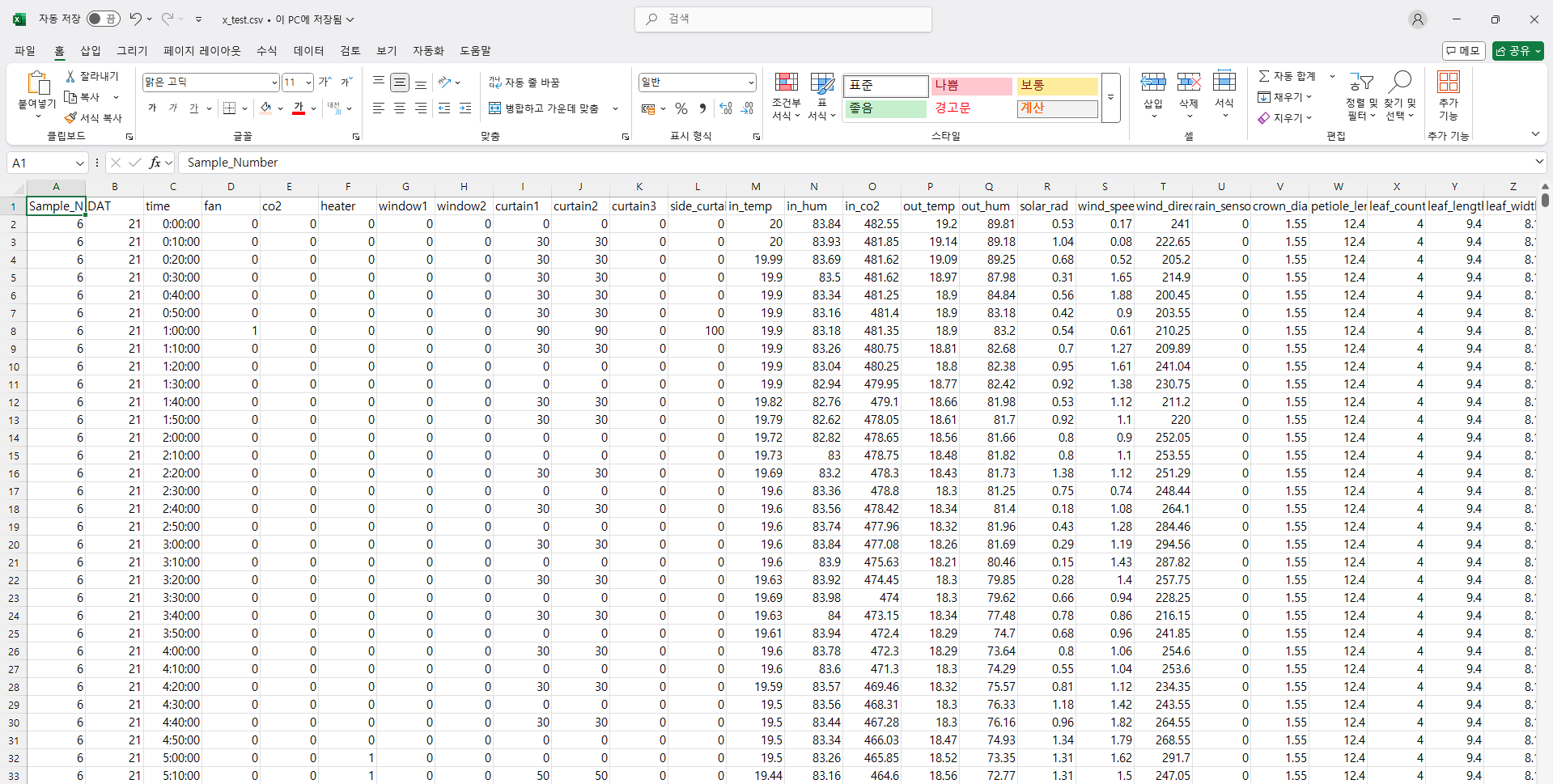
데이터 특성을 보고 Case 나누기, 이상치 대체하기, y값 나누기와 같은 전처리를 진행했다. 사전테스트 결과를 알고 있는 현시점에서 우리 팀의 전처리 방식은 완벽했다고 생각한다. 모델은 앙상블 모델을 사용했다. XGBOOST, LSTM, RF로 앙상블을 구상했다. 사실 XGBOOST 개별의 성능이 제일 좋았지만 과적합 방지를 위해 굳이 앙상블을 사용했다. 마지막으로 검증을 2번 진행했다.
train 데이터에서 일부분을 추출해서 가짜 test 데이터를 만들었다. 이를 통해 내가 돌리는 모델이 과적합인지 아닌지 확인할 수 있었다.

결과적으로는 52팀중에 7등했다. 예선 1차에서 10팀을 선발하는데 해당 과제에도 자신있다. 다음주 금요일에 예선 1차 굉장히 잘 할 것으로 예상한다.
