- 대용량 로그 데이터 수집
로그 데이터 수집 시스템의 예 : 아파치 flume-ng, 페이스북 scribe, 아파치 chukwa
- 특징
- 초고속 수집 성능과 확장성 : 실시간, 수집대상서버가 증가하면 증가량을 따라잡을수 있어야 함- 데이터 전송 보장 메커니즘 : 수집된 데이터는 처리 및 분석을 위한 저장소인 분산파일 시스템, NoSQL, DB등에 저장되어야 함. 이 전송이 보장되어야 함.
- 다양한 수집과 저장 플러그인 : 로그 뿐 아니라 성능 모니터링 데이터, 소셜 서비스 데이터 등과 같은 다양한 비정형 데이터 '도' 저장할 수 있도록 내장 플러그인을 제공해야함
- 인터페이스 상속을 통한 애플리케이션 기능 확장 : 업무 특성 상 수집 시스템에서 제공하는 기능 중 일부를 수정해야 하는 경우 인터페이스를 확장해 원하는 부분만 비즈니스 용도에 맞게 수정할 수 있어야 함
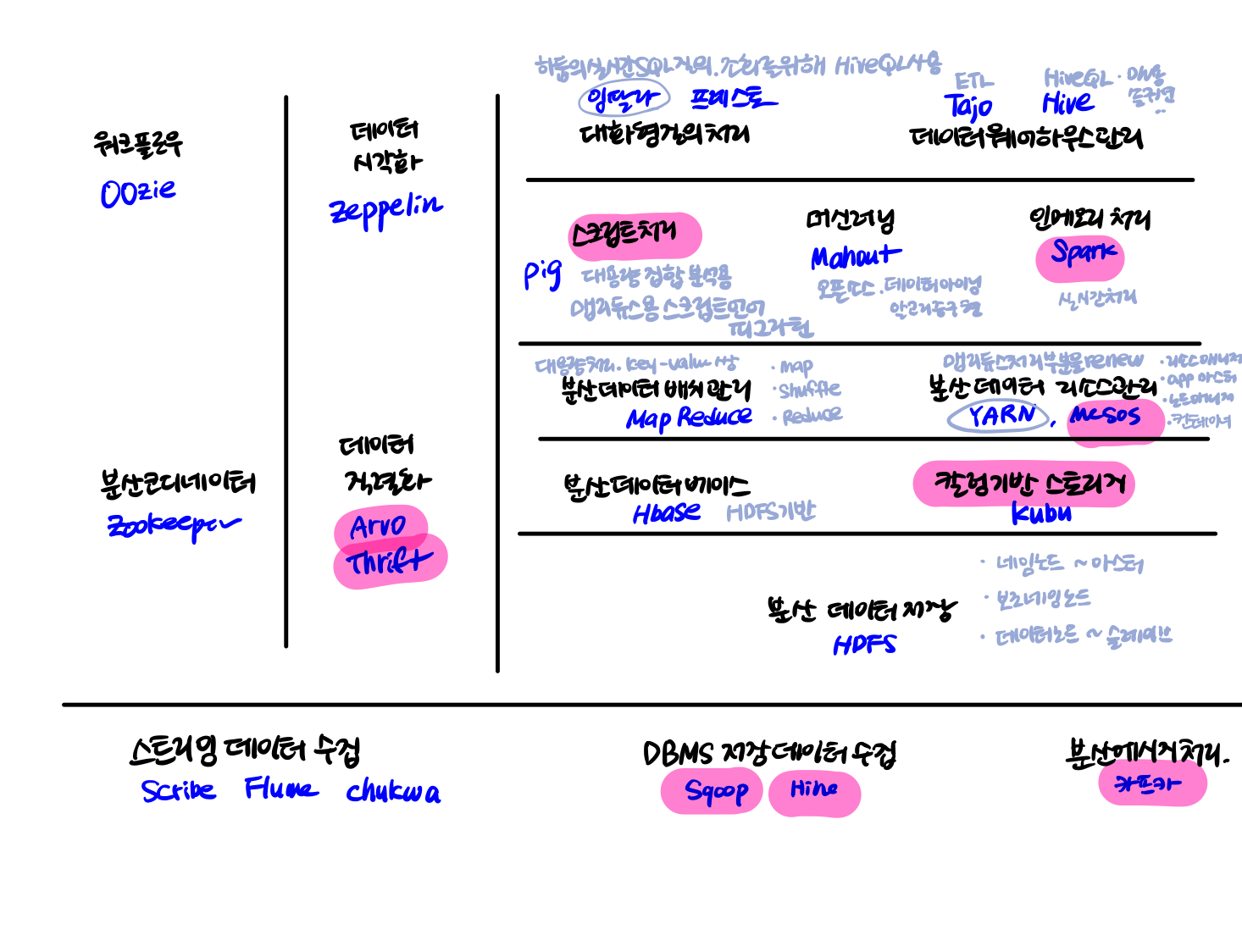
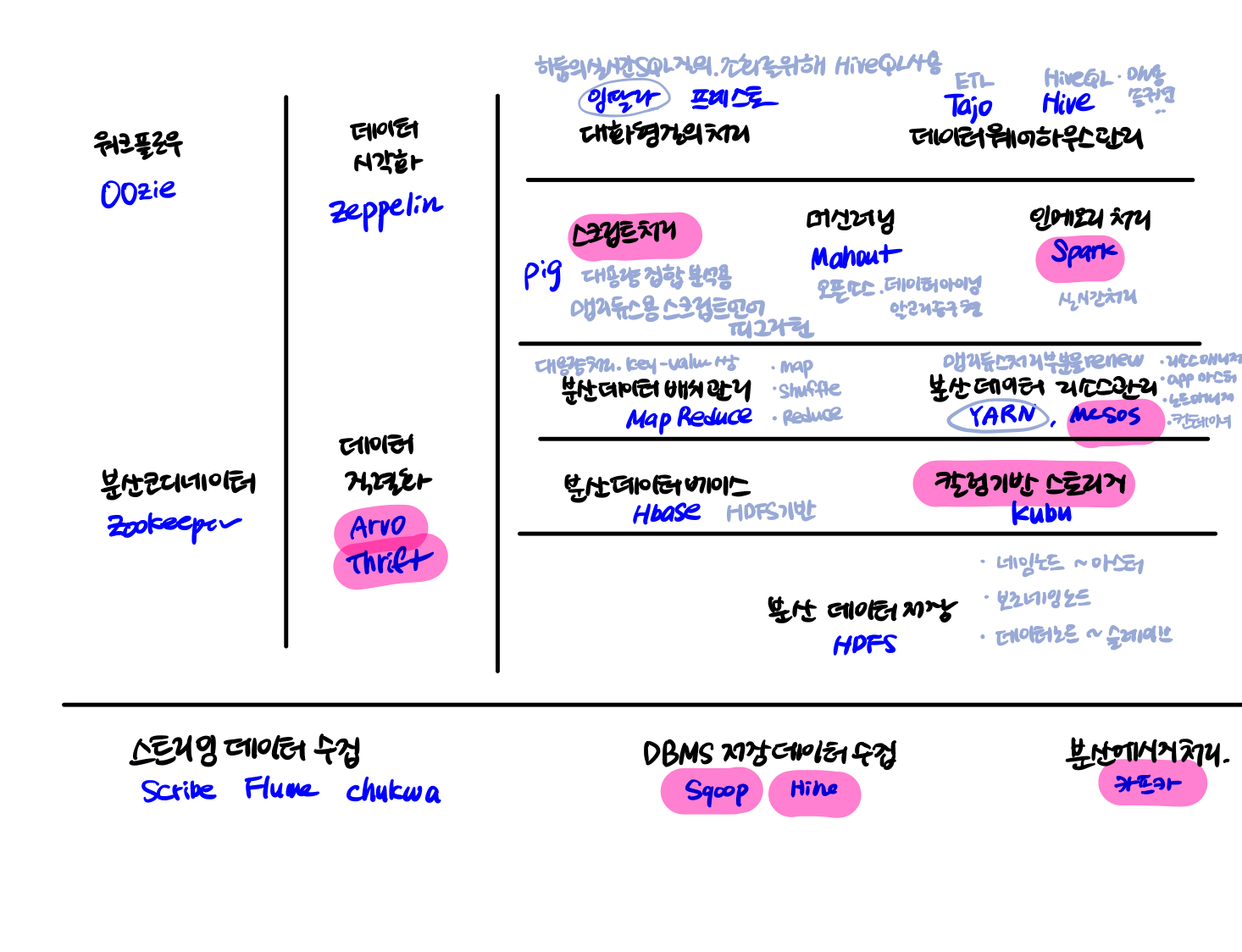
- 대규모 분산 병렬처리 : 하둡
맵리듀스 시스템과 HDFS를 핵심 구성요소로 가지는 플랫폼 기술.
여러대의 컴퓨터를 하나의 시스템인 것처럼 묶어 분산환경에서 빅데이터를 저장 및 처리할 수 있다.
- 특징
- 선형적인 성능과 용량 확장
여러대의 서버로 클러스터를 만들어 하둡을 구축할 때 이론적으로는 대수에 제한이 없다. (5개가 통상적임) 비공유 분산 아키텍처 시스템이기 때문에 서버를 추가하면 연산과 저장 기능이 서버의 대수와 비례해 증가한다.- 고장감내성
HDFS에 저장되는 데이터는 3중복제기되어 다른 물리서버에 저장되므로 서버에서 장애가 발생하더라도 데이터 유실을 방지할 수 있다. 맵리듀스 작업 중 장애가 생기면 장애가발생한 특정 태스크만 다른 서버에서 재실행할 수 있다. - 핵심비즈니스 로직에 집중
하둡의 맵리듀스는 맵과 리듀스라는 2개의 함수만 구현하면서 동작한다. 따라서 비즈니스 로직에만 집중하면서 시스템 수준에서 발생하는 장애에 대해서는 신경쓰지 않을 수 있도록 하둡 내부적으로 최적화해서 처리한다. - 하둡 에코시스템
하둡 프레임워크를 이루고 있는 다양한 서브프로젝트들의 집합
- 고장감내성

배우는중인 두리