ADP
1.기업의 데이터베이스 활용

정보통신망 구축초기에는 부서 내의 단절된 정보의 저장만 가능 -> 구축이 진행되며 인사, 조직, 생산, 영업을 포함한 모든 자료를 연계한 일관 체계 구축이 가능해짐OLTPonline transaction processing정보처리기사 시험을 준비할 때 단순히 t 는 트
2.데이터의 가치와 미래
모든 자격증 시험에서 나오는 개론같은 이야기를 늘어놓는 부분이다. varietyvelocityvolumnevalueveracity(진실성)validityvolatilty(휘발성)데이터의 규모, 형태, 속도가 변화하면서 그 데이터를 처리하는 기술에 변화가 있었고 (클라우
3.비식별기술, 암묵지와형식지, DIKW의 계층적구조
개인정보 유출 방지를 위해 사용되는 기술간의 구분 익명화 난수화 범주화 마스킹 암묵지와 형식지 산업별 분석사례의 특징 기업별 사례 olap 다차원의 데이터를 대화식으로 분석하는 것
4.What's your ETL
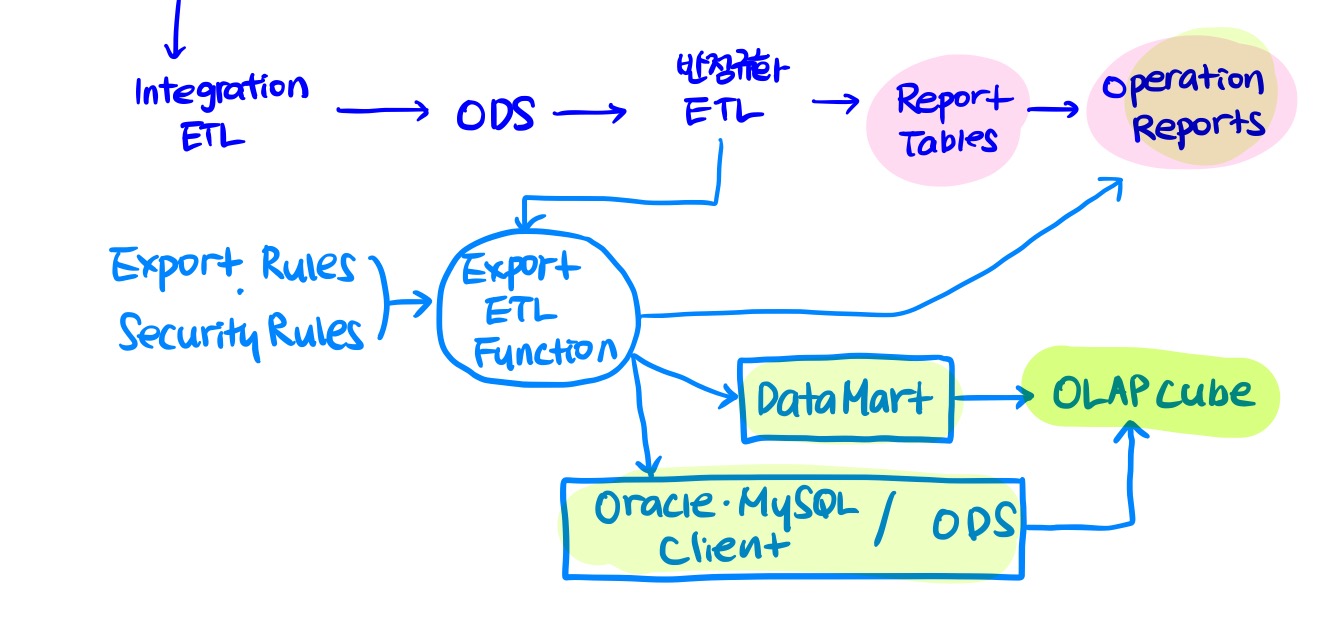
ETL을 해체해보자 개념 Extraction : 하나 또는 그 이상의 데이터 원천으로부터 추출 Transformation : 추출된 데이터를 클렌징, 형식변환, 표준화, 통합 등 Load : 변형된 데이터를 특정 목표 시스템에 적재 위 그림은 데이터 처리 프로세스
5.DM the DWH
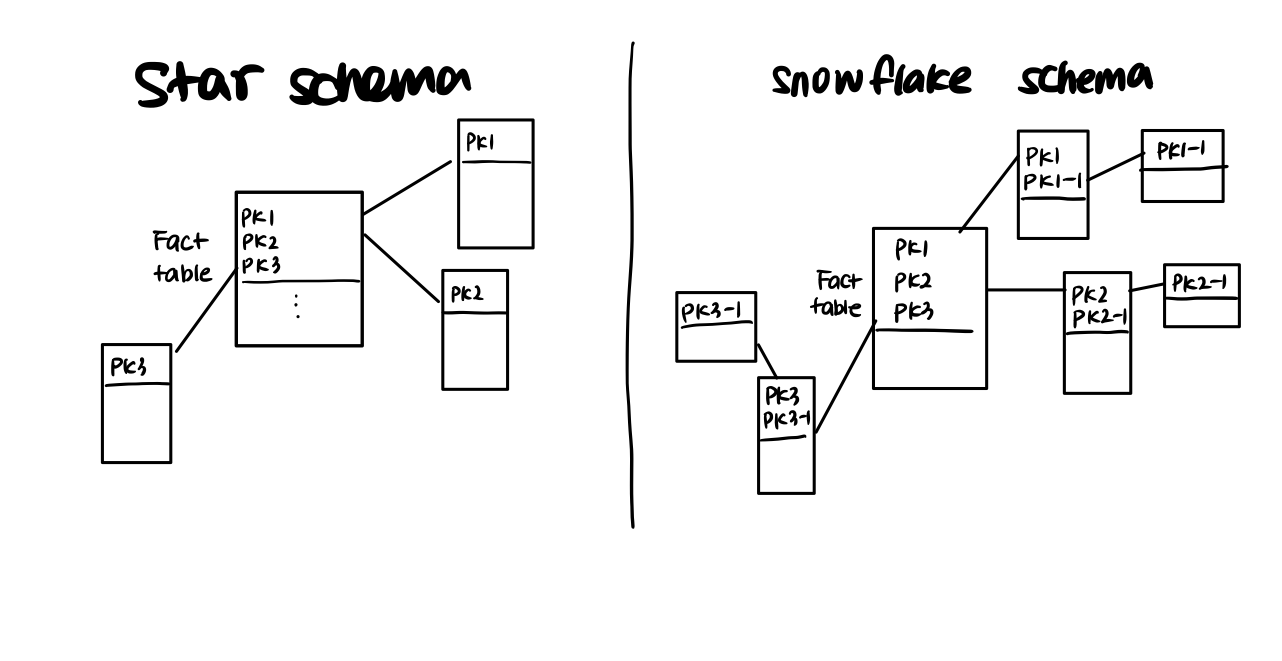
데이터 마트랑 웨어하우스의 차이점에 대해서 알아보자ODS를 통해 정제된 데이터가 분석과 보고서 생성을 위해 적재되는 데이터 저장소ODS에는 최신의, 소규모 데이터가 적재된다. 지속적으로 갱신되어 데이터베이스의 현재 상태를 반영하고, 모든 상태를 처리할 수 있게 설계된다
6.연계
짧은 경력이지만, 일을 하면서 업무 프로세스 상 아무리 단순한 비즈니스 모델이라도 각 단계별 연계가 중요한 영향을 미친다는 것을 체감하고 있다. 그런 의미에서 각 범위별 연계의 특징 및 중요한 점을 알아보자기준이 애매해 보일 수 있지만 애플리케이션과 서비스가 차이점의
7.대용량 비정형 데이터 처리방법 : 하둡
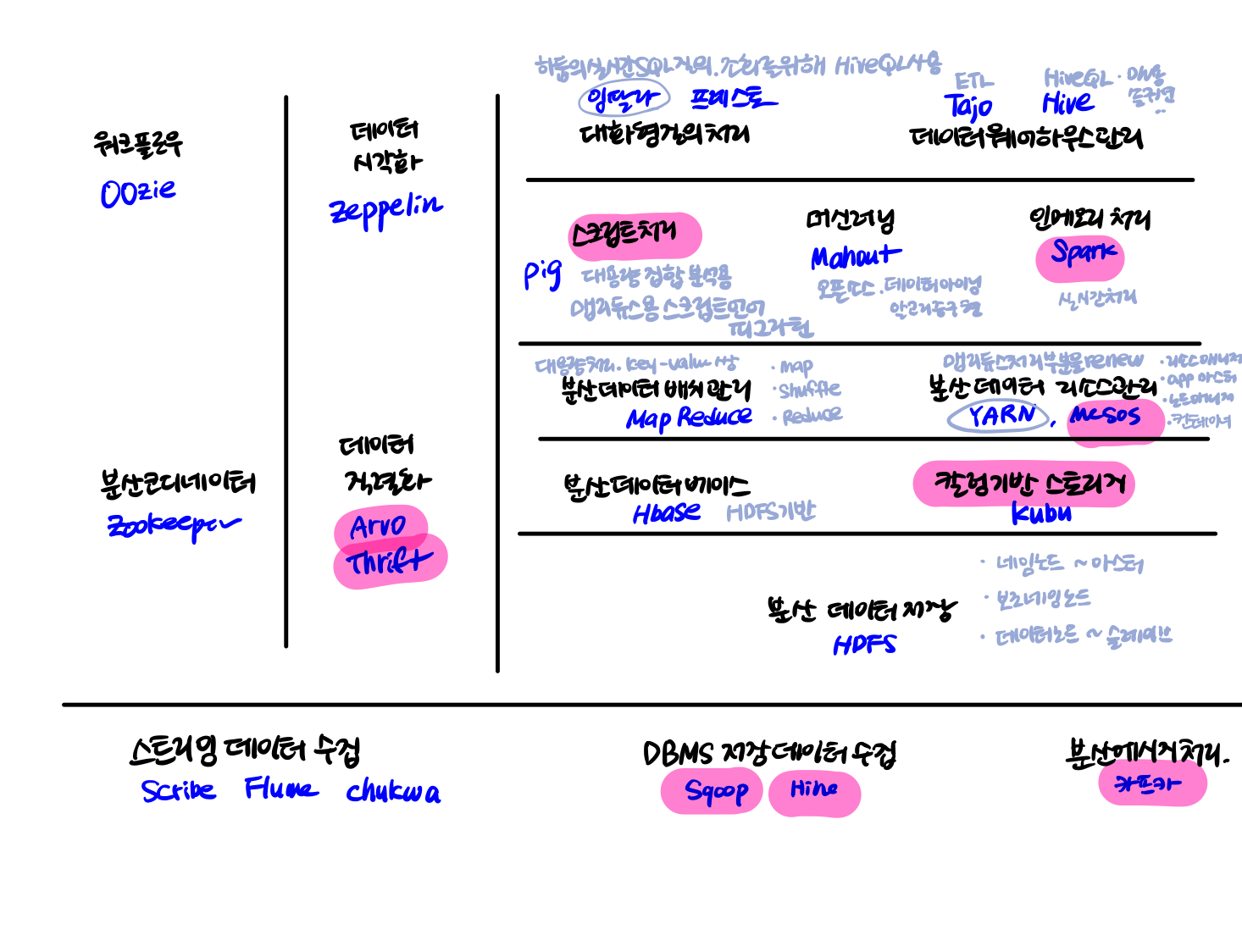
대용량 로그 데이터 수집 로그 데이터 수집 시스템의 예 : 아파치 flume-ng, 페이스북 scribe, 아파치 chukwa 특징 초고속 수집 성능과 확장성 : 실시간, 수집대상서버가 증가하면 증가량을 따라잡을수 있어야 함 데이터 전송 보장 메커니즘 : 수집
8.분산 데이터 저장기술 - 클러스터
분산 데이터 저장 기술은 1. 분산파일시스템, 2. 클러스터, 3. 데이터베이스, 4. NoSQL로 구분된다. 각각의 기술 모두 알아야 할 게 많은 덩어리다. 어떤 기술이던간에 분산된 데이터를 저장하는 기술은 대용량의 저장공간, 빠른 처리성능, 확장성, 신뢰성, 가용
9.분산 데이터 저장 기술 - 분산파일시스템

분산 데이터 저장 기술은 1. 분산파일시스템, 2. 클러스터, 3. 데이터베이스, 4. NoSQL로 구분된다. 각각의 기술 모두 알아야 할 게 많은 덩어리다. 어떤 기술이던간에 분산된 데이터를 저장하는 기술은 대용량의 저장공간, 빠른 처리성능, 확장성, 신뢰성, 가용
10.분산 데이터 저장 기술 - NoSQL
분산 데이터 저장 기술은 1. 분산파일시스템, 2. 클러스터, 3. 데이터베이스, 4. NoSQL로 구분된다. 각각의 기술 모두 알아야 할 게 많은 덩어리다. 어떤 기술이던간에 분산된 데이터를 저장하는 기술은 대용량의 저장공간, 빠른 처리성능, 확장성, 신뢰성, 가용
11.실험계획법 DOE
시스템, 프로세스에 영향을 미치는 인자를 도출하고 데이터를 통계적으로 분석하기 위해, 실험방식, 데이터 수집 방법, 활용 통계 기법 등 실험의 모든 과정을 설계하는 방법론이다. 최소 실험 횟수로 최대의 정보를 얻는 것을 목적으로 한다. 분산 분석 및 검정과 추정의 문제
12.서술형대비 - EDA
ADP 서술형 문제 유형 1번 데이터와 기초 통계 정보를 주고 분석 방법 및 인사이트 도출 방식을 서술하라고 하는 것. 예시 ) 붓꽃의 종류를 분류하기 위한 방법을 제시하시오. 결과물로부터 얻을 수 있는 인사이트를 예시를 사용해 설명하시오 그래서 유형별 순서대로 포
13.서술형대비 - EDA 2
통계분석방법론 1. 상관분석 2. t-test 2-1) 일표본 t-검정 단일 모집단에서 관심있는 연속형 변수의 평균값을 특정 기준값과 비교하고자 할때 사용한다. 예) 서울시민의 평균 키는 170cm 이다. 요건 모집단이 정규분포를 이룬다는 가정 종속변수는 연속형일것
14.서술형대비 - EDA3
기초통계분석 통계분석방법론 1. 상관분석 2. ttest 3. ANOVA
15.서술형대비 - EDA4
범주형 자료 두개의 관계를 알아보기 위해 진행한다.적합도 검정, 독립성 검정, 동질성 검정에 사용되고 카이제곱 통계량을 이용한다. 실험에서 얻은 결과가 예상한 이론과 일치하는지 아닌지를 검정한다. 즉 모집단 분포에 대한 가정이 옳은지 관측 자료와 비교하여 검정하는 것.
16.시계열분석
1. 시계열 자료의 특징 정상성 모든 시점에 대해 일정한 평균을 가진다. 평균이 일정하지 않은 경우 차분한다 모든 시점에 대해 일정한 분산을 가진다. 분산이 일정하지 않은 경우 변환한다 공분산도 특정 시점에만 의존하지 않는
17.비정형 데이터 마이닝
1. 텍스트 마이닝 기능 문서분류 : 주제별로 문서의 내용에 따라 분류하는것. 사전에 주제를 아는 경우 문서군집 : 성격이 비슷한 문서끼리 같은 군집으로. 사전에 분류정보를 모르는경우 정보추출 : 문서에서 중요한 의미를 지닌 정보를 추출 과정 1. 텍스트 수집 2.
18.ADP 32회 후기
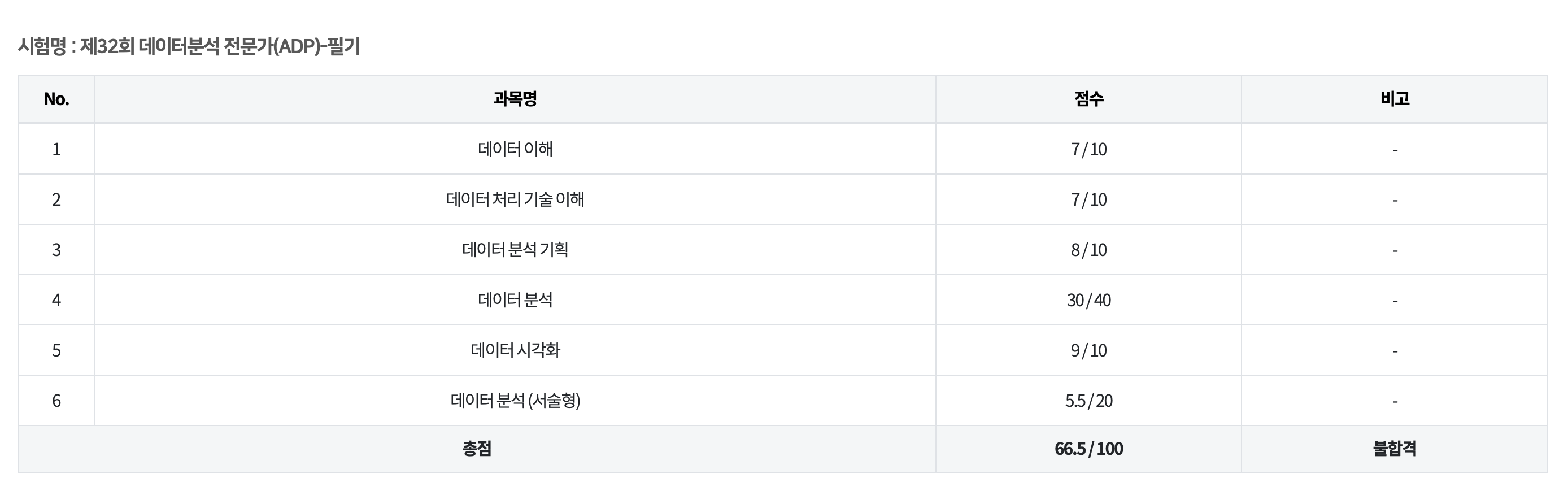
열받앙.... 서술형만 조금 더 맞았어도!!!식좀 외우고 갈걸.