
소프트콘 뷰어쉽, 대한민국 인터넷 방송을 한눈에!
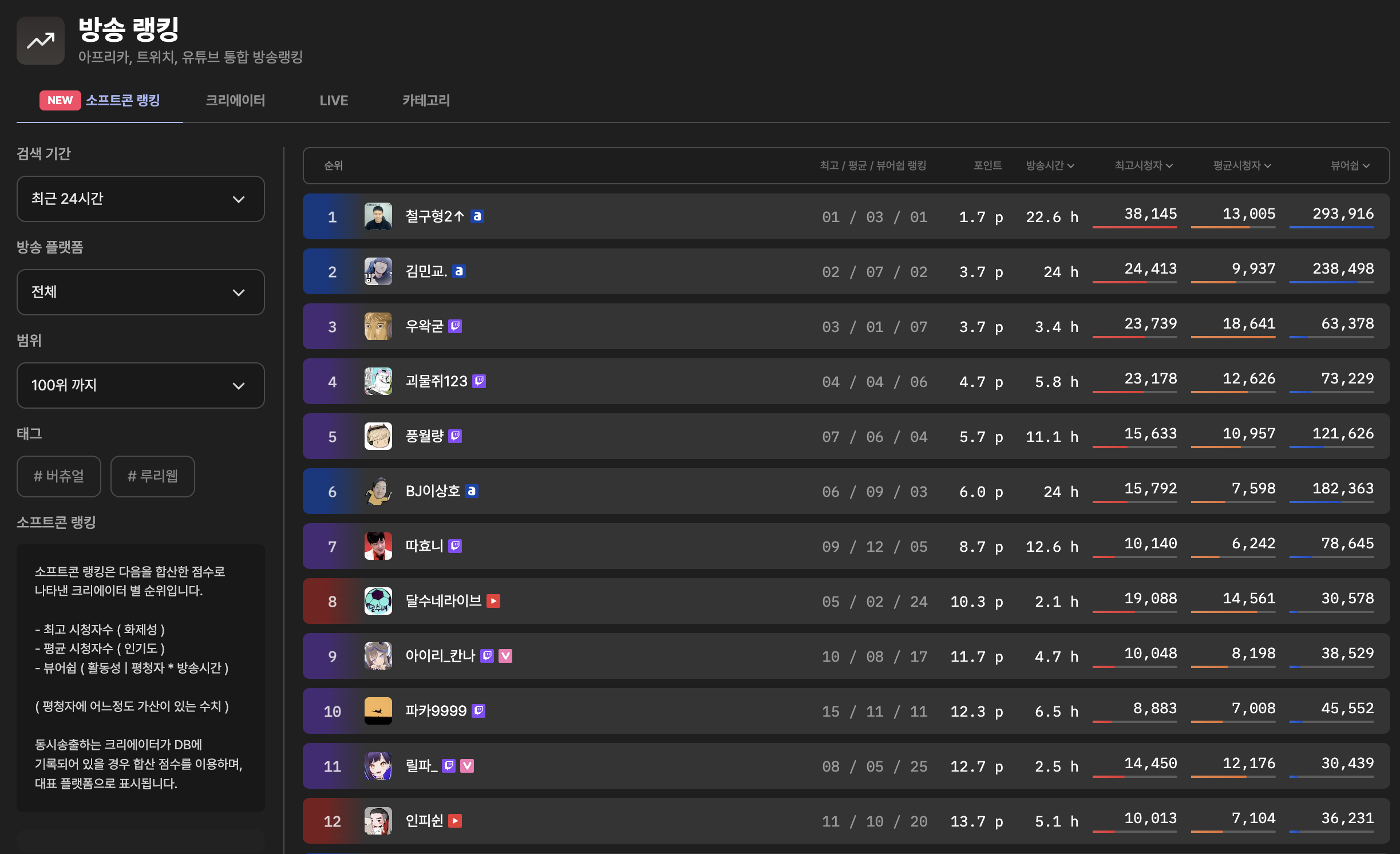
https://viewership.softc.one
소프트콘 뷰어쉽은 아프리카, 트위치, 유튜브(일부) 에서 방송중인 크리에이터들의 정보를 실시간으로 수집하여 해당 크리에이터의 데이터 및 순위를 보여주는 뷰어쉽 어플리케이션입니다.
제공해주는 정보는 아프리카 + 트위치 + 유튜브 통합 방송 랭킹, 뷰어쉽 순위 및 크리에이터 별 상세 방송 데이터 등 입니다. 이런 데이터를 바탕으로 광고주, 크리에이터, 시청자 모두가 만족할만한 정보를 확인할수 있게 하는것이 이 사이트의 궁극적인 목표입니다.
요약하자면,
- 트위치+아프리카+유튜브 랭킹 ( 갈드컵 유발용 X )
- 광고주 및 객관적인 데이터 확인
- 버튜버등 특정 태그로 나누어 확인 가능
( 이제 태그 기능도 추가되었습니다! )
이렇게 되겠습니다.
저번 연재에 이어 이번엔 문제 해결 과정에 대한 내용입니다.
저번편 요약

카페에서 개발하고 있었는데
갑자기 클템님이 나오시더니
계속 서버 따운! DB 따운! 개발자 나와! 거리면서 돌아다시더라
무서워서 인사 안하고 집에 옴..
문제 해결
일단 펨코에서 짤린건 차치하고, 멈춰버린 DB 부터 확인해야 했습니다.
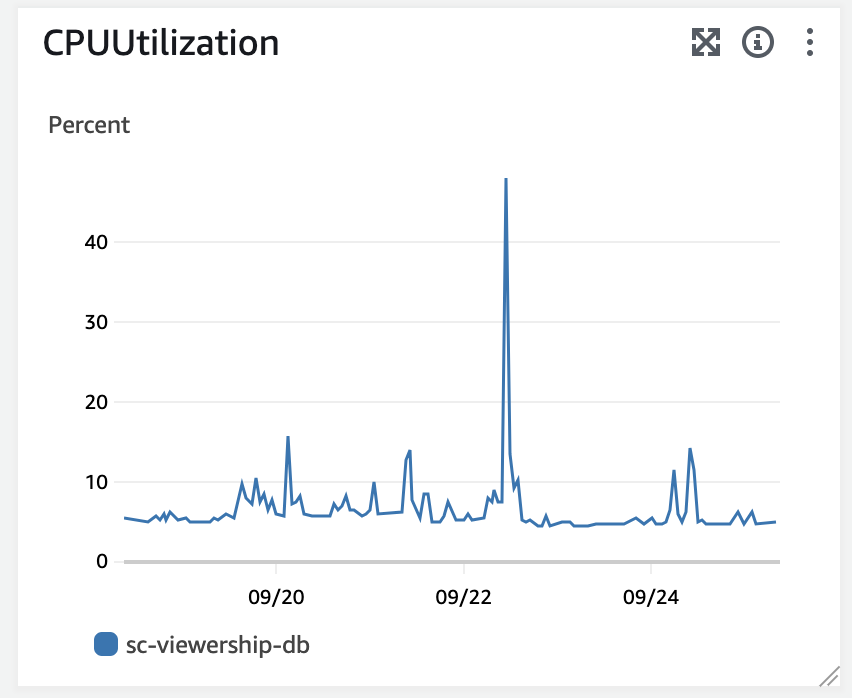
CPU 부하가 100%를 찍어버렸고, DBeaver를 통해 DB를 접속하려 해도 DB 자체가 접속이 되질 않고 있었습니다. ec2에 들어가 빠르게 로그를 확인해보니 connection pooling error 라는 문구와 함께 계속 오류가 발생되고 있더라구요.
일단 RDS에서 재시작을 눌러 재부팅을 했고 기존 free tier로 사용하고 있었던 t4g.micro 인스턴스 역시 t4g.medium 까지 스케일 업을 진행했습니다.
돈이 좀 나가겠지만 지금은 그런걸 신경쓸 상태는 아니였죠.
다행히도 펨코에서 글이 짤리고 계정지 영구정지가 된 이후로는 접속자수가 점점 줄어 서버도 안정화되기 시작했습니다. 이제부터 문제해결을 시작해 봐야합니다.
왜 발생했는가?
당일 순간 최대 100+, 1시간 최대 300+ ( 구글 애널리틱스, vercel 애널리틱스 )
CPU 부하 100%, RDS 정지
당시 상태를 확인해봅시다.
- EC2 : 멀쩡, 아무 문제 없었음
- vercel : 진짜 아무 문제 없었음
- RDS : ( 죽어서 말도 못함 )
일단 명백하게 RDS ( DB ) 에서 문제가 발생했습니다.
특히 connection pooling 이라는 단어와 함께 죽었다는 것이 핵심이였는데요. 이 문제의 본질을 알아보려면 먼저 서버 구조를 다시한번 확인해 봐야합니다.
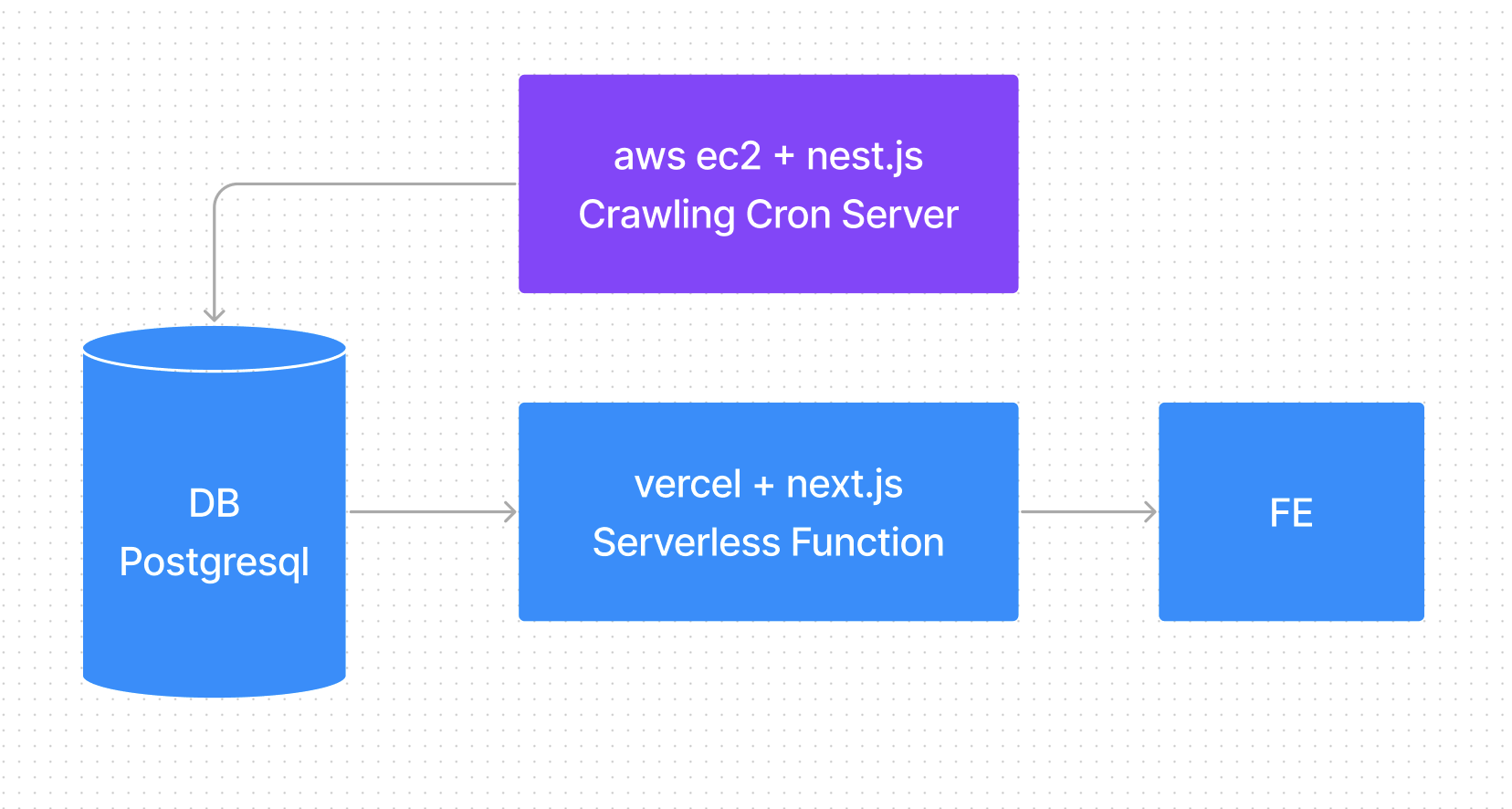
처음 서버개발을 하다보니 크게 간과한것이 있었는데, DB로 접속하는 서버의 역할이 단순히 라우팅과 데이터 정합만 존재하는것이 아니였다는 점이였습니다. 바로 부하를 관리하는 역할도 서버에서 담당하고 있었던 것이죠.
기본적으로 DB는 많은 연결을 받도록 만들어지지 않습니다. DB의 역할은 데이터베이스를 저장하고 관리하는 기능에 초점이 맞추어져 있죠. 그렇기에 한번에 많은 연결이 들어오게 된다면 connection pooling error가 발생하게 됩니다.
서버와 DB의 무지랭이였던 저는 아예 예상하지 못했던 에러죠.
만약, 서버가 존재하는 일반적인 환경이였다면 서버에서 DB로 가는 연결고리는 1개였고 서버에서 순차적으로 데이터를 처리해 문제가 없었겠지만 Serverless Function 구조의 현재 환경에서는 접속 횟수 만큼의 커넥션이 발생하기 시작했던 것이죠.
t4g.micro 커넥션
제가 사용하고 있는 RDS는 t4g.micro 였습니다.
2 vCPU와 2GB의 RAM을 이용하는 굉장히 작은 서버였죠.
근데 좀 이상합니다. t4g.micro의 max_connection 자체는 적어도 50은 넘어갈텐데 겨우 70명이 들어왔다고 DB가 터지다뇨?
맞습니다. connection pool의 적정 갯수는 CPU, RAM, SSD 등 여러 요소를 고려해 병목이 없는 숫자를 찾아야 하는것이 가장 중요했던 것이죠.
이와 관련하여 유명한 ORM Client인 Prisma는 다음과 같은 수치를 제안하고 있습니다.
https://www.prisma.io/docs/guides/performance-and-optimization/connection-management

기본적인 커넥션 사이즈는 다음의 공식을 이용합니다.
물리적 CPU * 2 + 1
그리고 더 읽어보니 Serverless Function과 관련된 이야기도 있더라구요.
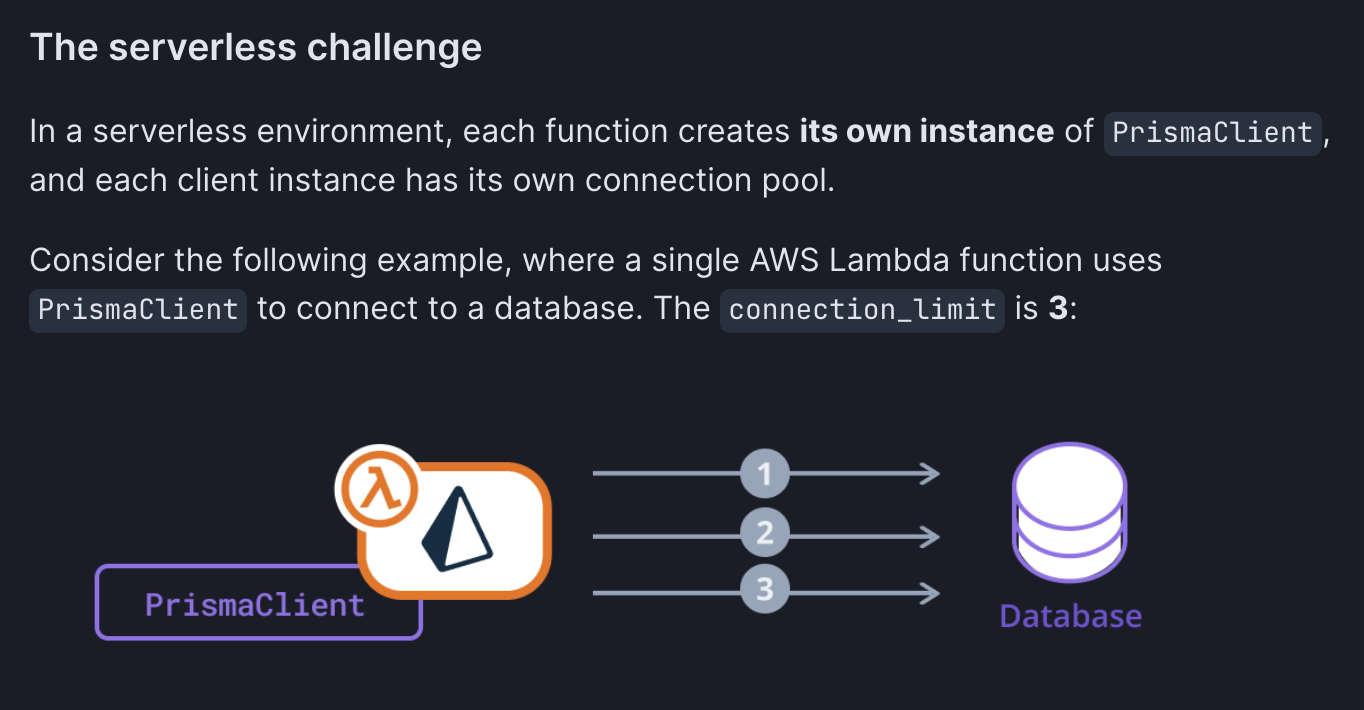
서버리스 과제
서버리스 환경에서는 각 함수의 실행 시도가 하나의 프리즈마 클라이언트의 인스턴스가 됩니다. 그리고 각각 클라이언트는 각각의 커넥션 풀을 가지게 됩니다.
t4g.micro에 권장되는 커넥션 풀은 결국 3.
3개 이상의 커넥션 풀은 병목 현상이 발생될 수 있다는 이야기였죠.
이 상황에서 순간적으로 100+의 커넥션 풀링이 발생했을텐데 버티지 못한것이 당연했습니다.
하지만 Serverless Function은 이 커넥션 풀링을 막을수가 없습니다. 하나의 함수가 다른 함수가 작동중인지 아닌지는 알수 있는 방법이 없었으니까요.
이 문제를 해결하기 위한 방법은 2가지였습니다.
- DB 사이에 Connection Pool 을 관리해주는 미들서버를 두기
- nest.js 서버로 전환
각각의 득실을 살펴봅시다.
DB 사이에 무언가를 넣어보자 Connection Pooler
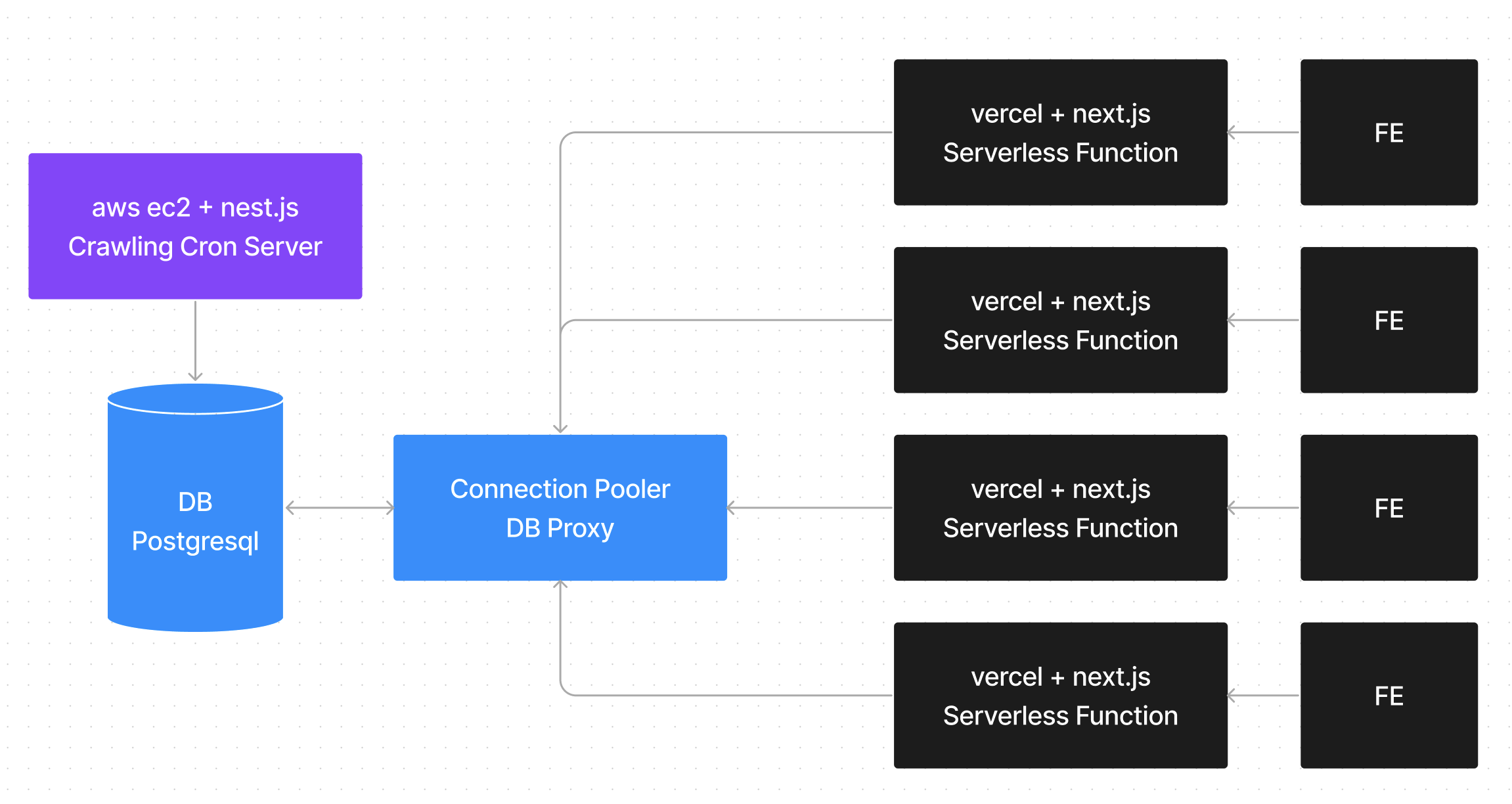
Connection Pooler는 DB와 Serverless Function 사이에서 들어오는 커넥션을 관리해주는 역할을 합니다. 이 역할만을 담당하는 pgBouncer, RDS Proxy와 좀더 확장하여 캐싱된 데이터를 통해 풀링을 관리하는 Prisma Accelate 등이 존재하고 있습니다.
일단, 현재 서비스 자체가 RDS를 이용하고 있기에 pgBouncer는 이용이 불가능했고 RDS Proxy는 AWS 내부에서만 사용이 가능하기 때문에 vercel을 이용하고 있던 저는 사용이 불가능했습니다.
Prisma Accelate가 유일한 대안이였고 실제로 이 서비스를 이용해 보기 위해 몇가지 실험을 해봤습니다.

분명 최대 1000배는 빨라야겠지만, 제가 확인했던 모든 API는 2~5배까지 느려졌습니다. connection pool이 아니라 timeout 에러가 발생하더라구요.
vercel edge도 사용해봤습니다만, 결과는 크게 달라지지 않았습니다. 이론적으로는 분명 빨라야겠지만 아직 서비스도 베타였고 과도기적인 환경이라 문제가 있었던것 같습니다.
결국 방법은 하나뿐이였습니다.
ec2로 이사갑니다!
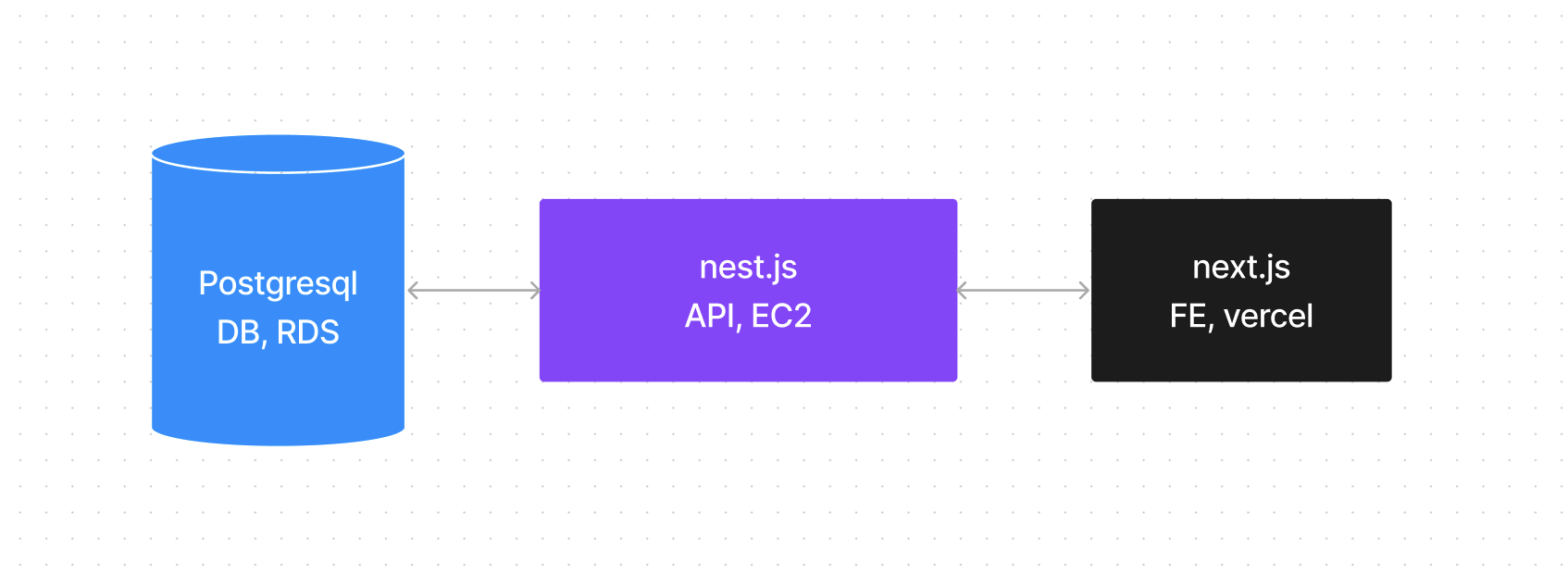
국밥이자 국룰이죠.
가장 깔끔하고 군더더기 없는 구조였습니다.
뭐 크게 부연설명할 것도 없이 FE + API + DB 가 한세트로 이뤄지는 모던 어플리케이션 개발의 가장 기본적인 구조로 수정했습니다.
Serverless Function으로 만들었던 모든 API를 들고와 nest.js로 옮겼고 다행히 기존에 쓰던 Prisma 코드는 그대로 이식하여 사용했습니다.
이 뿐만 아니라 DB도 확장 Scale Out 했습니다.
Read Replica, 읽기 전용 복제본
결국 DB에 병목현상이 생긴다면? 병렬적으로 DB를 추가로 만들어주면 되는것이였죠.
안정성이 2배! 돈도 2배!
읽기 전용 복제본을 만들어 nest.js에 추가로 넣어줬습니다.
좋았던 점은 Prsima 에서는 Readreplica 플러그인을 지원하는 점이였고, 안좋았던 점은 이걸 nest.js에 적용하는건 단순한 방법으로는 안되었다는 점이였죠.
// 기존 코드
import { Injectable, OnModuleInit } from '@nestjs/common';
import { PrismaClient } from '@prisma/client';
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$connect();
}
}
일반적으로 Prisma를 nest.js에 쓰는 방법은 다음과 같습니다.
현재 onModuleInit 부분이 모듈이 처음 생성될때니까, 여기에 extends를 넣어 플러그인을 넣어주면 되겠네요!
그렇죠?
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$extends(
readReplicas({
url: [process.env.DATABASE_URL, process.env.DATABASE_URL_REPLICA],
}),
).$connect();
}
}
안됩니다. ❌
분명 onModuleInit으로 최초 실행시 this에 같이 넣어서 $connect()를 해주면 될것 같았지만 실제로는 아무것도 되지 않습니다.
디버거로 확인해봐도 extends한 readReplicas플러그인은 존재하지 않습니다.
그렇다면, this에 직접 할당해 버리면 어떨까요?
import { Injectable, OnModuleInit } from '@nestjs/common';
import { PrismaClient } from '@prisma/client';
import { readReplicas } from '@prisma/extension-read-replicas';
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$connect();
Object.assign(
this,
this.$extends(
readReplicas({
url: [process.env.DATABASE_URL, process.env.DATABASE_URL_REPLICA],
}),
),
);
}
}넵. 아예 extends해버린 this를 할당시켜 버리니 아주 잘 작동합니다. 혹시나 이부분으로 고생하시는 분들이 있다면 위와 같이 코드를 작성해보세요!
이렇게 해서 이제 서비스의 구조는 다음과 같아졌습니다.
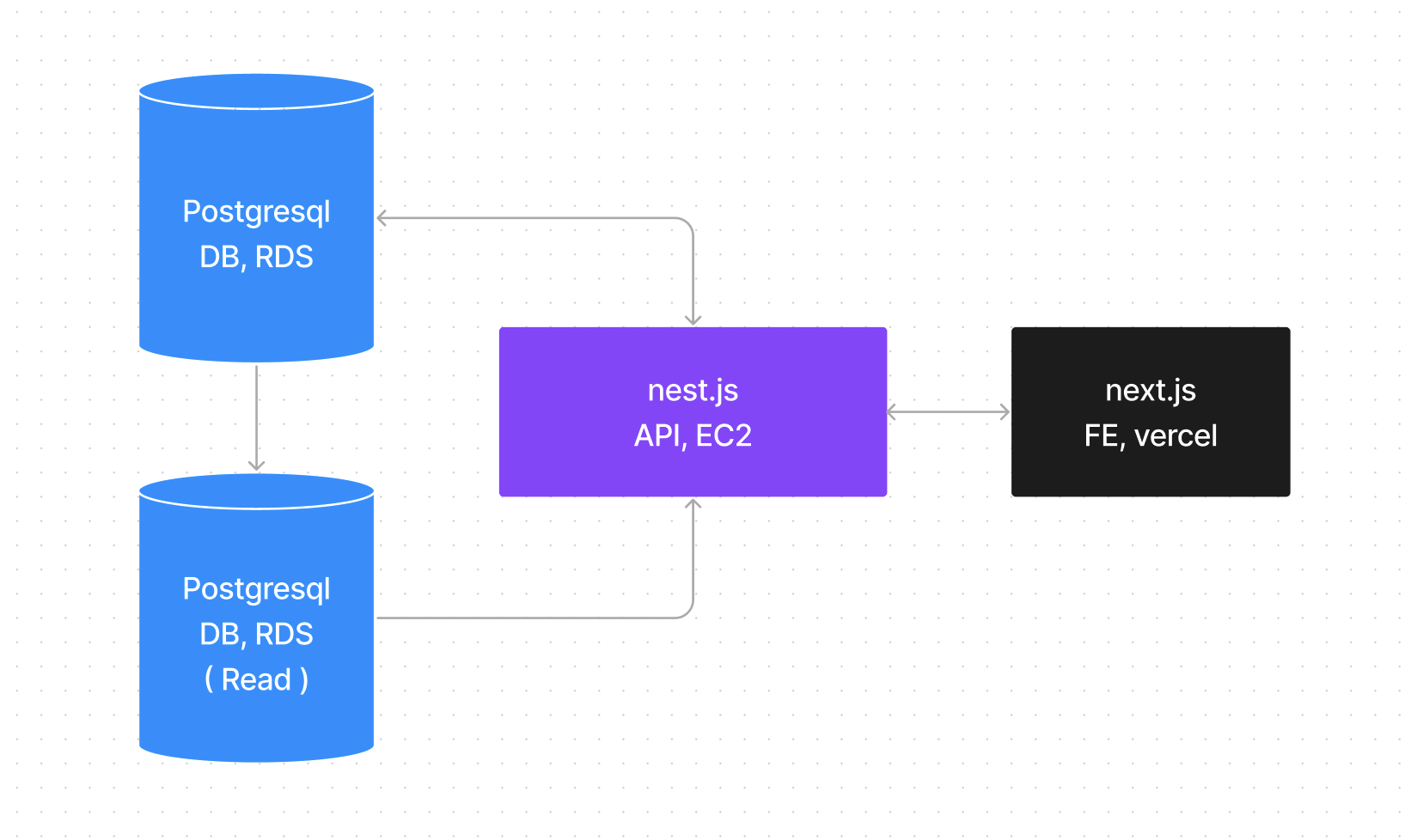
t4g.micro에서t4g.medium으로Scale Up,Read Replica로Scale Out- 들어가는 돈은
(2+a)n 배
그래도 서비스 자체는 안정적으로 변했으니까요..
하지만 아직 한발 더 남았습니다. Next.js 13의 Data Cache도 도입할 예정이거든요.
Data Cache를 이용한 Data Feching
ISR 방식의 App Router식 표기입니다.
간단하게 데이터를 가져오고, 가져온 데이터를 통해 만들어진 페이지를 캐싱하여 사용자들에게 보여준다는 것이죠.
Next.js 의 기존 Page Router에서는 revalidate값을 이용하여 ISR 즉, 필요할때 페이지 생성하는 방식 으로 다뤘었지만 App Router에서는 아무런 설정이 없다면 기본적으로 설정되는 방식입니다. 오히려 추가 설정을 통해 SSR 즉, 요청할때마다 페이지 생성하는 방식 으로 변경이 가능해졌죠.
일단 이 사이트의 크롤링을 확인해봅시다.
트위치, 아프리카, 유튜브 수집
6분마다 수집중
데이터는 6분마다 수집중입니다. 이 이야기는 6분 사이에 들어온 동일한 요청이 있다면 변경될 일이 전혀 없다는 이야기이죠. 그렇다면 Data Cache를 이용하며 매 6분동안 데이터를 캐싱하게 해둘 수 있지 않을까요?
설계도를 그려보자
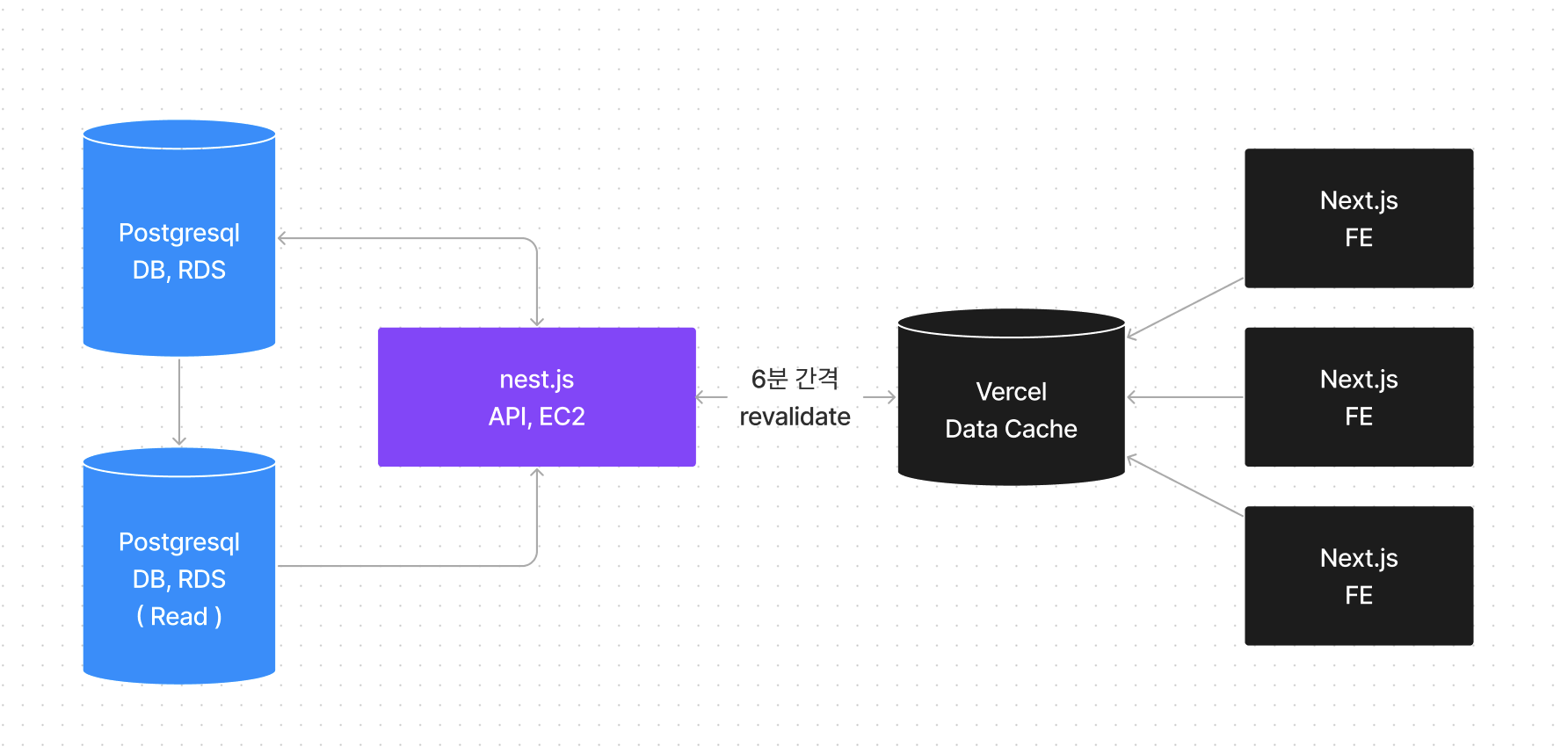
오호?
Serverless Function을 도입하려고 했던 때랑 비슷하지만 이번엔 그 캐싱 데이터가 Frontend 쪽에 있습니다.
그렇다는 이야기는 훨씬 더 안정적이라는 이야기가 되겠죠.
하지만, 이런 구조는 Vercel의 Serverless Function의 일종이기 때문에 필연적으로 발생하는 문제인 Cold Boot 초기 구동시간이 발생합니다.
제가 만든 사이트의 경우 한 페이지에 불러오는 API가 평균 4~5개 정도로 로딩 시간이 약 2~3초 정도 걸리기에 캐싱되기 전 접속하는 사용자는 Cold Boot 문제를 겪고 사용자 경험이 저하될 수 있습니다.
기존 Page Router에서는 이 문제에 대한 해결방법이 딱히 없었습니다.
하지만 App Router에서 획기적인 방법이 등장합니다.
React Streaming
기존과 달리 App Router 에서는 모든 데이터가 준비되어질때 까지 렌더링을 차단하는 Waterfall 방식의 접근이 아닌 필요한 부분에 맞춰 데이터를 순차적으로 접근할 수 있게 되었습니다.
또한 이런 기다리는 과정에서 <Suspense> 컴포넌트를 이용하면 스켈레톤 UI를 구축하여 사용자 경험을 더욱 끌어 올릴수 있는 좋은 방법이 되었다는 것이죠!
현재 이 부분은 사이트의 전반적인 부분에 구축되어 있습니다.
https://viewership.softc.one/ranking
놀랍게도 방송 랭킹과 같이 CSR로 구현되었을것 같은 부분도 전부 Data Cache을 통해 사용자들에게 전달되어지고 있죠.
혹시 App Router의 진입장벽으로 고민하고 계신분들이 있다면, 저는 적극적으로 추천해드리겠습니다!
기존 Server Side Rendering의 고질적인 문제도 개선되고 Serverles Function의 Cold Boot문제 역시 다양한 개선 방법을 제공해주고 있습니다.
근데 비용은?
현재 가장 걱정되는 부분입니다.
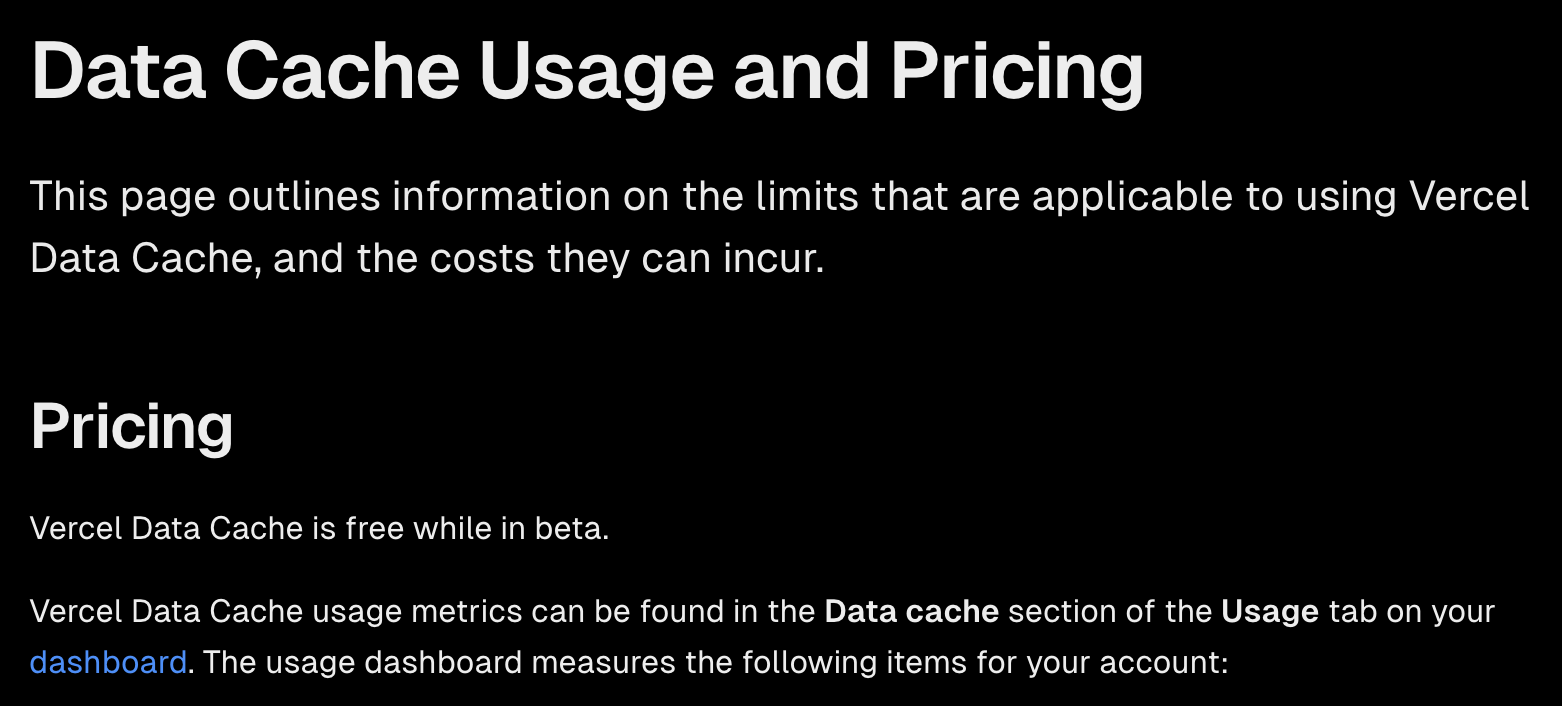
아직은.. 무료긴 한데요.
beta 기간에만 무료인거라 어떻게 될지는 더 지켜봐야 할것 같습니다.
현재 Pro 플랜을 사용하고 있는 입장이라 유료로 전환되었을때 비용을 얼마나 더 받을지, 현재 플랜 내에서 처리가 가능할지 등 다양하게 따져봐야 할것 같습니다.
하지만 무료로 사용할수 있는 현재 기준으로 해당 서비스는 적극적으로 추천드릴수 있을것 같네요!
이후 실적
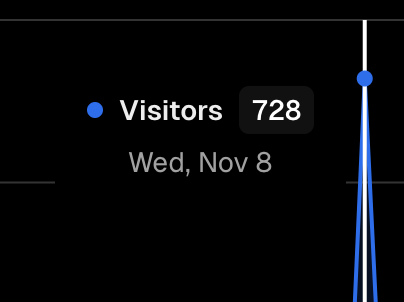
다음과 같이 전환한 후 최근 디시인사이드와 펨코에서 저번 피크치를 뛰어넘는 새로운 유입이 있었습니다.
당일 순간 100+, 30분 최대 100+ ( 구글 애널리틱스, vercel 애널리틱스 )
하루 700+
이 사이 저는 매달 20만원 가까이 나가는 여러 개발비용을 줄이고자 기존 Scale Out 했던 DB를 다시 단일 DB로 돌리고 DB 내부의 최적화 작업을 진행했었습니다.
가장 큰 작업은 기존 Date의 indexing 방식을 BRIN으로 변경했던 점인데요, 제가 만드는 log형 DB에서는 극단적인 효율 향상을 기대할 수 있는 indexing 방법이라 최대 3~5배까지 효율 향상을 확인했습니다.
그리고, 극단적인 유입이 한번더 닥쳐왔던 그날.
RDS는 어땠을까요?
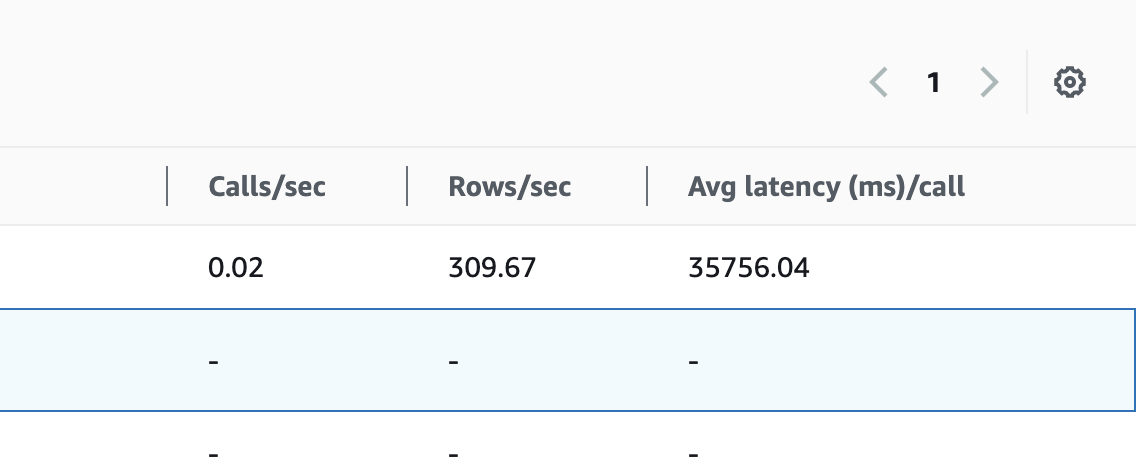
최악의 쿼리가 35초가 소모되었지만, 비용 절감 + 효율 향상의 시너지와 함께 다행히도 RDS가 종료되는 일은 발생하지 않았습니다.
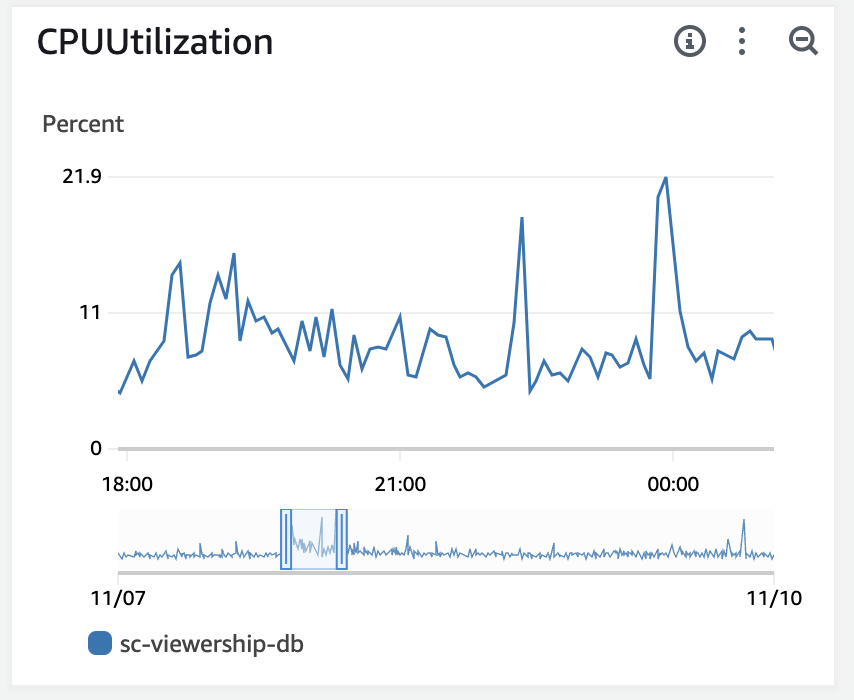
당시 CPU 사용율 역시 20% 대로 안정적이였고 극한의 트래픽 상황 이후 RDS와 vercel 모두 안정적인 지표를 보여주고 있었습니다. 이 역시 Data Cache가 이뤄진 이후 데이터는 만들어진 페이지만 보내줄 뿐이기 때문이죠.
이제 사이트의 큰 문제는 개선했습니다.
하지만 홍보적인 측면에서는 아직 위기가 끝나지 않았습니다.
펨코라는 대형 커뮤니티에서 영정을 당하고 이제 어떻게 사이트를 알릴수 있을까 고민을 하기 시작합니다.
불은 끄고 집은 재건했지만,
들어올 사람이 없는 상황.
이제 온몸을 비틀어서라도 뭔가 뭔가 해야합니다!
( 다음화에 계속 )

6개의 댓글

맥락을 놓친 게 어차피 next app router 로 페이지를 6분마다 revalidate 하고 있다면 vercel data cache 는 왜 필요했던 건가요? 전부 ISR 해버리면 안 되는 상황이었나요?
서버 따운! 개발자 나와!!