1. Read-Through 전략이란?
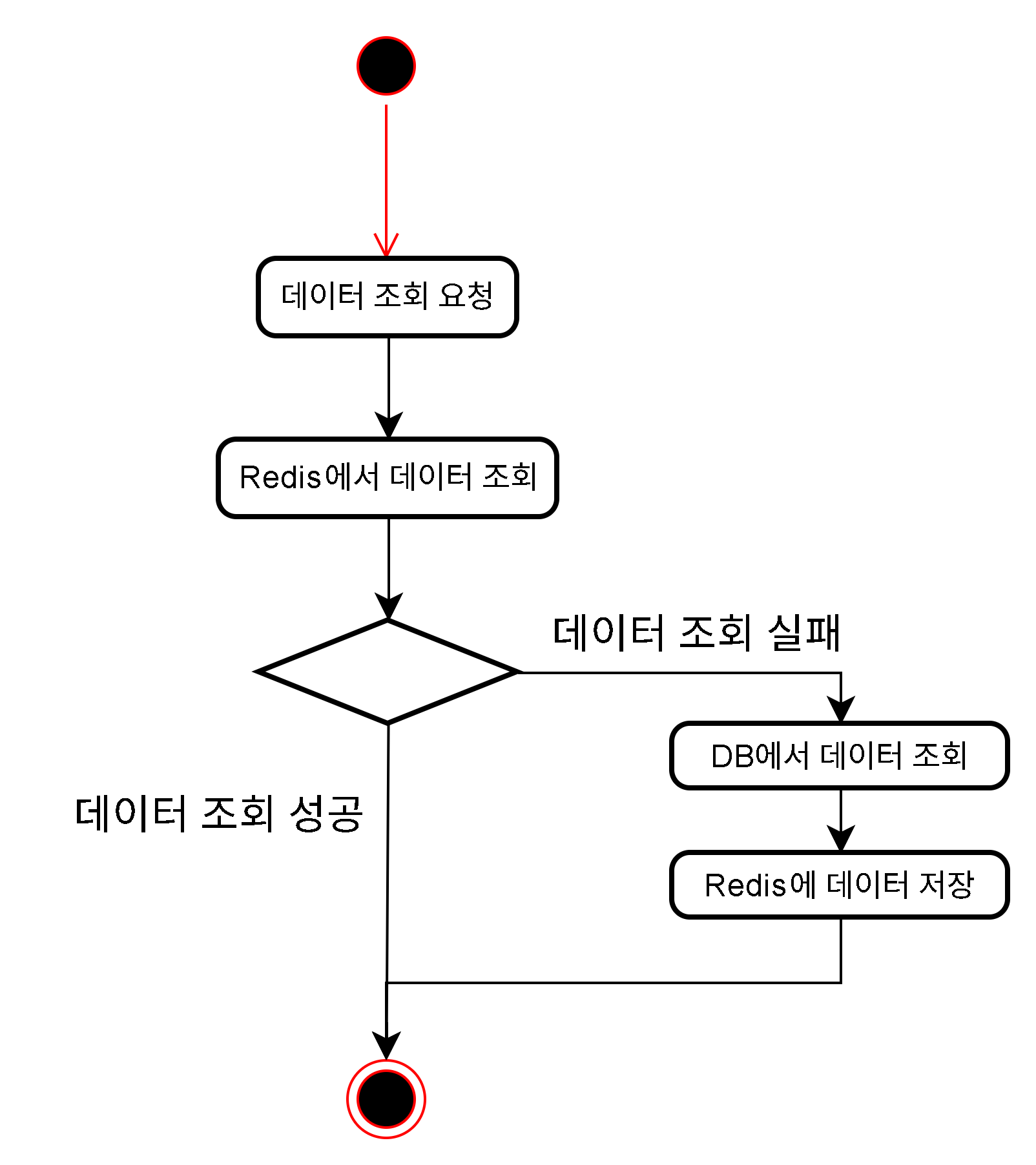
Read-Through는 애플리케이션이 캐시에게만 데이터를 요청하고 만약 데이터가 없다면(Cache Miss) 캐시가 직접 DB에서 데이터를 읽어와 스스로를 업데이트한 뒤 애플리케이션에 반환하는 방식이다.
Cache-Aside와의 차이점
- Cache-Aside: 애플리케이션이 주도적이다 → 데이터가 없으니 애플리케이션이 직접 DB에서 가져와서 캐싱한다.
- Read-Through: 애플리케이션은 캐시만 바라본다 → 데이터가 없으면 캐시가 DB 가서 가져와서 나한테 줘
2. Spring Cache에서의 Read-Through
엄밀히 말해서 Redis는 DB와 직접 통신하는 기능이 없다. 하지만 Spring Cache 추상화(@Cacheable)를 사용하면 라이브러리가 내부적으로 이 과정을 처리해주기 때문에 개발자는 Read-Through처럼 동작하는 코드를 짤 수 있다.
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
/**
* Read-Through 스타일의 접근
* 애플리케이션 로직은 DB 접근 코드를 모르고,
* @Cacheable 프레임워크가 중간에서 데이터 로드와 캐싱을 전담함.
*/
@Cacheable(value = "products", key = "#id")
public Product getProduct(Long id) {
// 이 내부 로직은 Cache Miss가 발생했을 때만 실행됨
// 캐시 제공자(Spring + Redis)가 이 결과를 가져가서 캐시에 저장함
return productRepository.findById(id)
.orElseThrow(() -> new RuntimeException("Product not found"));
}
}3. Read-Through의 장단점
| 장점 | 단점 |
|---|---|
| 데이터 모델의 단순화: 애플리케이션 코드가 DB 조회 로직과 캐시 저장 로직을 분리할 수 있어 깔끔해집니다. | 의존성 강화: 캐시 라이브러리나 미들웨어 설정에 크게 의존하게 됩니다. |
| 데이터 정합성: 캐시와 DB의 데이터가 항상 일치하도록 라이브러리 수준에서 관리하기 유리합니다. | 유연성 부족: 캐시에 저장될 데이터의 형태를 세밀하게 조정하기 어려울 수 있습니다. |
4. 백엔드 개발자가 알아야할 것: Inline Cache
실제로 Redis 같은 독립된 캐시 서버를 쓸 때는 애플리케이션이 라이브러리를 통해 Read-Through를 흉내내는 경우가 많다. 반면 Nginx의 캐시나 특정 DB 엔진 내부의 캐시는 진정한 의미의 Read-Through(Inline Cache)로 동작한다.
주의할 점: 데이터 동기화
Read-Through는 읽기 성능은 좋지만 “DB에 데이터가 바뀌었을 때 캐시는 이를 어떻게 감지하는가?”라는 문제가 있다. 이를 해결하기 위해 Write-Through(쓰기 전략)와 같이 사용하는 것이 일반적이다.

백엔드 개발자를 목표로 공부하는 대학생