2️⃣✅ Multinomial classification
🔅 데이터 로드하기
import torch
import torch.optim as optim
import numpy as np
import pandas as pd
torch.manual_seed(1)
x_train = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_train = [2, 2, 2, 1, 1, 1, 0, 0]
x_train = torch.FloatTensor(x_train)
y_train = torch.LongTensor(y_train)
print(x_train[:5])
print(y_train[:5]) 일반적으로 Int형 숫자를 사용할 때는 LongTensor 사용한다.
일반적으로 Int형 숫자를 사용할 때는 LongTensor 사용한다.
🔅 원핫인코딩 자세히 살펴보기
nb_class = 3
nb_data = len(y_train)
y_one_hot = torch.zeros(nb_data,nb_class)
y_one_hot.scatter_(1, y_train.unsqueeze(1), 1)
print(y_one_hot)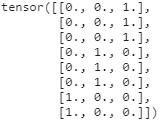 현재 y_train을 살펴보면 0,1,2로 이루어져 있다. 하지만, 우리는 이를 onehot encoding으로 형태를 바꿔준다.
현재 y_train을 살펴보면 0,1,2로 이루어져 있다. 하지만, 우리는 이를 onehot encoding으로 형태를 바꿔준다.
총 클래스의 개수는 0,1,2로 3개이기 때문에 nb_class = 3
.scatter_(dim,index,src): (1)dim: 차원축 (2) index: 위치 (3) src: scatter할 값
즉 위의 식을 생각하면 축 1(열)을 따라서, 배열 내 index에 해당하는 곳에 1을 넣으라는 것이다.
따라서 y_train에서 0에 해당하면 [1,0,0], 1에 해당하면 [0,1,0], 2에 해당하면 [0,0,1]이 되는 것이다.
또한, scatter과 scatter의 차이는 inplace의 차이. scatter은 inplace=True이기 때문에 바로 y_one_hot 배열이 바뀜
🔅 데이터 학습
#for softmax
import torch.nn.functional as F
#모델 초기화
#feature = 4, class = 3
nb_class = 3
nb_data = len(y_train)
W = torch.zeros([4,nb_class],requires_grad=True)
b = torch.zeros(1,requires_grad=True)
#optimizer 설정
optimizer = optim.SGD([W,b],lr=0.01)
nb_epochs=1000
for epoch in range(nb_epochs+1):
#H(x)계산
hypothesis = F.softmax(x_train.matmul(W)+b,dim=1)
# cost 표현법 1번 예시
y_one_hot = torch.zeros(nb_data,nb_class)
y_one_hot.scatter_(1,y_train.unsqueeze(1),1)
cost = (y_one_hot * -torch.log(hypothesis)).sum(dim=1).mean()
# cost 표현법 2번 예시
# cross_entropy를 사용하면 scatter함수를 이용한 one_hot_encoding 안해도 됨
# cost = F.cross_entropy(hypothesis,y_train)
#cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
#100번마다 로그 출력
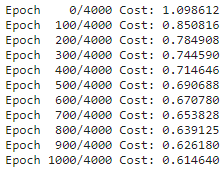
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, n_epochs, cost.item()
))
F.softmax: softmax 함수
F.cross_entropy: 직접 함수를 쓰지 않아도 적용할 수 있는 크로스엔트로피
torch.log: log함수
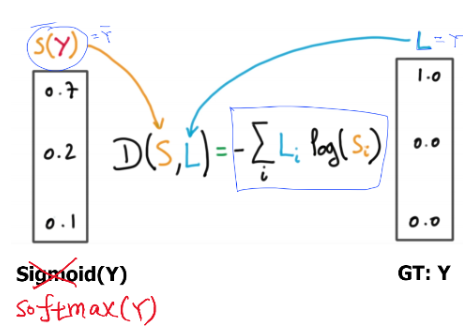
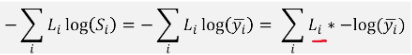
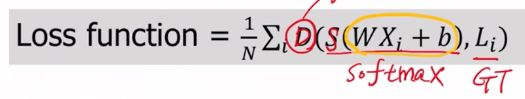 이론에서 배웠던 이것을 식으로 구현한 것
이론에서 배웠던 이것을 식으로 구현한 것
🔅 데이터 평가
# 학습된 W,b를 통한 클래스 예측
hypothesis = F.softmax(x_train.matmul(W)+b,dim=1)
predict = torch.argmax(hypothesis,dim=1) #index 반환print(hypothesis)
print(predict)
print(y_train) softmax를 통과한 hypothesis는 확률값이기 때문에 이를 argmax에 적용하여 가장 큰 값을 갖는 index만 반환하여야 한다.
softmax를 통과한 hypothesis는 확률값이기 때문에 이를 argmax에 적용하여 가장 큰 값을 갖는 index만 반환하여야 한다.
우리의 모델은 1개 틀린 것을 확인할 수 있다.
correct_prediction = predict.float() == y_train
print(correct_prediction)
accuarcy = correct_prediction.sum().item() /len(correct_prediction)
print('This model has an accuarcy of {:2.2f}% for the training set.'.format(accuarcy*100)) 모델의 정확도, 이미 binary classification에서 배웠던 거라 어렵지 않지
모델의 정확도, 이미 binary classification에서 배웠던 거라 어렵지 않지

정리된 글은 https://dusruddl2.tistory.com/로 이동