SJU_인공지능
1.[인공지능] 수업개요

2.[인공지능] 1주차 | 소프트웨어2.0, 생활 속 인공지능, (EBS다큐프라임) 우리아이 AI네이티브입니까

머신러닝이란? 기계가 배운다.딸기 주스를 만들려고 하는데 우리에게는 레시피가 없는 상태(방법은 모르고 결과만 아는 상태)결과를 만들기 위해 우리가 할 수 있을까?레시피를 알려주는 대신에 기계 스스로 학습할 수 있도록 하는 것만들어보고 - 에러측정하고 - 개선하고위와 같
3.[인공지능] 2주차 | 인공지능 개론 1부

2-1 인공지능 개론 1부AL,ML,DL이 무엇인지 정확히 알고, 기술 변화의 흐름을 공부해보자.AI가 가장 큰 개념, 그 안에 ML, 그 안에 DL인공지능은 최근에 나온 개념이 아니다 무려 1950년부터 있었던!인공지능의 하나의 솔루션인 '머신러닝'이 1980년대부터
4.[인공지능] 2주차 | 인공지능 개론 2부

추후 추가 예정
5.[인공지능] 2주차 | Teachable Machine

추후 추가 예정
6.[인공지능] 2주차 | Teachable Machine 개인 프로젝트
추후 추가 예정
7.[인공지능] 3주차(이론) | 선형회귀

기존 프로그래밍과 인공지능의 차이점을 알게 하는 것이 교수님의 목표 👩🏻🏫기존 프로그래밍) input, output이 정확하고 최적의 솔루션을 우리가 직접 찾는 것 (ex. 자료구조, 알고리즘)인공지능) 데이터와 task를 지정해주면, 최적의 솔루션을 기계가 찾
8.[인공지능] 3주차(실습) | 단일선형회귀

추후추가예정
9.[인공지능] 3주차(실습) | 비용 최소화하기 (Minimizing Cost)
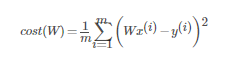
$H(x)$: 주어진 $x$값에 대해 예측을 어떻게 할 것인가 - 가설함수 (모델)$cost(W)$: $H(x)$가 $y$를 얼마나 잘 예측했는가 - 비용함수(비용)\*\* 주의 식을 간소화 하기 위해 가설함수에 편향변수 b를 추가히자 않았음.$H(x) = Wx$gra
10.[인공지능] 3주차(실습) | 다중선형회귀 (multivariate Linear Regression)

feature의 개수가 앞선 단일회귀문제에서는 1개였는데 3개로 늘었음설마 이렇게 하는 사람 없지? 당연히 Matrix이용해야지
11.[인공지능] 4주차 | 선형분류 (이론)

이 관계를 정확하게 이해해야 한다. Linear regression -> Logistic regression -> Binary classification -> multi class classification 다시 한번 linear regression에서 필요한 것이
12.[인공지능] 4주차(실습) | Binary Classification

x_data는 공부시간, 출석 횟수로 이루어져있고, y_data는 시험합격 = 1 & 시험불합격 = 0이다..item(): tensor 변수에서 값만 가져오기torch.sigmoid: sigmoid 함수 linear regression과 바뀐 H(x)와 cost를 위
13.[인공지능] 4주차 | Multinomial Classification (실습)
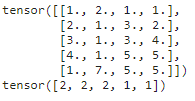
일반적으로 Int형 숫자를 사용할 때는 LongTensor 사용한다. 현재 y_train을 살펴보면 0,1,2로 이루어져 있다. 하지만, 우리는 이를 onehot encoding으로 형태를 바꿔준다.총 클래스의 개수는 0,1,2로 3개이기 때문에 nb_class = 3
14.[인공지능] 5주차(이론) | 다층 퍼셉트론(multi-layer perceptron MLP)

History of MLP 뉴런을 본따 인간의 뇌를 모사하는 것을 목표로 만들어진 인공신경망(NN)인공신경망(NN, Artificial neural network): 동물의 생물학적 뇌의 기본단위인 인간의 뉴런을 모방하여 모델링한 네트워크 뉴런이란?)각각의 채널마다 들
15.[인공지능] 5주차(이론) | 모델 학습 (Model Training)

• Learning rate• Data preprocessing• Avoid overfitting \- More training data \- Regularization• Performance evaluationgradient에서 다음으로 이동하기 위해 보폭을 설
16.[인공지능] 6주차(이론) | 심층 신경망

하나의 퍼셉트론으로는 XOR문제를 해결할 수 없다는거 우리가 이미 배운 상태였지. 왜 해결할 수 없는지 그림으로 그리면 다음과 같지.XOR문제란 X1과 X2가 서로 같을 때는 0, 다를 때는 1이 되는 문제인데 아무리 선을 그어봐도 깔끔하게 나눠지지가 않아! 이렇게 M
17.[인공지능] 6주차(실습) | 퍼셉트론

추후 추가 예정
18.[인공지능] 6주차(실습) | MLP(Multi-layer perceptron)

은닉층이 두개 이상인 신경망 구조XOR 문제를 해결 할 수 있다.(앞선 퍼셉트론 하나로는 해결할 수 없었잖아:))앞선 실습과 동일한 data야!Perceptron과 차이는 모델 설계 부분아까는 layer가 1개밖에 없었다구! 근데 이번에는 layer이 2개야이진분류문제
19.[인공지능] 6주차 | 실습과제1
추후 추가 예정
20.[인공지능] 6주차 | 실습과제2
추후 추가예정
21.[인공지능] 7주차(이론) | 심층신경망 (더 좋은 신경망 만들기)

MLP가 등장하면서, XOR문제를 해결했어. 사람들은 아~ NN을 깊게 쌓으면 더 복잡한 문제를 해결할 수 있지 않을까? 하여 더 깊게 쌓아봤는데 또 문제에 봉착했지..바로! Backpropation을 통해 weight와 bias를 업데이트하려고 했는데, 모델이 너무
22.[인공지능] 7주차(실습) | 심층신경망-2

영상 데이터는 이렇게 이루어져 있음숫자가 없는 곳은 0이고 숫자가 있는 곳은 256에 가까운 숫자가 있음(여기서는 정규화가 되었기 때문에 최댓값이 1이고 최솟값이 0이야)배치사이즈: 몇 문제를 풀고 해답을 맞추냐데이터의 개수가 만약 100개인데 batchsize가 1
23.[인공지능] 7주차(실습) | 심층신경망-2
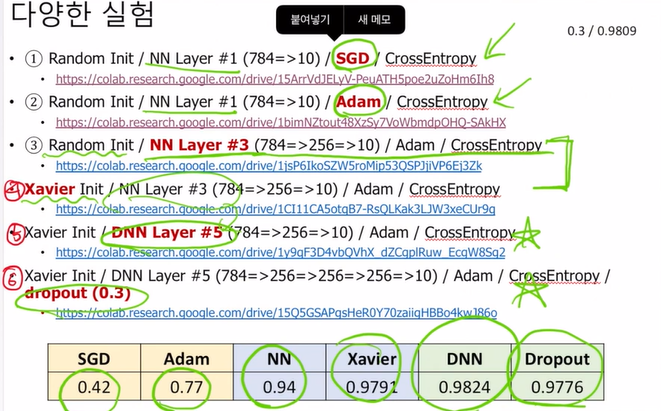
1번과 2번 실험을 통해서 SGD보다는 Adam이 더욱 성능이 높다는 것을 확인2번과 3번 실험을 통해서 모델이 깊을수록 성능이 높다는 것을 확인3번과 4번 실험을 통해서 xavier initialization 초기화를 했을 때 성능이 높다는 것을 확인4번과 5번 실험