
✅ Agenda
• Learning rate
• Data preprocessing
• Avoid overfitting
- More training data
- Regularization
• Performance evaluation
✅ 1. What is a Learning rate
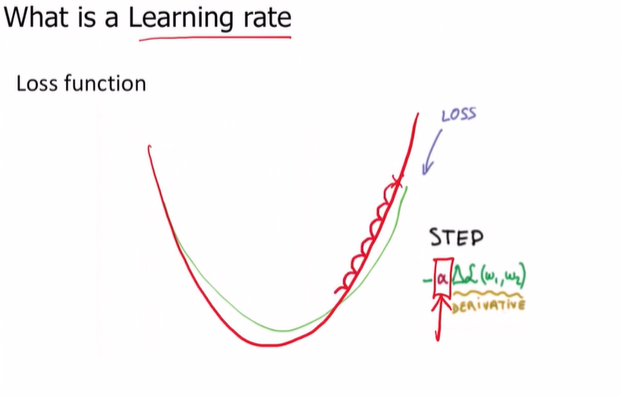
gradient에서 다음으로 이동하기 위해 보폭을 설정해야 한다고 했는데 그게 바로 learning rate
- 값이 작으면 조금 이동하는 것이고
- 값이 크면 많이 이동하는 것
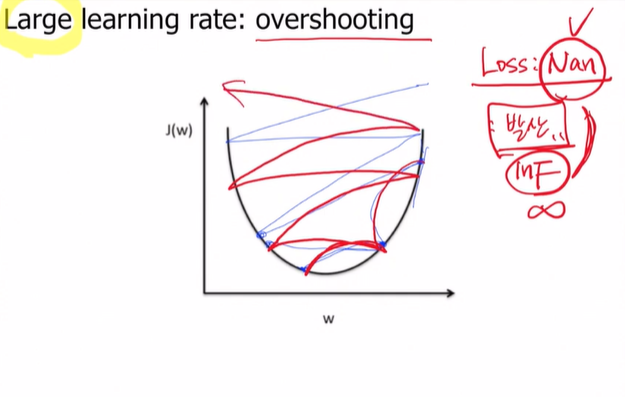
🔅 Large learning rate: overshooting
learning rate가 크면 발생할 수 있는 문제점
바로 우리가 학습을 할 때 Nan이 발생했을 때 있잖아. 발산을 해버린 거야.
🔅 Small learning rate
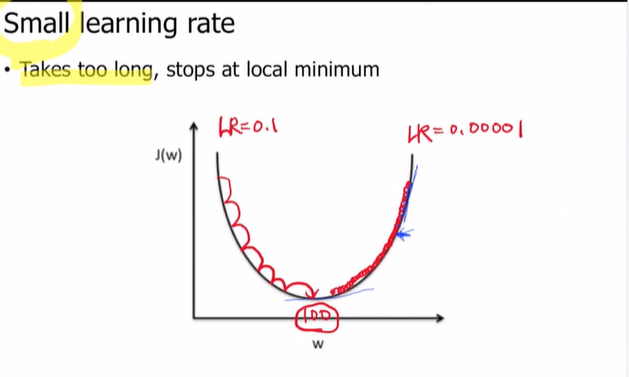 반대로
반대로 learning rate가 너무 작으면 어떨까? 너무 시간이 오래 걸리거나 global minima가 아닌 local minima에 빠질 수도 있어

따라서 적절한
learning rate를 찾는 것이 중요해!
특별한 방법이 있는 것도 아니고, 어느데이터에나 딱 적절한 값이 있는 것도 아니야.
다양한 실험을 통해 직접 찾아야해
🔴 Learining rate를 위한 스케줄러
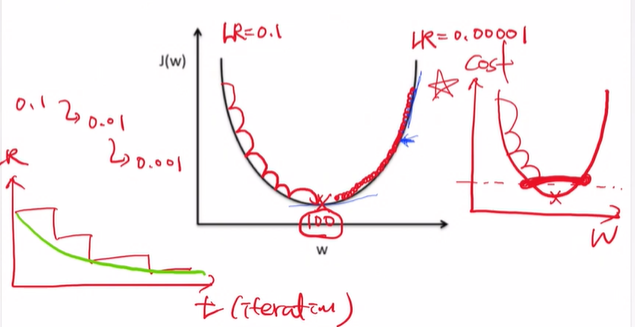 가끔씩은 가장 오른쪽 그래프처럼 global minima에 가지 못하고, 저렇게 핑퐁하는 경우가 있어.
가끔씩은 가장 오른쪽 그래프처럼 global minima에 가지 못하고, 저렇게 핑퐁하는 경우가 있어.
그래서 learning rate scheduler라고 해서 점차적으로 줄여주는게 있음! 학습을 할 때 훨씬 용이해.
✅ 2. Data Preprocessing for gradient descent
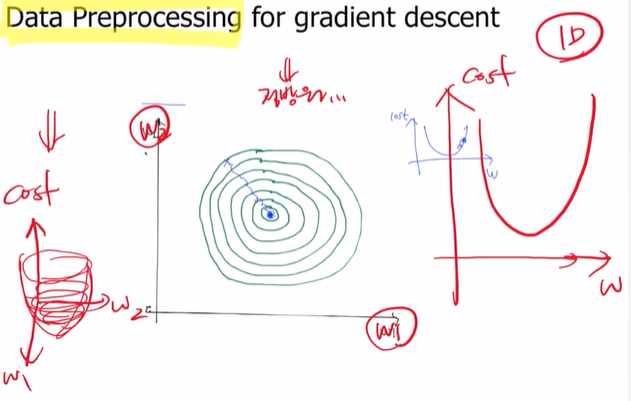
우리가 지금까지 그렸던 cost함수는 오른쪽과 같았어. 근데 이제 입력변수가 2개인 그림을 보겠어!
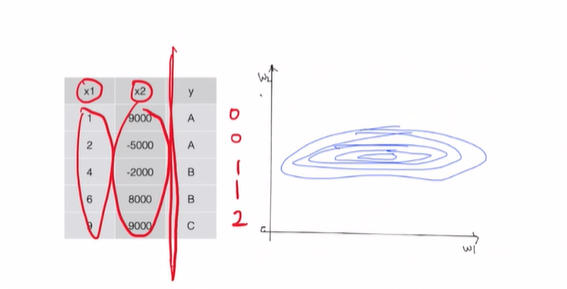 위의 값처럼 두 변수 x1과 x2값이 너무 차이가 난다면, 이렇게 찌그러진 원으로 나타나게 됨.
위의 값처럼 두 변수 x1과 x2값이 너무 차이가 난다면, 이렇게 찌그러진 원으로 나타나게 됨.
근데 문제가 발생하는데......
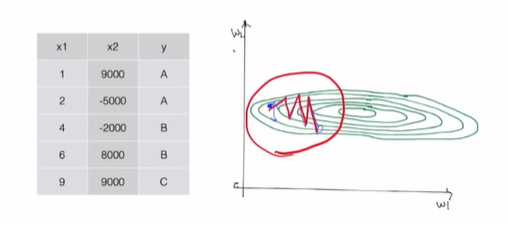 너무 진동을 하면서 가기 때문에, 세심하게 global minima를 찾을 수 없다는 거야
너무 진동을 하면서 가기 때문에, 세심하게 global minima를 찾을 수 없다는 거야
그래서 우리는 정규화를 통해, 찌그러진 원이 아니라 동그란 원으로 바꿔줄거야
🔅 Standardization & Normalization
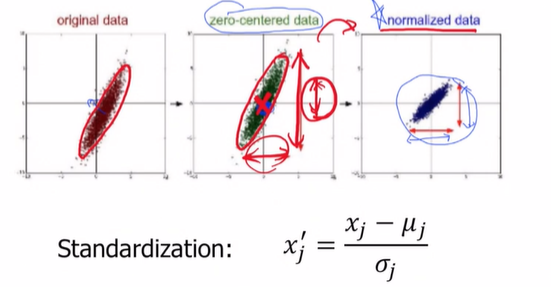 처음에 우리가 받은 데이터는 가장 왼쪽같은 형태인데, 우리는 맨 오른쪽같은 형태로 바꿔야 한다는 뜻이야.
처음에 우리가 받은 데이터는 가장 왼쪽같은 형태인데, 우리는 맨 오른쪽같은 형태로 바꿔야 한다는 뜻이야.
standardization과 normalization을 통해!
✅ 3. What is overfitting
overfitting: 주어진 데이터에 대해서만 좋은 성능을 내는 것, 즉 train에 good 그러나 test에 bad
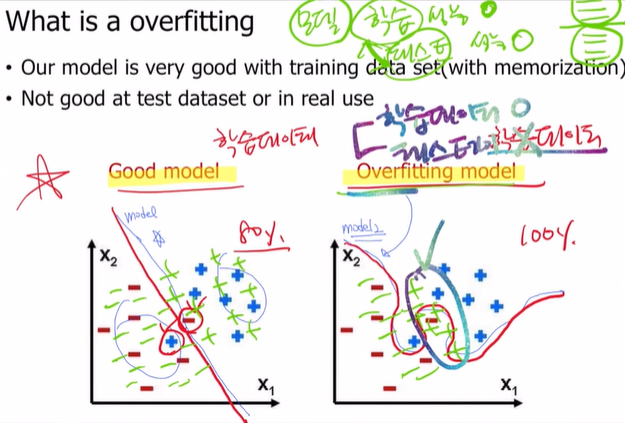
우리의 모델은 train뿐만 아니라 test까지 결과가 좋아야 해!
따라서 우리가 실습할 때, train accuracy는 좋은데 test accuracy는 낮다면 overfitting되었다고 생각하면 돼.
가장 이상적인 경우는 train accuracy와 test accuracy가 동일할 때야!
🔅 Solutions for overfitting
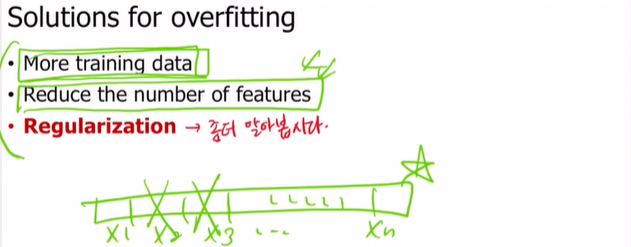
- 학습 data 증가
- feature의 개수 줄이기
: (x1,x2,...) -> 몇개 제거하는거- regularization
🔅 Regularization
loss function에 'regularization'항을 추가로 붙이는 거야
W가 커지지 않도록 제어해주세요!라는 뜻.
는 얼마나 regularization을 할 건지 결정해주는 값
- 조금만 제어하고 싶으면 0.001
- 더 많이 제어하고 싶으면 0.1
✅ Performance evaluation
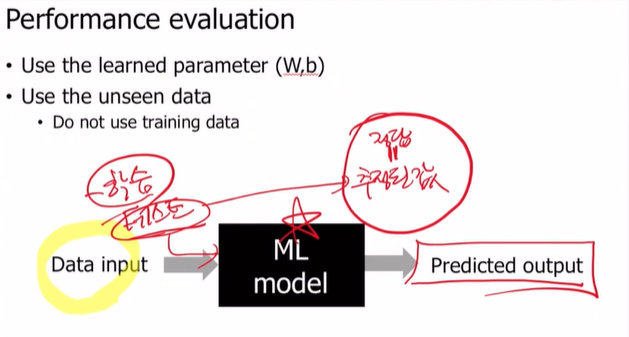 평가라는건 딱 이런 것이지. 학습된 파라미터 W,b를 사용해서 본 적 없는 데이터에 적용해보는거.
평가라는건 딱 이런 것이지. 학습된 파라미터 W,b를 사용해서 본 적 없는 데이터에 적용해보는거.
train data와 test data는 절대 겹치는 데이터가 존재해서는 안된다!!!!
🔅 Evaluation using training set
 모델은 똑똑하기 때문에 이해해서 문제를 푸는게 아니라 그냥 외워버리는 성향이 있다. 따라서 다음과 같이 train과 test를 만들어야 한다는거!
모델은 똑똑하기 때문에 이해해서 문제를 푸는게 아니라 그냥 외워버리는 성향이 있다. 따라서 다음과 같이 train과 test를 만들어야 한다는거!
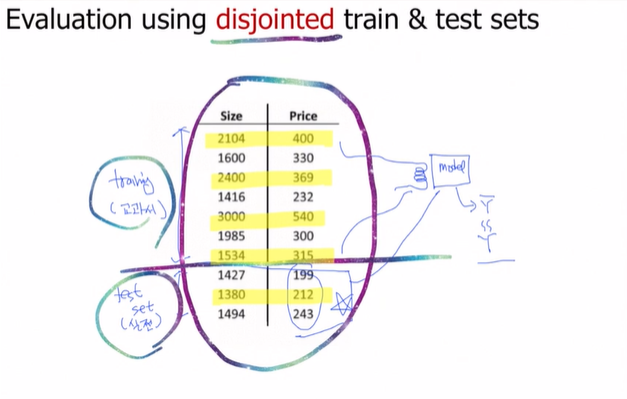
가장 큰 핵심은 disjointed하게 만들어야 한다는거
🔅 Training, validation, and test sets
학습하는 과정에서 내 모델이 잘 하고 있는지 중간중간에 평가하고 싶을 때 validation data set 만드는 것!
어 그러면 이런 반론을 할 수도 있다. 뭐하러 만드냐. 그냥 훈련해보고 test 적용해보고, 훈련해보고 test 적용해보면 되는게 아니냐.
아니지! 아까 말했듯이 모델은 data를 보자마자 그냥 외워버린다니까! 절대로 보여줘서는 안돼
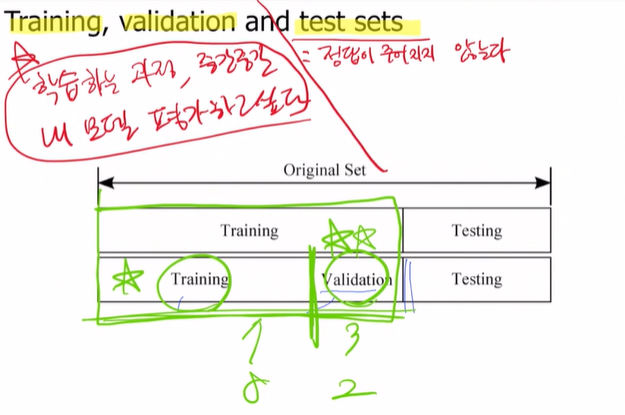 중간중간에 train data에 대한 평가를 valdiation에서 할 수 있음
중간중간에 train data에 대한 평가를 valdiation에서 할 수 있음

