
✅ MNIST Dataset 소개하기
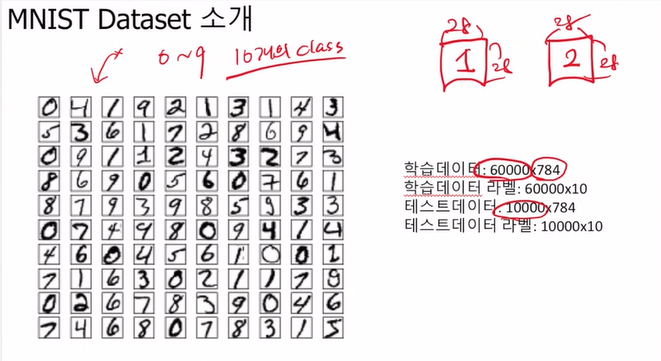
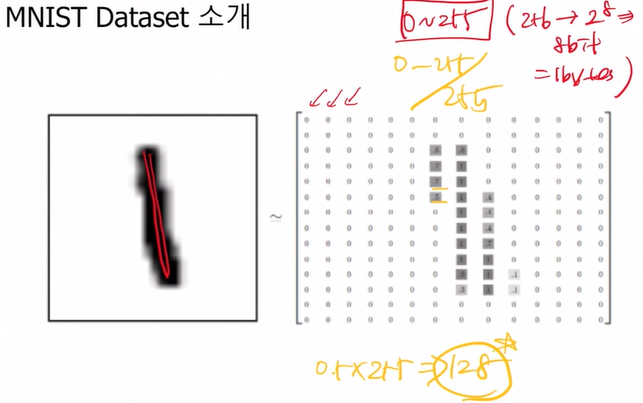
영상 데이터는 이렇게 이루어져 있음
숫자가 없는 곳은 0이고 숫자가 있는 곳은 256에 가까운 숫자가 있음
(여기서는 정규화가 되었기 때문에 최댓값이 1이고 최솟값이 0이야)
✅ Batch_size(배치사이즈)
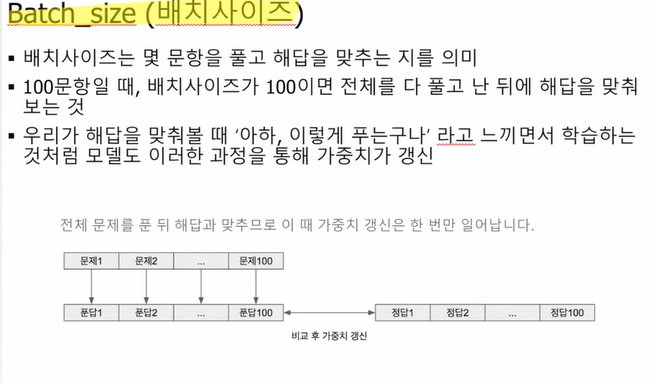
배치사이즈: 몇 문제를 풀고 해답을 맞추냐
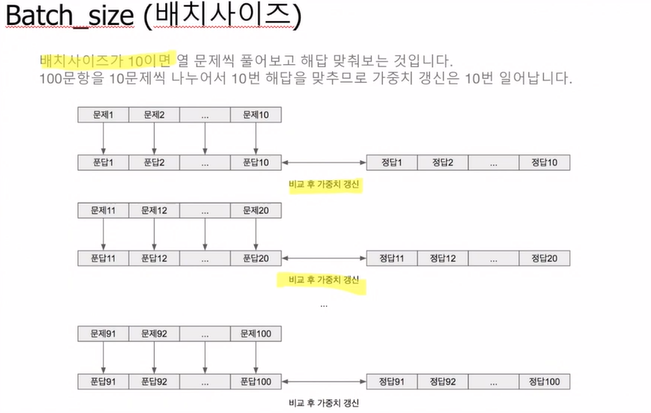 데이터의 개수가 만약 100개인데 batchsize가 10이라면, 10문제 풀고 답을 맞춰보고 ~ 10문제 풀고 답을 맞춰보는 상황이다.
데이터의 개수가 만약 100개인데 batchsize가 10이라면, 10문제 풀고 답을 맞춰보고 ~ 10문제 풀고 답을 맞춰보는 상황이다.
.
이때 답을 맞춰본다는 것은,,
비교 후에 가중치를 개선하는 것을 의미한다
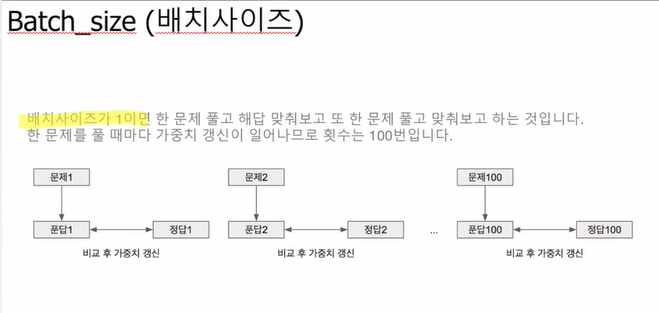 또 다른 예로, batchsize가 1이라면 100문제 풀 때 100번의 가중치 갱신이 필요하겠지..
또 다른 예로, batchsize가 1이라면 100문제 풀 때 100번의 가중치 갱신이 필요하겠지..
 그럼 둘 중에 어떤 경우의 batchsize가 더 좋다고 할 수 있나?
그럼 둘 중에 어떤 경우의 batchsize가 더 좋다고 할 수 있나?
일단, batchsize가 100이면 100문제를 다 풀고 시험을 보는 것이기 때문에 모르는 유형은 계속 몰라서 유사문제를 다 틀려버리겠지. 하지만, batchsize가 1이면 틀렸던 유형에 대해 학습이 되고 있으니까 유사 문제들을 맞출 수 있겠지!
.
어 그러면 batchsize를 어떻게 설정해야 하는 겁니까?
batchsize가 너무 크다면, 100문제를 다 기억해야 하므로 기억력, 즉 용량이 엄청 커야해. GPU성능도 좋아야 하고
batchsize가 너무 작다면, 학습하는데 너무 오랜 시간이 걸리겠지. 한 문제 풀고 맞춰보고 한 문제 풀고 맞춰 보고
batchsize를 키우면, 학습속도는 빨라지는 대신 용량이 많이 필요하고
batchsize를 낮추면, 학습속도는 느려지지만 용량은 많이 필요하지 않음
교수님께서 batchsize는 가능한 만큼 최대의 크기를 설정하는 것을 권장하심, 그 이유는 epoch와 같이 설정하면 학습이 잘 이루워질 수 있음
최근의 연구에는 batchsize가 크면클수록 결과가 좋다는 얘기도 있었는데 교수님께서는 데이터에 따라 다른 것으로 생각하심
✅ Epochs (에포크)
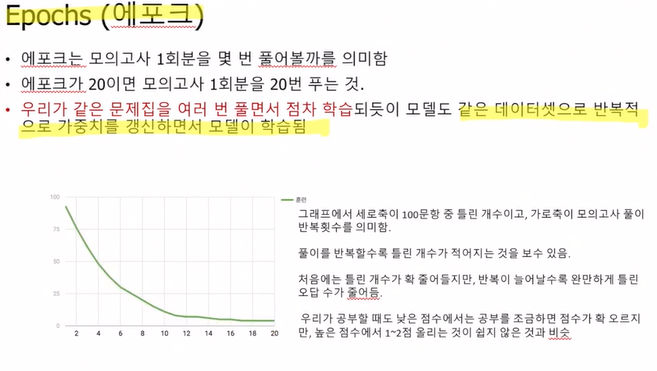
우리가 문제집을 여러번 풀면 성적이 향상되듯이, 모델 또한 같은 데이터를 여러번 학습되면 성능이 향상된다는 개념
✅ Optimizer: 기본
GD & SGD
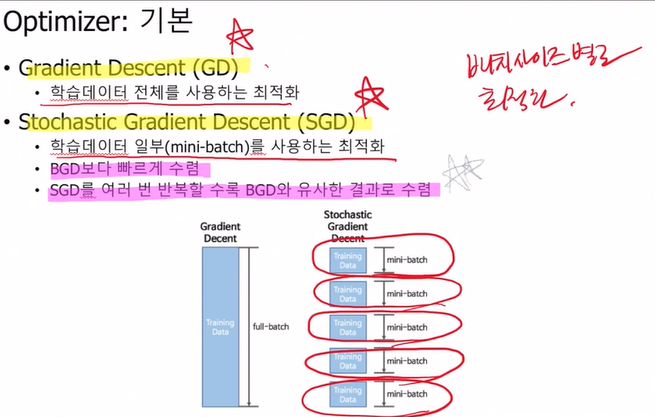 앞으로 우리가 만날 데이터는 정말 너무나 크단 말이야. 학습할 때 모든 데이터를 다 사용한다면 너무 시간도 많이 걸릴거야. 그니까 우리는 어떻게 한다? batchsize별로 최적화를 시키는데 이걸 여러번하면 된다는 소리지!
앞으로 우리가 만날 데이터는 정말 너무나 크단 말이야. 학습할 때 모든 데이터를 다 사용한다면 너무 시간도 많이 걸릴거야. 그니까 우리는 어떻게 한다? batchsize별로 최적화를 시키는데 이걸 여러번하면 된다는 소리지!
= 전체 결과를 한번에 돌리는 거랑 같은 결과를 가져오더라~~
Optimizer: 발전 방향
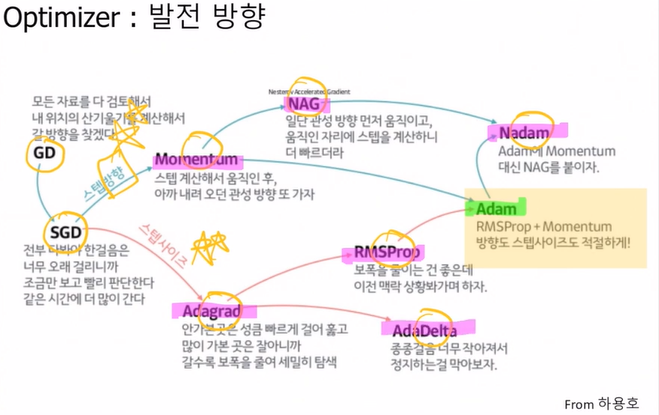
다 하나씩 자세히 알 필요는 없지만 발전 방향이 2가지로 나뉜다는 것은 확인하는게 좋다.
optimizer이란 어쨌든 global minima를 찾아가는 과정인데 이때 (1) 스텝방향을 조절 (2) 스텝사이즈를 조절하는 2가지 방법으로 나뉜다.
.
그리고 마지막으로 이 2가지의 장점을 모두 결합한 것이 가장 많이 쓰이고 있는 Adam
Optimizer: 비교
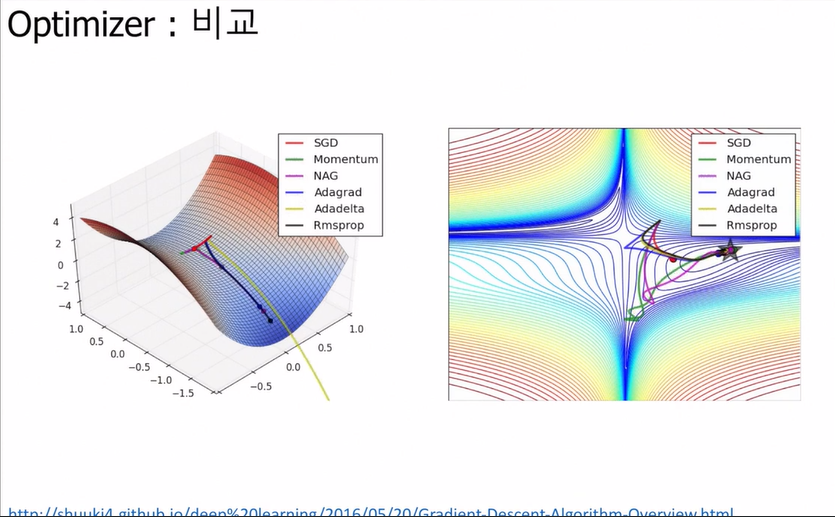 각각 optimizer들의 장단점들을 볼 수 있지.
각각 optimizer들의 장단점들을 볼 수 있지.
✅ torchvision이란?
 torchvision이 제공하는 여러 데이터셋들 중에서 우리는
torchvision이 제공하는 여러 데이터셋들 중에서 우리는 MNIST와 CIFAR만 제대로 알면 돼.
