
데이터구조의 기본 재료
데이터 구조에는 크게 두가지가 있다.
바로 배열과 연결리스트인데 둘 중에 누가 더 좋아요?하면 대답하기 어렵다.
상황에 따라 필요한 데이터구조가 다르기 때문이다.
(그래도 특별한 요구 없으면 배열 쓰는 것 추천)

배열
배열(array)
: 순차 기억장소에 할당된 유한개수의 동일 자료형 데이터원소들
이때 우리가 조금 더 집중해야 할 것은 중간에 추가할 수 있는 연결리스트와 달리 배열의 크기 자체를 미리 정해놓는다는 것이다.
[배열 표시 방법]
: 시작원소인 와 끝원소인 를 적는 것

다차원 배열
1차원 배열에서 확장한 버전이라고 생각하면 된다
[배열 표시 방법]
: 시작원소인 와 끝원소인 를 적는 것

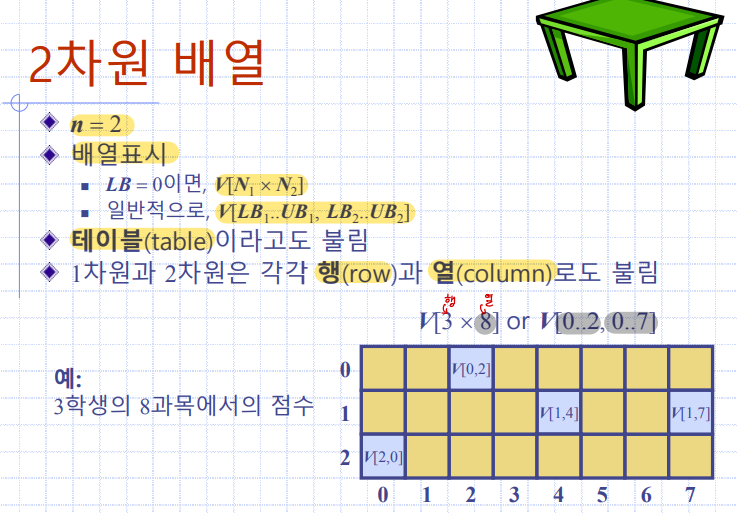
2차원 배열
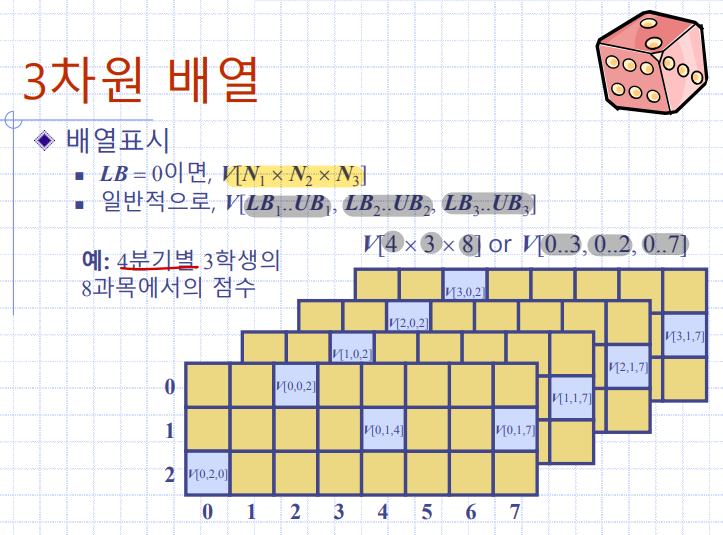
3차원 배열
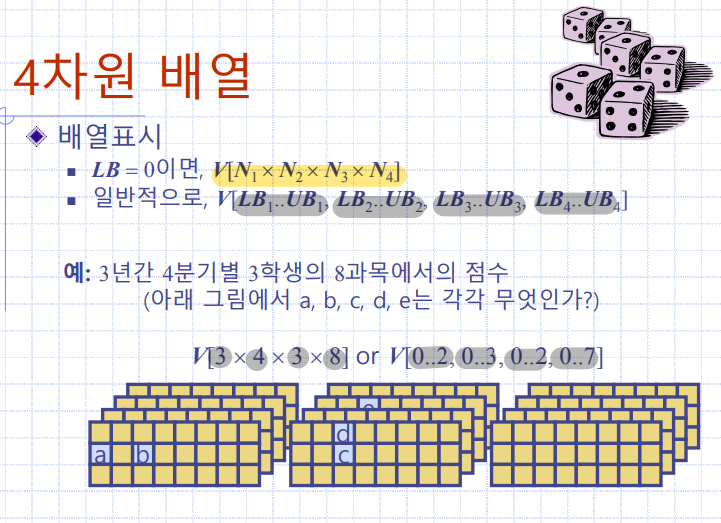
4차원 배열
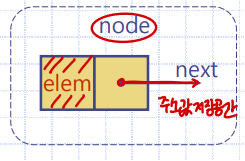
노드에 대한 메모리 할당
노드(node)
: 한개의 데이터원소를 저장하기 위해 동적 메모리(dynamic memory)에 할당된 메모리
getnode(): 노드 할당 & 그 노드의 주소 반환
putnode(): 노드에 할당되었던 메모리 사용 해제
우리가 동적할당에서 malloc을 통해 배열을 할당하고, free를 통해 메모리 사용해제 한 것과 같은 원리이다.

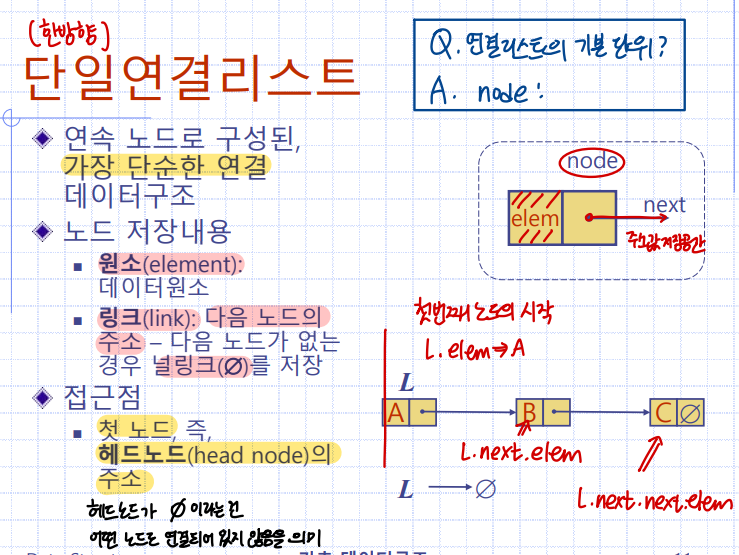
단일연결리스트
단일연결리스트
:연속 노드로 구성된 가장 단순한 연결 데이터구조
노드 저장 내용
원소(element): 데이터원소
링크(link): 다음 노드의 주소 (없을 시에 NULL)
접근점
: 헤드노드(head)의 주소
이중연결리스트
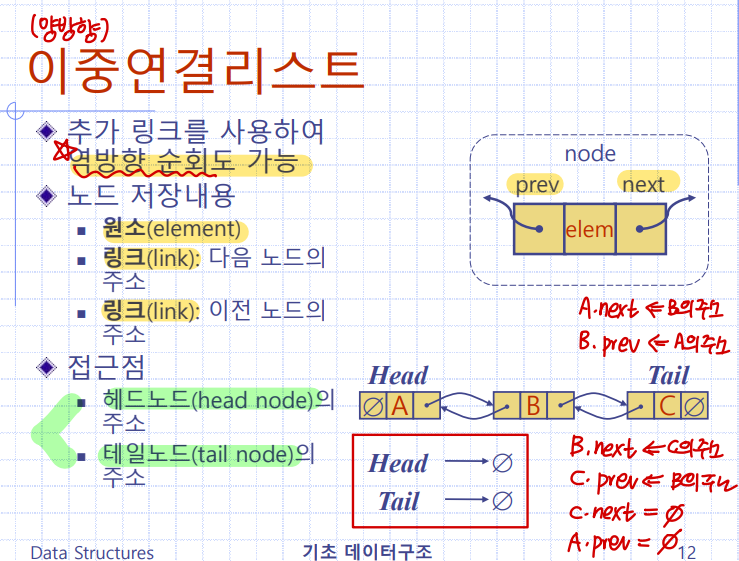
이중연결리스트
:추가링크를 사용해 역방향 순회도 가능
노드 저장 내용
원소(element): 데이터원소
링크(link): 다음 노드의 주소 (없을 시에 NULL)
링크(link): 이전 노드의 주소 (없을 시에 NULL)
접근점
: 헤드노드(head)의 주소
: 테일노드(tail)의 주소
원형(단일)연결리스트
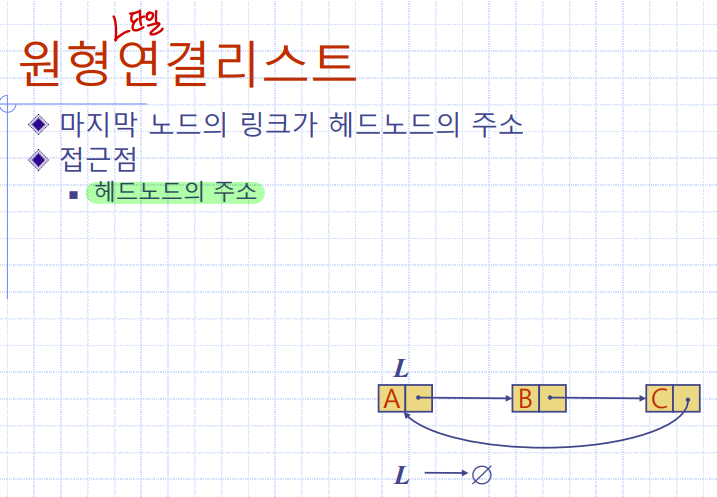
원형연결리스트
마지막 노드의 링크가 헤드노드의 주소
접근점
: 헤드노드(head)의 주소
헤더와 트레일러
헤드노드 바로 앞에 특별한
헤더(header)노드
혹은 테일노드 바로 뒤에 특별한트레일러(trailer) 노드
특별노드 저장내용
dummy~~
접근점
: 헤더(header)노드 or 트레일러(trailer)노드의 주소

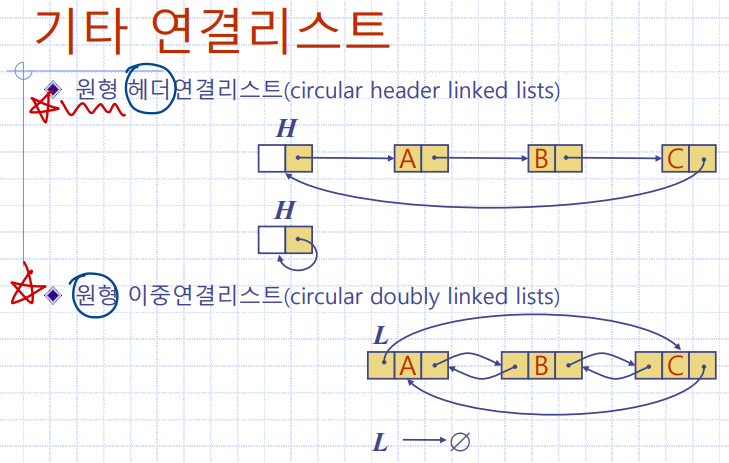
기타연결리스트
원형 헤더연결리스트
원형 이중연결리스트
헤더 및 트레일러 이중연결리스트
헤더 및 트레일러 원형 이중연결리스트
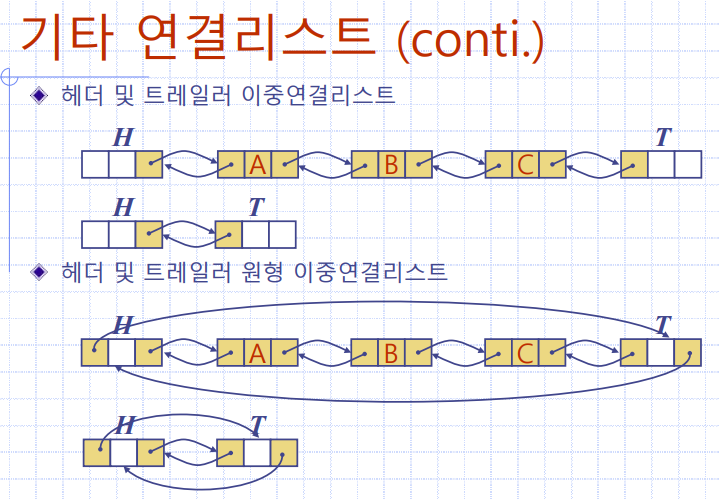
즉 기타연결리스트에 있는 데이터구조들은
기본적으로 배웠던
'단일', '이중', '원형', '헤더', '트레일러'를 조합하여 만든 결과물인 것이다.
