자료구조
1.[자료구조] 1.1 Data Structures

data가 저장된 형식과 데이터에 수행할 program의 작동방식에 따라서 data structure을 고르게 된다.배열에서는 shifting하기 위해서 기존에 있던 애들을 한칸씩 옮겼다면, linked list에서는 pointer만 바꾸면 가볍게 해결이 된다. "No
2.[자료구조] 1.2 Introduction to algorithms

최댓값 찾는 알고리즘은 이미 많이 배웠던 것이지특정 단어가 몇번 나왔는지 찾는 그런 알고리즘을 해결하는 상황을 가정마땅한 알고리즘을 찾는게 어렵기는 하지만 그래도 common subprobelm에 사용된 사례가 있기 때문에 이를 참고하면 되겠다.알려진 efficien
3.[자료구조] 1.3 Relation betwwen data structures and algorithms

Data structures not only define how data is organized and stored, but also the operations performed on the data structure. While common operations inc
4.[자료구조] 1.4 Abstract data types (ADT)
An abstract data type (ADT) is a data type described by predefined user operations, such as "insert data at rear," without indicating how each operati
5.[자료구조] 1.5 Applications of ADTs

Abstraction means to have a user interact with an item at a high-level, with lower-level internal details hidden from the user. ADTs support abstracti
6.[자료구조] 2. Objects and Classes Overview

In addition to public member methods, a class definition has private fields: variables that member methods can access but class users cannot. The priv
7.[자료구조] 1.6 Algorithm efficiency

Algorithm efficiency An algorithm describes the method to solve a computational problem. Programmers and computer scientists should use or write effic
8.[자료구조] 1.6 Algorithm efficiency
Algorithm efficiency An algorithm describes the method to solve a computational problem. Programmers and computer scientists should use or write effic
9.[자료구조] w2_난수 발생 함수
주사위 눈 수처럼 특정한 나열순서나 규칙없이 생성된 무작위 수rand(): 0~RAND_MAX 범위의 무작위 정수 반환(RAND_MAX는 rand()가 반환할 수 있는 최대수, 시스템마다 다를 수 있음)난수 발생함수를 사용하기 위해서는 아래와 같은 헤더파일이 필요하다.
10.[자료구조] w2_시간측정 함수
알고리즘의 실행시간을 측정하는 방법에는 크게 2가지가 있다1\. 점근적 분석 방법2\. 실제 시간 측정점근적 분석 방법: Big-Oh값을 구하는 이론적 방식: 이론적 방식에 의해 측정할 수 있음실제 시간 측정: 알고리즘 실행에 소요되는 cpu time 측정: 라이브러리
11.[자료구조] w1_동적할당 메모리 누수 확인
이렇게 위와 같이 free(q)를 해주지 않은 경우디버그를 하면 메모리 누수가 검출된다.
12.[자료구조] w2_알고리즘 분석_행렬에서 특정원소 찾기
nxn 배열 A의 원소들 중 특정 원소 x를 찾는 알고리즘 -> findMatrix 작성알고리즘 findMatrix는 (1) A의 행들을 반복하며, x를 찾거나 (2) A의 모든 행들에 대한 탐색을 마칠 때까지, 각 행에 대해 알고리즘 findRow를 호출한다위의 의도
13.[자료구조] w2_알고리즘 분석_비트행렬에서 최대 1행 찾기

$$n\*n$$ 배열 A의 각 행은 1과 0으로만 구성되며, A의 어느 행에서나 1들은 해당 행의 0들보다 앞서 나온다고 가정A가 이미 주기억장치에 존재한다고 가정하고, 가장 많은 1을 포함하는 행을 $$O(n)$$ 시간에 찾는 알고리즘 mostOnes(A,n)를 의사
14.[자료구조] w2_알고리즘 분석_누적평균

배열 X의 i번째 누적평균(prefix average)이란 X의 i번째에 이르기까지의 (i+1)개의 원소들의 평균(즉, $$Ai = (X0+X1+...+Xi)/(i+1)$$)배열 X의 누적평균(prefix average) 배열 A를 구하는 알고리즘을 의사코드로 작성하라
15.[자료구조] w3_재귀 (개념)

재귀적자기 자신을 사용하여 정의된 알고리즘종료조건인 basecase(베이스케이스)작아진 부문제들로 이루어지는 recursion(재귀케이스)always 베이스케이스(basecase) 가져야 한다.재귀호출은 always 베이스케이스(basecase)\` 방향으로꼭 필요할
16.[자료구조] w2_알고리즘 분석 (개념)

알고리즘주어진 문제를 유한한 시간 안에 해결하는 것지금까지는 우리가 input을 넣었을 때 output이 맞기만 하면 정답처리가 되었었다.하지만 이제는, 답이 맞는 것뿐만 아니라 '좋은 알고리즘'을 설계하는데 집중해야 한다좋은 알고리즘이란?1) 실행시간이 적고2) 메모
17.[자료구조] w3_재귀_재귀적 곱하기와 나누기
a와 b의 곱을 계산하는 재귀 알고리즘 product(a,b)를 작성하라a를 b로 나눈 나머지를 계산하는 재귀 알고리즘 modulo(a,b)를 작성하라a를 b로 나눈 몫을 계산하는 재귀 알고리즘 quotient(a,b)를 작성하라주의)\-의사코드로 작성\-a와 b는 양
18.[자료구조] w3_재귀_하노이탑

하노이탑(towers of Hanoi) 문제3개의 말뚝: A,B,C초기상황: 직경이 다른 n>0개의 원반이 A에 쌓여있음목표: 모든 원반을 A에서 C로 옮김이동순서를 "move from x to y" 형식으로 인쇄<조건>한번에 한개의 원반만을 이동언제라도 직경이
19.[자료구조] w4_기초데이터구조 (개념)

데이터 구조에는 크게 두가지가 있다.바로 배열과 연결리스트인데 둘 중에 누가 더 좋아요?하면 대답하기 어렵다.상황에 따라 필요한 데이터구조가 다르기 때문이다.(그래도 특별한 요구 없으면 배열 쓰는 것 추천)배열(array): 순차 기억장소에 할당된 유한개수의 동일 자료
20.[자료구조] 가로방향으로 지그재그 배열

$$N$$을 입력받고$$N\*N(1<=N<=100)$$ 크기의 행렬에아래 그림과 같이 ->, <-로 지그재그 채운 배열 문제 풀어라ex) $$4\*4$$ 배열일 때짝수번째의 행일 때는 -> 방향홀수번째 행일 때는 <- 방향따라서짝수번째 행일 때는
21.[자료구조] 달팽이 모양의 배열

N과 M을 입력받고$$NxM(1<=N,M<=100)$$ 크기의 행렬에$$1~NM$$의 수를 나선형으로 채운 결과를 출력하라ex) 각각 4x4, 4x5일때예를 들어 $$4\*5$$ 행렬일 때 아래 그림과 같이 쌍을 묶는다.묶은 쌍은index가 증가하거나 감소할
22.[자료구조] 지그재그 배열 문제

$$N\*M(1<=N,M<=100)$$ 크기의 행렬에 $$1~MN$$의 수를 대각선 방향으로 채운 결과를 출력하라ex) $$44$$, $$55$$ 행렬일 때의 예시아래 그림과 같이 두 파트로 나누기로 했다$$(i,j)$$에서 $$i=0$$인 경우$$(i,j)
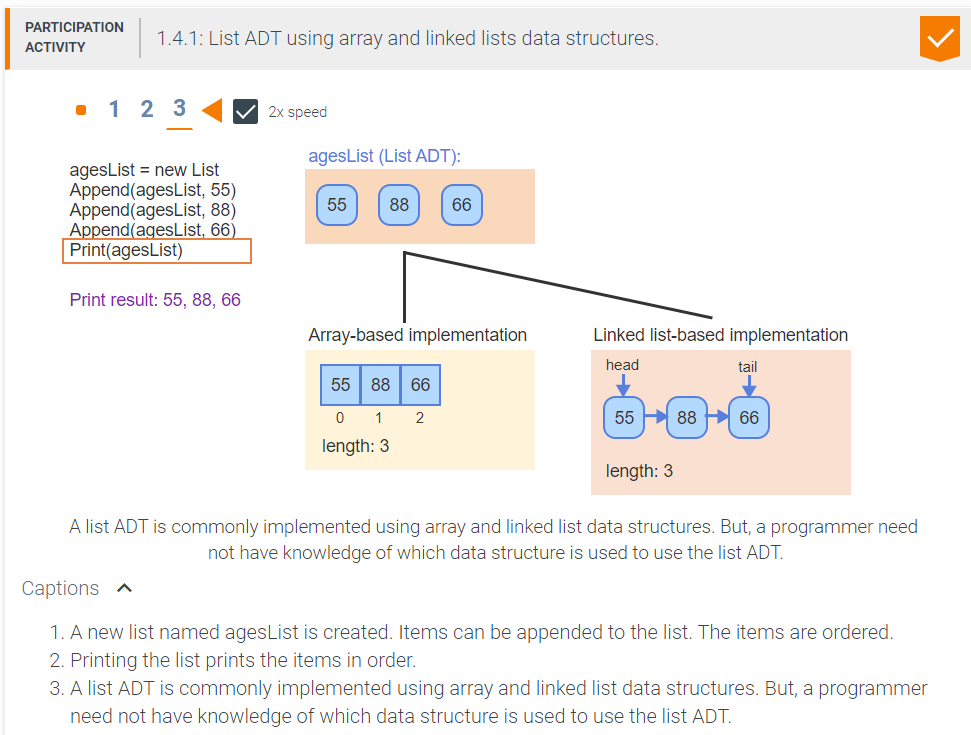
23.[자료구조] w5_리스트(1)(개념)

ADT(Abstract Data Type): 추상자료형, 데이터구조의 추상형: 실제 존재하는 개념을 내가 원하는 자료형으로 만드는 것rank(순위): 리스트 ADT에서 원소에 접근할 때 필요한 도구일반메소드접근메소드갱신메소드invalidRankException(): 유