
알고리즘 분석

알고리즘
주어진 문제를 유한한 시간 안에 해결하는 것
지금까지는 우리가 input을 넣었을 때 output이 맞기만 하면 정답처리가 되었었다.
하지만 이제는, 답이 맞는 것뿐만 아니라 '좋은 알고리즘'을 설계하는데 집중해야 한다
좋은 알고리즘이란?
1) 실행시간이 적고
2) 메모리 사용량이 적은
알고리즘을 의미한다
실행시간

그렇다면 실행시간이란 무엇일까?
프로그램이 실행되는데 걸리는 시간을 의미한다.
일반적으로, 실행시간은 '입력의 크기'에 비례하는데
예를 들어 집단의 평균을 구하는 알고리즘이 있다고 할 때 100명일 때보다 1억명일 때 시간이 더 오래 걸리기 때문이다.
이때, 주의해야 할 점은 반드시
최악실행시간을 기준으로 생각한다는 것이다.
즉, 가장 시간이 오래 걸리는 것을 기준으로
실행시간 구하기 - 1 실험적 방법
실행시간을 구하는 방법으로는 2가지가 있고,
그 중에 첫번째가 바로 실험적 방법이다.
말 그대로, 아래 사진과 같이 여러번의 실험을 통해 나온 결과를 측정하는 것이다.
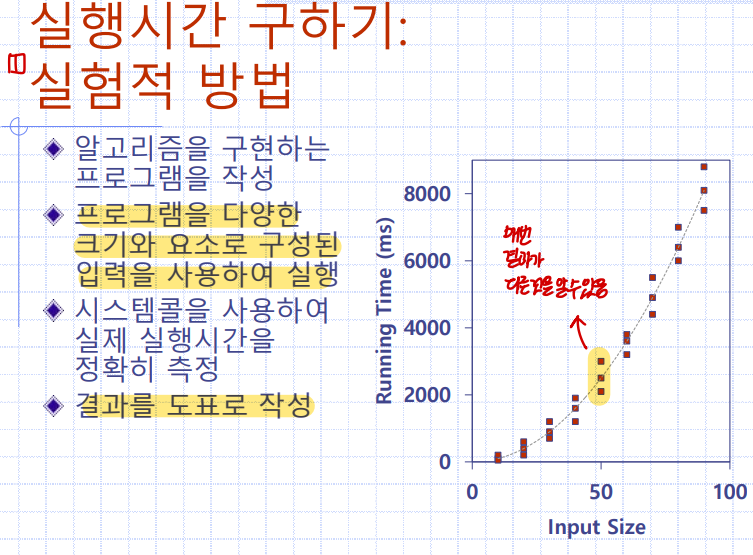
실험적 방법의 한계
하지만 이러한 방법에는 한계가 있다.
그것은 바로 언제나 동일한 하드웨어와 동일한 소프트웨어 환경이 사용되어야 한다는 것이다.
예를 들어, 과제를 하고 친구와 실행시간을 비교하려고 할 때, 영희와 철수의 컴퓨터가 같은 기종이어야만 가능한 것이다.

실행시간 구하기 - 2 이론적 방법
그래서 제안하는 방법이 두번째이다.
하드웨어와 소프트웨어 환경이 동일하지 않더라도 비교할 수 있는 기준이 필요한 것이다. 하드웨어나 소프트웨어와 무관하게
이때, 우리는의사코드를 이용한다.

의사코드 (pseudo-code)
의사코드
알고리즘을 설명하기 위한 고급언어로
인간에게 읽히기 위해 작성됨

의사코드가 나오게 된 배경은 다음과 같다.
예를 들어, 친구과 과제를 어떻게 풀었는지 물어볼 때 우리는 코드 하나하나를 다 읽어주지 않고 이렇게 대답한다. "아 변수 2개를 선언하고 새로운 변수에 그 둘의 합을 대입한 후 출력하면 돼~"
이렇게 인간에게 읽히기 위해
프로그래밍 언어보다는 덜 상세히 설명하는 언어가 바로 의사코드이다.
의사코드 문법
문법은 아래와 같다.

임의접근기계 모델
이러한 이론적 방법이 가능한 이유는
바로 임의접근기계 모델을 사용하기 때문인데
임의접근기계(RAM)
1. 하나의 중앙처리장치(CPU)
2. 무제한의 메모리셀(memory cell)

이때, 메모리셀들은 어떤 셀에 대한 접근이라도
'동일한 시간단위'가 소요된다.
즉, 그림처럼 배열의 크기와 상관없이 특정 index의 값을 찾아내는데 똑같은 시간이 걸린다.
원시작업
원시작업
알고리즘에 의해 수행되는 기본적인 계산들
ex)EXP,ASS,IND,CAL,RET

원시작업 수 세기
우리는 의사코드를 통해
원시작업의 최대개수를 입력크기의 함수 형태로 결정한다.

실행시간 추정
원시작업 개수를 센 것을 통해 아래와 같이 실행시간을 추정할 수 있다.

실행시간의 증가율
변하지 않는 선형의 증가율을 나타내는 실행시간 T(n)은 arrayMax의 고유한 속성

Big-Oh와 증가율
함수의 증가율을 표시하는 단위인 Big-Oh는
증가율의 상한을 나타낸다
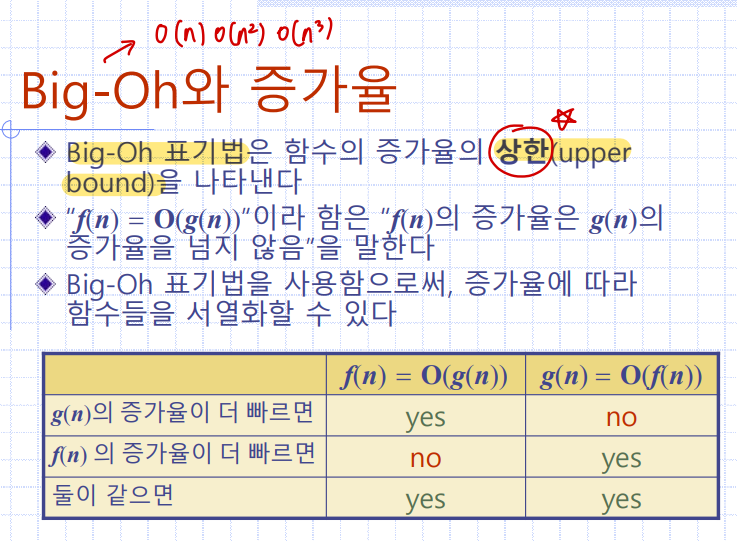
점근분석
알고리즘 분석을 통해 우리는 Big-Oh 표기법에 따른 실행시간을 구할 수 있다

이때 무엇보다 주의해야 할 점은
(1) 상수 계수와
(2) 낮은 차수의 항들은
결국 탈락된다는 것이다.
분석의 지름길
그럼 이제 각각 코드마다 원시작업들을 어떻게 계산하는지 알아보자.
-
반복문
각각의 operation에 해당하는 count의 합을 더해주면 된다. -
중첩반복문
(반복문의 실행시간) x (각 반복문의 크기)
반복문의
Big-Oh는 사실 for문의 개수와 동일하다.
- for문이 1개라면 -> O(h)
- for문이 2개라면 -> O(h^2)
-
연속문
각 문의 실행시간 중최댓값선택 -
조건문
조건 검사의 실행시간 중최댓값선택


Big-Oh의 친척들
실행시간을 구하는 단위는 Big-Oh뿐만 아니라 다른 방법도 있다.
바로 함수의 증가율의 하한을 나타내는 Big-Omega와
함수의 증가율의 하한과 상한을 모두 나타내는 동일함수 Big-Theta가 있는데
여기서는 크게 다루지 않겠다.

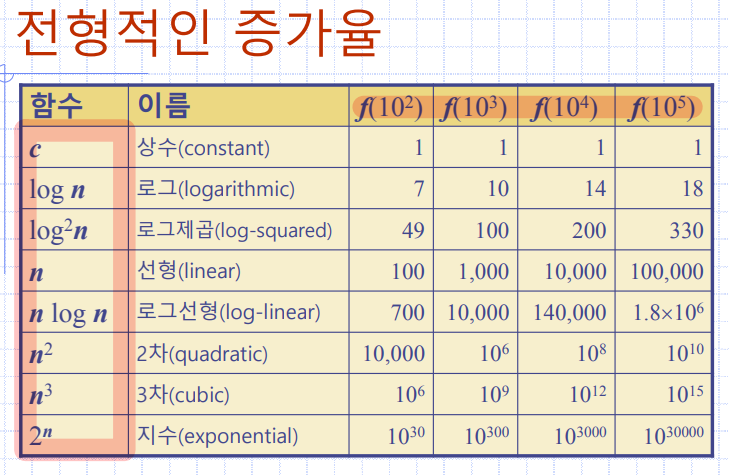
전형적인 증가율
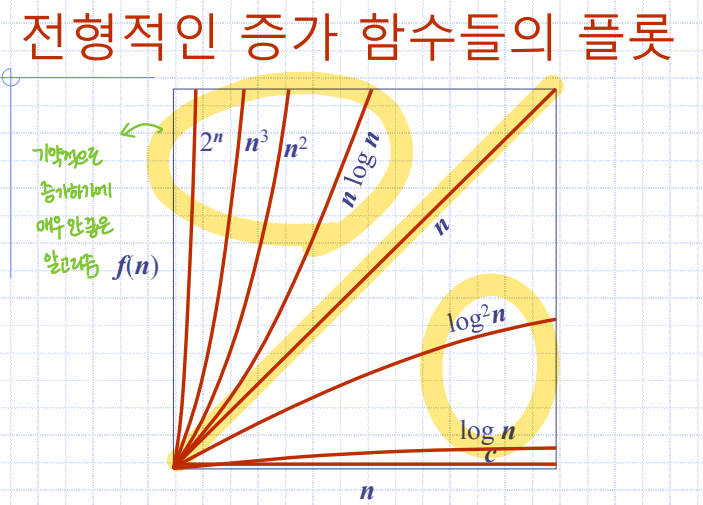
알아야 할 수학적 배경

본 게시물을 최유경 교수님의 자료구조 수업을 바탕으로 정리하였습니다.
