custom data를 통해 모델을 학습시키는 방법을 보겠습니다.
Config

먼저 dataset을 mmdetection이 받아들일 수 있도록 dataset config 를 통해 변환해야 합니다.
mmdet는 다양한 유형의 class를 통해 dataset을 정의해놨습니다.
다만 coco, voc dataset config의 경우 기존의 데이터셋과 동일하게 디렉토리 구조까지 맞춰줘야 햐기 때문에 CustomDataset을 쓰는것이 편합니다.
Pascal voc vs MS coco
voc : 이미지 1개 당 1개의 annotaion 파일을 가짐 / 해당 annotation 파일에 개별 object의 bbox정보가 들어감
coco : 전체 이미지에 대한 단 1개의 annotation 파일을 가짐 / 해당 annotation 파일에 info, license, images, annotations, categoris 대분류로 나누어지고, annotaion 부분에 개별 이미지에 대한 bbox정보가 있음
Custom dataset에 사용되는 포맷

Custom dataset은 모든 이미지들에 대한 annotaion 정보를 list객체로 가집니다. list내의 개별원소는 dict로 구성되며, 개별 dict가 이미지의 annotation 정보를 가집니다. 1개 이미지는 여러 개의 Object bbox와 labels annotation 정보들을 개별 dict로 가지며, 1개 이미지의 Object bbox는 2차원 array로, object label은 1차원 array로 구성됩니다.
Custom dataset의 구조
@DATASETS.register_module() # 1
class CustomDataset(Dataset):
"""Custom dataset for detection.
The annotation format is shown as follows. The `ann` field is optional for
testing.
.. code-block:: none
[
{
'filename': 'a.jpg',
'width': 1280,
'height': 720,
'ann': {
'bboxes': <np.ndarray> (n, 4) in (x1, y1, x2, y2) order.
'labels': <np.ndarray> (n, ),
'bboxes_ignore': <np.ndarray> (k, 4), (optional field)
'labels_ignore': <np.ndarray> (k, 4) (optional field)
}
},
...
]
Args:
ann_file (str): Annotation file path.
pipeline (list[dict]): Processing pipeline.
classes (str | Sequence[str], optional): Specify classes to load.
If is None, ``cls.CLASSES`` will be used. Default: None.
data_root (str, optional): Data root for ``ann_file``,
``img_prefix``, ``seg_prefix``, ``proposal_file`` if specified.
test_mode (bool, optional): If set True, annotation will not be loaded.
filter_empty_gt (bool, optional): If set true, images without bounding
boxes of the dataset's classes will be filtered out. This option
only works when `test_mode=False`, i.e., we never filter images
during tests.
"""
CLASSES = None # 2
def __init__(self, # 3
ann_file,
pipeline,
classes=None,
data_root=None,
img_prefix='',
seg_prefix=None,
proposal_file=None,
test_mode=False,
filter_empty_gt=True):
self.ann_file = ann_file
self.data_root = data_root
self.img_prefix = img_prefix
self.seg_prefix = seg_prefix
self.proposal_file = proposal_file
self.test_mode = test_mode
self.filter_empty_gt = filter_empty_gt
self.CLASSES = self.get_classes(classes)
# join paths if data_root is specified
if self.data_root is not None:
if not osp.isabs(self.ann_file):
self.ann_file = osp.join(self.data_root, self.ann_file)
if not (self.img_prefix is None or osp.isabs(self.img_prefix)):
self.img_prefix = osp.join(self.data_root, self.img_prefix)
if not (self.seg_prefix is None or osp.isabs(self.seg_prefix)):
self.seg_prefix = osp.join(self.data_root, self.seg_prefix)
if not (self.proposal_file is None
or osp.isabs(self.proposal_file)):
self.proposal_file = osp.join(self.data_root,
self.proposal_file)
# load annotations (and proposals)
self.data_infos = self.load_annotations(self.ann_file)
if self.proposal_file is not None:
self.proposals = self.load_proposals(self.proposal_file)
else:
self.proposals = None
# filter images too small and containing no annotations
if not test_mode:
valid_inds = self._filter_imgs()
self.data_infos = [self.data_infos[i] for i in valid_inds]
if self.proposals is not None:
self.proposals = [self.proposals[i] for i in valid_inds]
# set group flag for the sampler
self._set_group_flag()
# processing pipeline
self.pipeline = Compose(pipeline)
def __len__(self):
"""Total number of samples of data."""
return len(self.data_infos)
def load_annotations(self, ann_file): # 4
"""Load annotation from annotation file."""
return mmcv.load(ann_file)
...Tutorial에서 사용되는 부분만 가져왔으며 전체 코드는 제목에 달린 링트에서 볼 수 있습니다.
우리가 만들 dataset class는 위의 Custom dataset을 상속받아 만듭니다. 알아야할 부분을 옆에 # number 로 주석처리 했습니다. 차례대로 보겠습니다.
1. @DATASETS.register_module()
Dataset 객체를 Config에 등록합니다.
2. CLASSES = None
학습하는 데이터의 class를 알려줍니다.
3. def init(self, # 3
ann_file,
pipeline,
classes=None,
data_root=None,
img_prefix='',
seg_prefix=None,
proposal_file=None,
test_mode=False,
filter_empty_gt=True):
Config 로부터 객체 생성시 인자가 입력됩니다.
이중 특히 알아야할 것이 ann_file, data_root, img_prefix입니다. 이 인자를 통해 data 를 parsing합니다.
ann_file은 데이터의 annnotation file 명을 지정합니다.
data_root는 전체 데이터의 부모 디렉토리 주소를 넘겨줍니다.
img_prefix는 이미지 파일이 들어있는 디렉토리의 주소를 넘겨줍니다.
후에 os.path.join으로 각 path를 join하므로 절대주소를 넣어주는 것이아닌 path join시 절대주소가 되게끔 넣어주면 됩니다. 뒤에서 예시로 보겠습니다.
그런데 pascal voc format의 경우 이미지 당 1개의 annotation 파일이 있었는데, ann_file인자에는 file하나만을 넣어야합니다. 이 경우는 annotation list를 가지는 meta file을 지정해줍니다.
데이터셋은 학습용, 검증용, 테스트 용으로 각각 만들어줘야 합니다. 이때 각 데이터를 분리하는 유형은 3가지가 있습니다.
- image등과 annotation파일이 학습용, 검증용, 테스트용 디렉토리에 별도로 분리
- 별도의 메타파일에서 학습용, 검증용, 테스트용 image들과 annotation파일을 지정 (Pascal VOC)
- image들은 학습용, 검증용, 테스트용 디렉토리 별로 분리, annotation은 학습용, 검증용, 테스트용으로 하나만 가짐 (MSCOCO)
위의 3개의 인자를 이용하여 각 Dataset을 만듭니다. 주어진 각 주소를 기준으로 source dataset을 train, valid, test용으로 나누어 줍니다.
4. def load_annotations(self, ann_file):
원하는 dataset format으로 변환하는 함수입니다. 직접 customize코드를 작성해야 합니다.
kitty data set을 이용한 학습
이 역시 mmdetection github의 Tutorial에서 확인 할 수 있는 내용입니다.
새로운 detector를 학습시키려면 3가지 과정을 거쳐야합니다.
1. Support a new dataset
2. Modify the config
3. Train a new detector
첫번째 과정은 dataset을 mmdetection에서 사용할 수 있게 변환하는 과정입니다. 이때 3가지의 방법이 있습니다.
1. COCO format
2. middle format
3. implement a new dataset
2번째 방법인 middel format은 다음과 같습니다. 이 format으로 변환을 하겠습니다. 
filename: 이미지 파일명(디렉토리는 포함하지 않음)
- width: 이미지 너비
- height: 이미지 높이
- ann: bbounding box와 label에 대한 정보를 가지는 Dictionary
- bboxes: 하나의 이미지에 있는 여러 Object 들의 numpy array. 4개의 좌표값(좌상단, 우하단)을 가지고, 해당 이미지에 n개의 Object들이 있을 경우 array의 shape는 (n, 4)
- labels: 하나의 이미지에 있는 여러 Object들의 numpy array. shape는 (n, )
- bboxes_ignore: 학습에 사용되지 않고 무시하는 bboxes. 무시하는 bboxes의 개수가 k개이면 shape는 (k, 4)
- labels_ignore: 학습에 사용되지 않고 무시하는 labels. 무시하는 bboxes의 개수가 k개이면 shape는 (k,)
먼저 kitty data set을 다운 받은 후 구조를 살펴보겠습니다.
# download, decompress the data
!wget https://download.openmmlab.com/mmdetection/data/kitti_tiny.zip
!unzip kitti_tiny.zip > /dev/null# Check the directory structure of the tiny data
# Install tree first
!apt-get -q install tree
!tree kitti_tiny #디렉토리 구조 확인 3 directories, 152 files
3 directories, 152 files
training안에 image가 있고 label안에 이미지 파일과 이름이 같은 annotation txt파일이 있습니다.
import matplotlib.pyplot as plt
import cv2
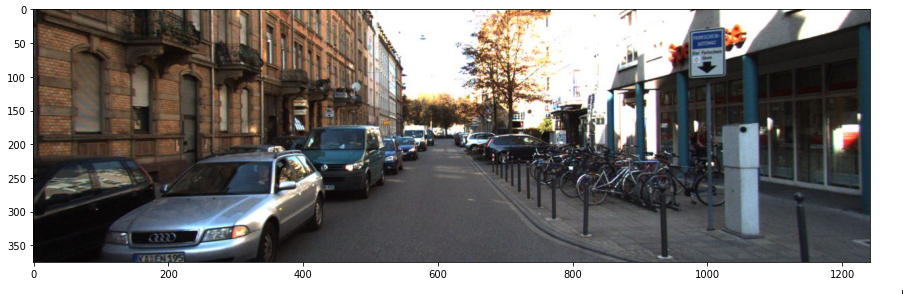
img = cv2.cvtColor(cv2.imread('./kitti_tiny/training/image_2/000068.jpeg'), cv2.COLOR_BGR2RGB)
plt.figure(figsize=(15, 10))
plt.imshow(img)
!cat ./kitti_tiny/training/label_2/000068.txt #5번째부터 8번째까지 bbox 좌표 (좌상단, 우하단)이미지와 그에 해당하는 annotation 정보입니다. 첫번째는 onject의 이름이고, 5번째 부터 8번째 까지가 bounding box의 좌상단, 우하단 좌표입니다.
Car 0.25 0 1.94 69.26 200.28 435.08 374.00 1.46 1.62 4.04 -3.00 1.79 6.98 1.55
Car 0.80 1 2.26 0.00 209.20 198.59 374.00 1.46 1.58 3.72 -5.44 1.85 6.22 1.56
Cyclist 0.97 0 2.34 1210.28 199.77 1241.00 374.00 1.55 0.57 1.73 4.04 1.69 3.57 -3.14
Car 0.00 2 1.68 478.18 187.68 549.54 249.43 1.57 1.60 3.99 -2.73 2.03 20.96 1.55
Car 0.00 1 1.66 530.03 187.79 573.10 226.09 1.52 1.54 3.68 -2.53 2.20 31.50 1.58
Van 0.00 1 1.63 547.61 171.12 584.05 212.41 2.47 1.98 5.81 -2.79 2.41 46.44 1.57
Car 0.00 1 -0.16 667.74 182.35 790.82 230.38 1.62 1.65 4.14 4.19 1.99 25.95 0.00
Car 0.00 2 -0.11 657.37 184.48 763.34 221.64 1.55 1.66 4.47 4.35 2.10 32.00 0.02
Car 0.00 1 -0.01 637.45 180.34 714.44 212.34 1.69 1.76 4.12 3.59 2.12 39.79 0.08
Van 0.00 1 1.61 572.52 175.02 596.26 199.95 2.13 1.91 6.40 -2.28 2.36 65.43 1.57
Van 0.00 1 1.77 380.78 167.69 523.29 288.56 1.95 1.75 4.63 -2.89 1.90 14.05 1.57
Cyclist 0.00 1 1.09 958.95 167.55 1036.88 254.43 1.68 0.53 1.96 7.95 1.59 14.95 1.57
!cat ./kitti_tiny/train.txt000000
000001
000002
000003
000004
000005
000006
000007
000008
000009
000010
000011
000012
000013
000014
000015
000016
000017
000018
000019
000020
000021
000022
000023
000024
show more (open the raw output data in a text editor) ...
000045
000046
000047
000048
000049
train.txt에는 annotation file의 리스트를 가지고 있습니다. 0부터 49까지 50개의 file을 train에 사용한다는 것을 알 수 있습니다. val.txt도 확인해보면 50부터 74까지의 list가 있습니다.
CustomDataset을 상속받아 Dataset 생성하기
import copy
import os.path as osp
import cv2
import mmcv
import numpy as np
from mmdet.datasets.builder import DATASETS
from mmdet.datasets.custom import CustomDataset
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
cat2label = {k:i for i, k in enumerate(CLASSES)}
# 반드시 아래 Decorator 설정 할것.@DATASETS.register_module() 설정 시 force=True를 입력하지 않으면 Dataset 재등록 불가.
@DATASETS.register_module(force=True)
class KittyTinyDataset(CustomDataset):
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
##### self.data_root: ./kitti_tiny/ self.ann_file: ./kitti_tiny/train.txt self.img_prefix: ./kitti_tiny/training/image_2
#### ann_file: ./kitti_tiny/train.txt
# annotation에 대한 모든 파일명을 가지고 있는 텍스트 파일을 __init__(self, ann_file)로 입력 받고, 이 self.ann_file이 load_annotations()의 인자로 입력
def load_annotations(self, ann_file):
print('##### self.data_root:', self.data_root, 'self.ann_file:', self.ann_file, 'self.img_prefix:', self.img_prefix)
print('#### ann_file:', ann_file)
cat2label = {k:i for i, k in enumerate(self.CLASSES)}
image_list = mmcv.list_from_file(self.ann_file)
# 포맷 중립 데이터를 담을 list 객체
data_infos = []
for image_id in image_list:
filename = '{0:}/{1:}.jpeg'.format(self.img_prefix, image_id)
# 원본 이미지의 너비, 높이를 image를 직접 로드하여 구함.
image = cv2.imread(filename)
height, width = image.shape[:2]
# 개별 image의 annotation 정보 저장용 Dict 생성. key값 filename 에는 image의 파일명만 들어감(디렉토리는 제외)
data_info = {'filename': str(image_id) + '.jpeg',
'width': width, 'height': height}
# 개별 annotation이 있는 서브 디렉토리의 prefix 변환.
label_prefix = self.img_prefix.replace('image_2', 'label_2')
# 개별 annotation 파일을 1개 line 씩 읽어서 list 로드
lines = mmcv.list_from_file(osp.join(label_prefix, str(image_id)+'.txt'))
# 전체 lines를 개별 line별 공백 레벨로 parsing 하여 다시 list로 저장. content는 list의 list형태임.
# ann 정보는 numpy array로 저장되나 텍스트 처리나 데이터 가공이 list 가 편하므로 일차적으로 list로 변환 수행.
content = [line.strip().split(' ') for line in lines]
# 오브젝트의 클래스명은 bbox_names로 저장.
bbox_names = [x[0] for x in content]
# bbox 좌표를 저장
bboxes = [ [float(info) for info in x[4:8]] for x in content]
# 클래스명이 해당 사항이 없는 대상 Filtering out, 'DontCare'sms ignore로 별도 저장.
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
for bbox_name, bbox in zip(bbox_names, bboxes):
# 만약 bbox_name이 클래스명에 해당 되면, gt_bboxes와 gt_labels에 추가, 그렇지 않으면 gt_bboxes_ignore, gt_labels_ignore에 추가
if bbox_name in cat2label:
gt_bboxes.append(bbox)
# gt_labels에는 class id를 입력
gt_labels.append(cat2label[bbox_name])
else:
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
# 개별 image별 annotation 정보를 가지는 Dict 생성. 해당 Dict의 value값은 모두 np.array임.
data_anno = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.long),
'bboxes_ignore': np.array(gt_bboxes_ignore, dtype=np.float32).reshape(-1, 4),
'labels_ignore': np.array(gt_labels_ignore, dtype=np.long)
}
# image에 대한 메타 정보를 가지는 data_info Dict에 'ann' key값으로 data_anno를 value로 저장.
data_info.update(ann=data_anno)
# 전체 annotation 파일들에 대한 정보를 가지는 data_infos에 data_info Dict를 추가
data_infos.append(data_info)
return data_infos위에서 설명한 CustomDataset class를 상속받아 Datasetclass 를 만드는 코드입니다. init이 없는 이유는 CustomDataset init을 그대로 사용하기 때문입니다.
load_annotations가 우리가 가진 데이터셋 format을 middle format으로 바꾸어주는 코드입니다. middle format을 다시 보겠습니다.

코드를 보겠습니다.
kitti의 annotation file은 train.txt와 val.txt였으므로 이를 ann_file인자로 넘겨주게됩니다.
data_root는 ./kitti_tiny/
img_prefix는 ./kitti_tiny/training/image_2 입니다.
for image_id in image_list:
filename = '{0:}/{1:}.jpeg'.format(self.img_prefix, image_id)
# 원본 이미지의 너비, 높이를 image를 직접 로드하여 구함.
image = cv2.imread(filename)
height, width = image.shape[:2]
# 개별 image의 annotation 정보 저장용 Dict 생성. key값 filename 에는 image의 파일명만 들어감(디렉토리는 제외)
data_info = {'filename': str(image_id) + '.jpeg',
'width': width, 'height': height}
# 개별 annotation이 있는 서브 디렉토리의 prefix 변환.
label_prefix = self.img_prefix.replace('image_2', 'label_2')
# 개별 annotation 파일을 1개 line 씩 읽어서 list 로드
lines = mmcv.list_from_file(osp.join(label_prefix, str(image_id)+'.txt'))midle format의 filename, width, height을 채우기 위해 이름과 cv2로 이미지를 읽어 이미지 크기를 data_info dict에 저장합니다.
개별 annotation정보인 'ann' dictionary를 만들기 위해 ./kitti_tiny/training/image_2로 넘겨주었던 마지막 부분을 label2로 바꾸고, 각 img file별 anntation file에 있는 내용을 list로 받아옵니다.
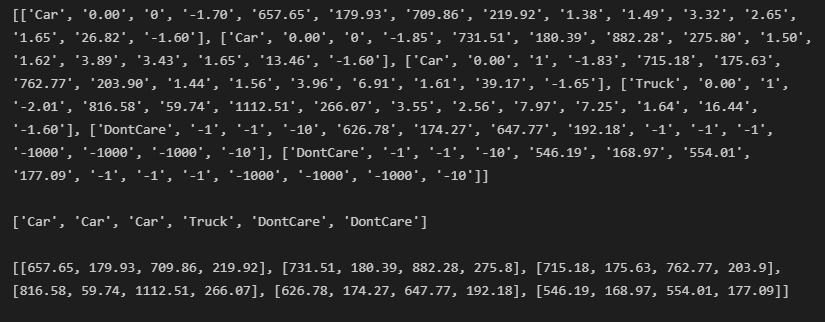
lines = mmcv.list_from_file('./kitti_tiny/training/label_2/000064.txt') print(lines) 
# 전체 lines를 개별 line별 공백 레벨로 parsing 하여 다시 list로 저장. content는 list의 list형태임.
# ann 정보는 numpy array로 저장되나 텍스트 처리나 데이터 가공이 list 가 편하므로 일차적으로 list로 변환 수행.
content = [line.strip().split(' ') for line in lines]
# 오브젝트의 클래스명은 bbox_names로 저장.
bbox_names = [x[0] for x in content]
# bbox 좌표를 저장
bboxes = [ [float(info) for info in x[4:8]] for x in content]띄어쓰기로 구분된 line을 각 object별 annotation정보를 원소로 가지는 2차원 list인 content로 변환합니다.
bbox_names는 그중 object의 이름만, bboxes는 bbox좌표만 가져온 1차원, 2차원 list입니다.
# 클래스명이 해당 사항이 없는 대상 Filtering out, 'DontCare'sms ignore로 별도 저장.
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
for bbox_name, bbox in zip(bbox_names, bboxes):
# 만약 bbox_name이 클래스명에 해당 되면, gt_bboxes와 gt_labels에 추가, 그렇지 않으면 gt_bboxes_ignore, gt_labels_ignore에 추가
if bbox_name in cat2label:
gt_bboxes.append(bbox)
# gt_labels에는 class id를 입력
gt_labels.append(cat2label[bbox_name])
else:
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
# 개별 image별 annotation 정보를 가지는 Dict 생성. 해당 Dict의 value값은 모두 np.array임.
data_anno = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.long),
'bboxes_ignore': np.array(gt_bboxes_ignore, dtype=np.float32).reshape(-1, 4),
'labels_ignore': np.array(gt_labels_ignore, dtype=np.long)
}
# image에 대한 메타 정보를 가지는 data_info Dict에 'ann' key값으로 data_anno를 value로 저장.
data_info.update(ann=data_anno)
# 전체 annotation 파일들에 대한 정보를 가지는 data_infos에 data_info Dict를 추가
data_infos.append(data_info)bbox 별로 미리 정해준 class에 해당하면 gt_bboxes와 gt_labels에 추가, 그렇지 않으면 gt_bboxes_ignore, gt_labels_ignore에 추가합니다. 이후 개별 image별 annotation 정보를 가지는 Dict 생성하고 전체 dict를 update한 후 return 합니다.
