강의 내용 복습
(01강) Object Detection Overview
Classification vs object detection vs Sementic Segmentation vs Instance Segmentation


object detection History

evaluation
성능
mAP (mean average precision)
mAP를 계산하기 위해 필요한 개념
-
confusion matrix

-
Precision & Recall
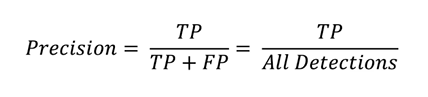
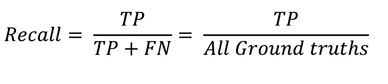
Precision : bbox 검출한 것 중에 맞게 예측한 것
Recall : GT 중에 맞게 bbox 검출한 것 -
PR Curve
 예측들에 대해 맞았는지 틀렸는지 검출하고 각 confidence 알수 있을 때
예측들에 대해 맞았는지 틀렸는지 검출하고 각 confidence 알수 있을 때
 이를 내림차순으로 정렬한 후 누적 TP,FP 로 Precision, Recall 계산
이를 내림차순으로 정렬한 후 누적 TP,FP 로 Precision, Recall 계산
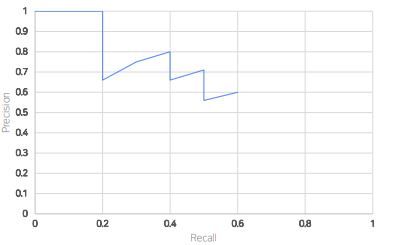 x축 Recall, y축 Precision으로 하여 그래프 그리기
x축 Recall, y축 Precision으로 하여 그래프 그리기즉 모든 예측에 대해 confience score로 내림차순 정렬 한 후 누적TP,FP 를 이용하여 Precision, Recall 구해서 그래프로 그리면 PR Curve
-
AP (Average Precision)
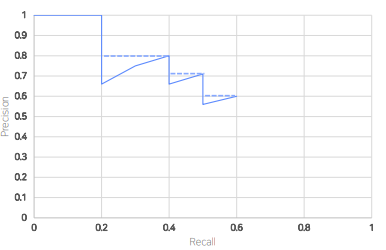
 아래면적 계산 = AP : 0~1 값을 갖는 metric
아래면적 계산 = AP : 0~1 값을 갖는 metric
 mAP : 모든 객체의 AP의 평균
mAP : 모든 객체의 AP의 평균 -
IOU (Intersection Over Union)

mAP in Object Detection
mAP50, mAP70 ... : IOU가 50, 70일떄의 mAP 를 뜻함
속도
-
FPS (Frames Per Second)
초당 처리할 수 있는 frame의 갯수 -
FLOPs (Floating Point Operations)
model 이 얼마나 빠르게 동작하는 지 측정하는 연산량의 횟수 : 작을 수록 좋음
Library
- MMDetection : pytroch 기반 object detection 오픈소스
- Detectron2 : 페이스북 AI 리서치의 라이브러리로 pytorch 기반의 Object detection과
segmentation의 알고리즘을 제공 - YOLOv5 : coco 데이터셋으로 사전 학습된 모델로 수천 시간의 연구와 개발에 걸쳐 발전된 Object Detection 모델
Colab, kaggle, Docker, AWS, Google Cloud Platform 등 에서 오픈 소스를 제공 - EfficientDet : Google Research & Brain에서 연구한 모델로 EfficientNet을 응용해 만든 Object Detection 모델
Tensorflow로 제공되는 EfficientDet을 사용할 수 있으며, 깃헙에 pytorch 기반으로 구현된
라이브러리 역시 존재
(02강) 2 Stage Detectors
resion prposal - object clf
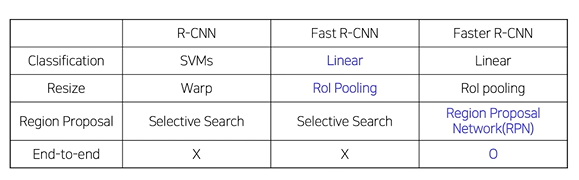
R-CNN
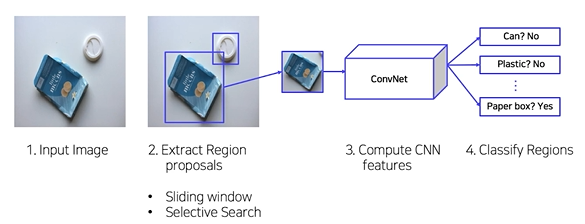
- selective search 사용
pipeline
1. 입력이미지 준비
2. Selective Search를 통해 약 2000개의 RoI(Region of Interest)를 추출
3. RoI(Region of Interest)의 크기를 조절해 모두 동일한 사이즈로 변형 (FC layer 입력사이즈 고정이므로)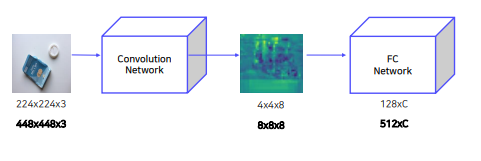
4. RoI를 CNN에 넣어, feature를 추출
- 각 region마다 4096-dim feature vector 추출 (2000x4096)
• Pretrained AlexNet 구조 활용
• AlexNet 마지막에 FC layer 추가
• 필요에 따라 Finetuing 진행
5-1. CNN을 통해 나온 feature를 SVM에 넣어 분류 진행
• Input : 2000 x 4096 features
• Output : Class (C+1) + Confidence scores
• 클래스 개수(C개) + 배경 여부(1개)
5-2) CNN을 통해 나온 feature를 regression을 통해 bounding box를 예측

요약
1) 2000개의 Region을 각각 CNN 통과 -> 연산량 너무 많아 시간 오래걸림
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로 학습
4) End-to-End X
SPPNet
- CNN 연산 딱 한번
- spatial pyramid layer로 이미지 크기 고정하여 warping 필요 없음
spatial pyramid layer
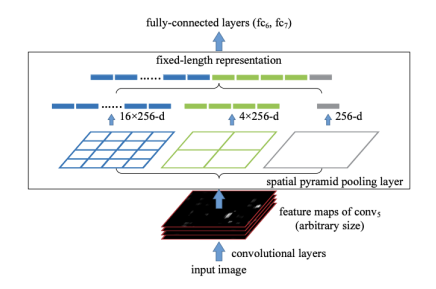
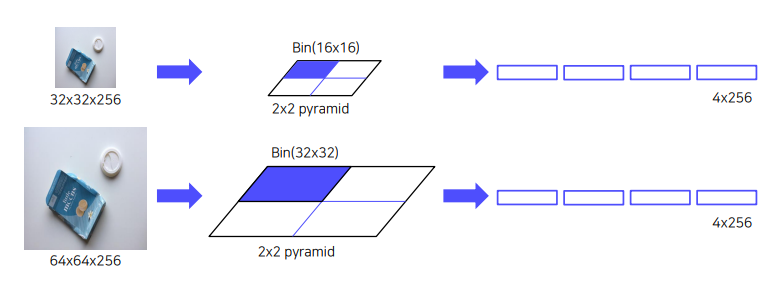 이미지를 binning으로 나누어 각 cell에서 pooling으로 feature를 뽑음
이미지를 binning으로 나누어 각 cell에서 pooling으로 feature를 뽑음
요약
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X
Fast R-CNN
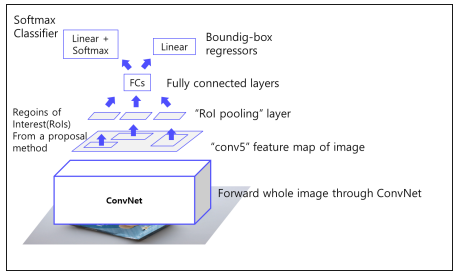
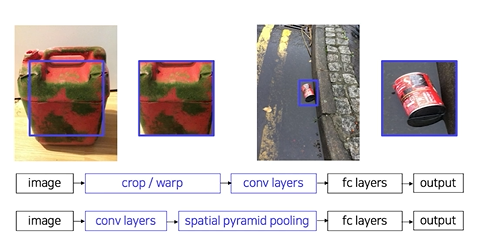
-ROI Pooling으로 고정된 크기의 feaure map 얻음
pipeline
1. 이미지를 CNN에 넣어 feature 추출 (CNN을 한 번만 사용) : VGG16 사용
2. RoI Projection을 통해 feature map 상에서 RoI를 계산
- RoI Projection

- 원본이미지에서 selective search로 2000개의 region 얻음
- 얻은 region을 CNN을 통해 얻은 feature map에 그대로 projection / 만약 원본이미지와 feature map의 크기가 다르다면 후보 region역시 같은 비율로 축소해서 projection
- RoI Pooling을 통해 일정한 크기의 feature가 추출
- SPP 사용 , SPP Net에서의 Pyramid level은 1x1, 2x2, 4x4 여러가지 였지만 Fast R-CNN에서는 7x7 하나만 사용 = pyramid level = 1 / Target grid size = 7x7
- Fully connected layer 이후, Softmax Classifier과 Bouding Box Regressor
• 클래스 개수: C+1개
• 클래스 (C개) + 배경 (1개)
요약
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X
Faster R-CNN
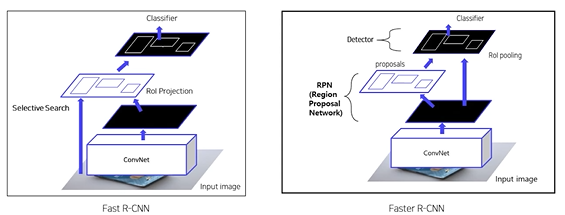
- selective search 대신 RPN 도입하여 region proposal 부분도 학습가능하도록 함
pipeline
1. 이미지를 CNN에 넣어 feature maps 추출 (CNN을 한 번만 사용)
2. RPN을 통해 RoI 계산
- 기존의 selective search 대체
- Anchor box 개념 사용
 CNN으로 feature map얻은 후 grid로 나누고, 각 cell 마다 다양한 크기와 비율을 가진 n개의 ancher box를 가지고 있음
CNN으로 feature map얻은 후 grid로 나누고, 각 cell 마다 다양한 크기와 비율을 가진 n개의 ancher box를 가지고 있음
RPN이 하는 일
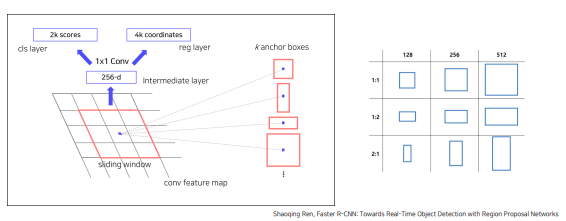
anchor box너무 많고, anchor box 좌표가 객체에 정확히 맞지 않음 -> anchor box별로 object를 포함하는지 판별 + 좌표(중심점, 가로, 세로) 미세조정 필요
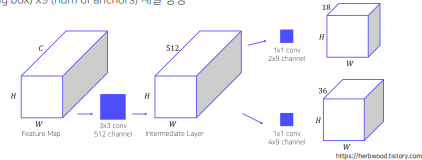
2-1. CNN에서 나온 feature map을 input으로 받음. (𝐻: 세로, 𝑊: 가로, 𝐶: 채널)
2-2. 3x3 conv 수행하여 intermediate layer 생성
2-3. 1x1 conv 수행하여 binary classification 수행
- 2 (object or not) x 9 (num of anchors) 채널 생성
- 4 (bounding box) x9 (num of anchors) 채널 생성
최종 pipeline
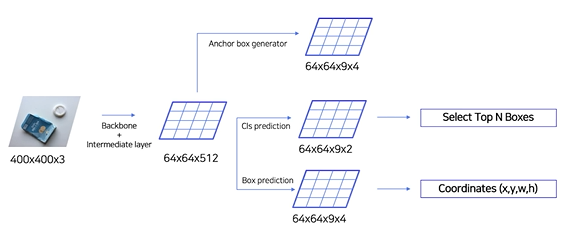
NMS
• 유사한 RPN Proposals 제거하기 위해 사용
• Class score를 기준으로 proposals 분류
• IoU가 0.7 이상인 proposals 영역들은 중복된 영역으로 판단한 뒤 제거
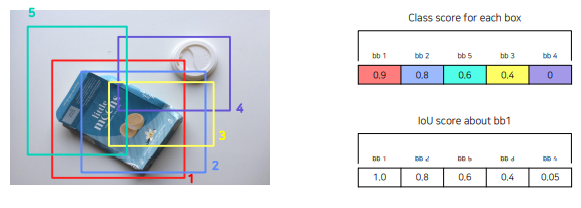
bb1 을 기준으로 IOU를 계산하여 미리 정해둔 threshold = 0.7 이상인 bbox=bb2를 제거
result
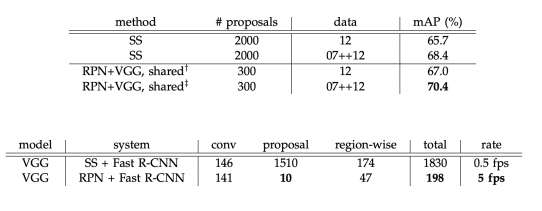
SS로 2000개의 region을 뽑은 것 보다 RPN으로 300개의 region을 뽑은 것이 mAP가 더 좋음
fps 속도 또한 ss보다 RPN이 더 빠름
요약
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X
하지만 여전히 region proposal + clf/reg 2 step이로 이루어져 있기 때문에 속도 가 느려 실시간으로는 사용할 수 없음
summary
Further Reading
RCNN Paper
Fast RCNN Paper
Faster RCNN Paper
https://herbwood.tistory.com/
(03강) (03강) Object Detection Library
통합된 라이브러리 없음
kaggle/실무에서는 MMDetection, Detectron2 사용
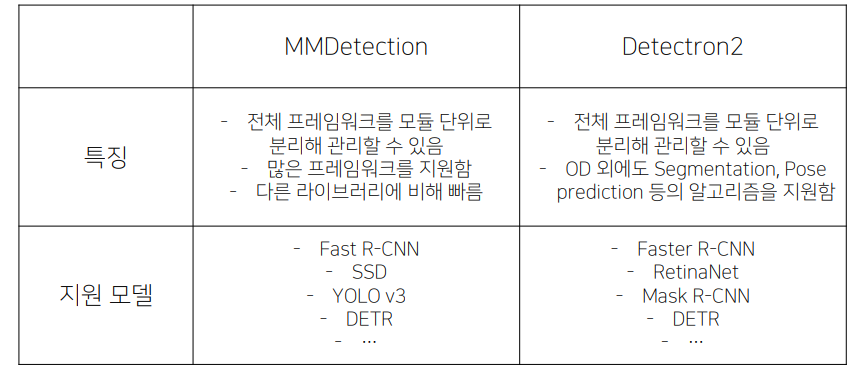
MMDetection
pipeline
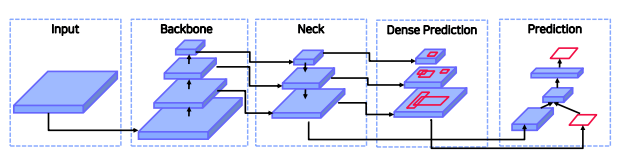
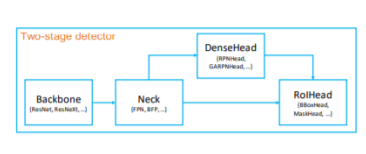
- 2 Stage 모델은 크게 Backbone / Neck /
DenseHead / RoIHead 모듈로 나눌 수 있음
Backbone : 입력 이미지를 특징 맵으로 변형
Neck : backbone과 head를 연결, Feature map을 재구성 (ex.FPN)
DenseHead : 특징 맵의 dense location을 수행하는 부분
RoIHead : RoI 특징을 입력으로 받아 box분류, 좌표 회귀 등을 예측하는 부분 - 각각의 모듈 단위로 커스터마이징
- 이러한 시스템은 config 파일을 이용해 통제됨
Config file
- 데이터 셋, 모델, 스케쥴러, optimizer 정의 가능
- 다양한 obj det 모델의 config 파일 정의되어 있음
- configs/base/ 폴더에 가장 기본이 되는 config 파일이 존재 : dataset, model, schedule, default_runtime 4가지 기본 구성요소 존재
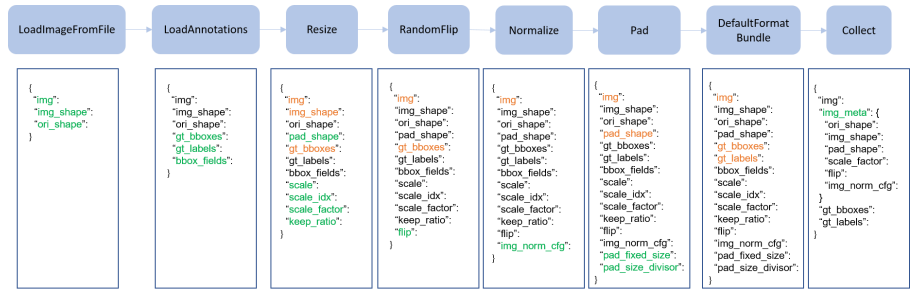
dataset
- samples_per_gpu
- workers_per_gpu
- traia, val, test
- data pipeline
model
2stage model
- type :
- backbone : feature map을 얻는 네트워크
- neck : backbone과 head를 연결, feature map 재구성
- rpn_head : region proposal network
- roi_head : region of interest
- bbox_head
- train_cfg
- test_cfg
새로운 backbone 등록 가능
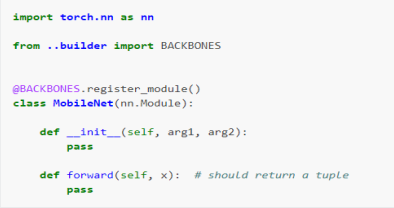
module import
등록한 backbone 사용
run time setting
optimizer
learning rate, runner
Detectron2
Facebook AI Research의 Pytorch 기반 라이브러리
Object Detection 외에도 Segmentation, Pose prediction 등 알고리즘도 제공
pipeline
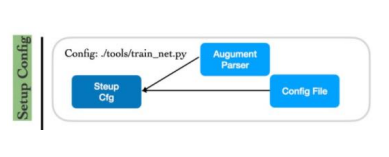
Setup Config / Setup Trainer / Start Training
과제 수행 과정 및 결과
피어 세션
학습 회고
