강의 내용 복습
(10강) Object Detection in Kaggle
1. Global Wheat Detection
1.1 overview

key-point
• Too small box
• No bounding box image 포함
1.2 solution
• Custom mosaic data augmentation
• MixUp
• Heavy augmentation
• Data cleaning
• EfficientDet
• Faster RCNN with FPN
• Ensemble multi-scale model through Weighted-Boxes-Fusion
• Test time augmentation (HorizontalFlip, VerticalFlip, Rotate90)
• Pseudo labeling
2. VinBigData Chest X-ray Abnormalities Detection
2.1 overview
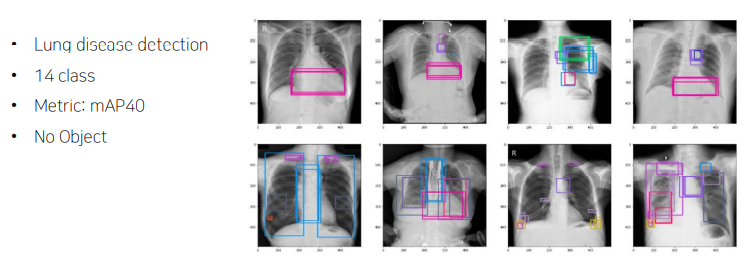
Key point
• Train 데이터의 경우 5명의 전문가가 labeling
• 한 위치에 여러 개 box가 존재
• Preprocess
• Tests 데이터의 경우 3명의 전문가가 판별했을 때 겹치는
Box만 labeling
• 리더보드 점수가 많이 낮기 때문에 다양한 모델 앙상블 필요
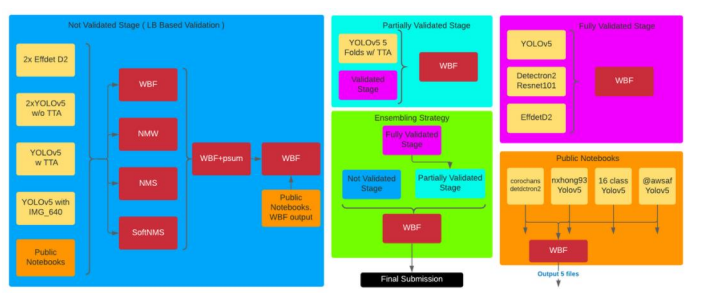
2.2 solution
1st solution summary
• 1) Baseline
• FasterRCNN with FPN using Detectron2
• 2) WBF ensemble with yolov5
• Huge mAP gain !
• 3) Ensemble with other yolo fold and other yolo hyperparameters
• Huge mAP gain !
• There are no validations …
2nd solution about MMDetection
• Grid Search
• ATSS
• Cascade RFP : ResNet 50
• GFL :ResNet 101, ResNext 101
• RetinaNet : ResNext 101
• UniverseNet
• Training tricks
Albumentation
• ShiftScaleRotate, IAAAffine, Blur/GaussianBlur/MedianBlur, RandomBrightnessContrast,
IAAAdditiveGaussianNoise/GaussNoise, HorizontalFlip.
• 1024 x 1024로 모든 model을 학습 이후 작은 박스를 잘 잡기 위해서 2048 x 2048로 파인튜닝
• FP16을 사용하여 speed와 batch size 모두 늘림
• CosineAnnealing보다 stepLR 스케쥴러가 더 좋은 성능 향상
• Class Balanced Dataset을 사용 but 성능 향상은 없음
• 2-step training
1) 모든 data를 활용해 30 epoch 동안 학습 후 best checkpoint를 저장
2) 전문가 별로 박스를 몇 개 라벨링 했는 지 계산 가능
3) 이때 박스를 적게 친 전문가(rare radiologists)들이 친 이미지를 학습 데이터로 파인튜닝
• Model scores
• GFL_R101_1024 : 0.239 / 0.248
• GFL_X101_1024 : 0.264 / 0.255
• Cascade_RFP_R50 : 0.251 / 0.243
• RetinaNet : 0.228 / 0.239
• GFL_R101_2048 : 0.248 / 0.235
• GFL_X101_2048 : 0.256 / 0.238
• Conclusion
• Preprocess boxes using WBF methods
• WBF ensembles different models
• Yolov5 * 2, RetinaNet-101, RetinaNet-512, CenterNet, FasterRCNN
• Investigation mAP• OOF(out-of-folds)를 가지고, 각 클래스 별 AP를 계산 (local score)
• 이후, AP가 낮은 클래스에 대해 해당 클래스의 AP가 왜 낮은지 조사
• 조사 결과, 해당 클래스를 라벨링한 전문가 별로 AP가 극명하게 나뉘는 것을 확인
• 이에 전문가 별로 어떻게 라벨링 했는지 EDA후 결과 확인
• 확인 결과, AP가 낮은 전문가들이 실제 객체보다 더 큰 박스를 치는 습관이 있음을 확인
• 이에 위 전문가들의 박스의 크기를 원래 박스보다 작게 변형 후 학습
• 성능에 큰 향상 !
3. SIIM-FISABIO-RSNA COVID-19 Detection
3.1 overview
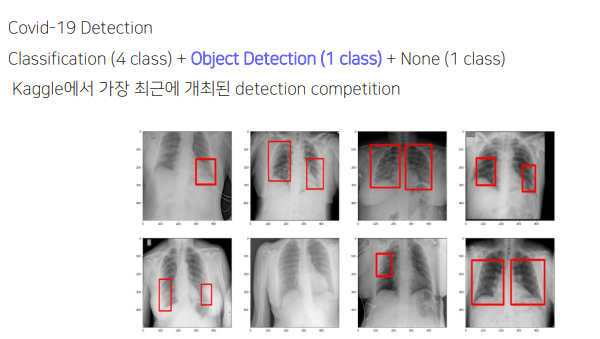
3.2 solution
1st solution
Train masks from boxes
• Boxes를 각 마스크로 해서 segmentation pretraining 진행
• 모델이 박스에 대한 semantic을 좀 더 이해하기를 기대함
• Augmentation
• Scale, RandomResizedCrop, Rotate(maximum 10 degrees), HorizontalFlip, VerticalFlip, Blur, CLAHE,
IAASharpen, IAAEmboss, RandomBrightnessContrast, Cutout, Mosaic, Mixup
• Focal Loss
• TTA
• Ensemble
• Yolo V5 (1stage detection) input size 768
• EfficientDet input size 768
• Faster RCNN resnet 101 input size 1024
• Faster RCNN resnet 200 input size 768
Summary
• 모델 다양성은 정말로 중요하다!
• Resolution, Model(Yolo, Effdet, CornerNet, FasterRCNN), Library …
• Heavy augmentations은 거의 필수적이다!
• 탑 솔루션들의 공통된 augmentations에는 무엇이 있을까?
• CV Strategy를 잘 세우는 것은 shake up 방지에 있어서 정말 중요하다!
• 체계적인 실험 역시 정말 중요하다!
• Team up은 성능향상의 엄청난 키가 될 수 있다!
• 단, 서로 다른 베이스라인을 갖는 경우!
과제 수행 과정 및 결과
피어 세션
성능향상을 위한 방법 적용해보기
학습 회고
keep
mmdetection열심히 공부하고 실험해보기
problem
코드짜는 속도가 느리고 이론공부하는데 시간ㄹ을 다써서 정작 실험을 몇번 못해봤다.
try
일단 코드로 해보고 관련 내용은 차차 알아보자
