강의 내용 복습
(01강) Introduction
경진대회
Trash Annotations for Sementic Segmentation
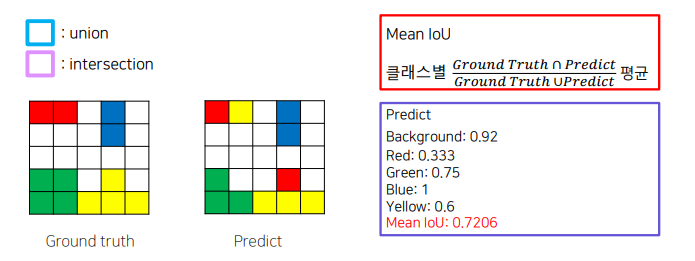
metric
mIOU
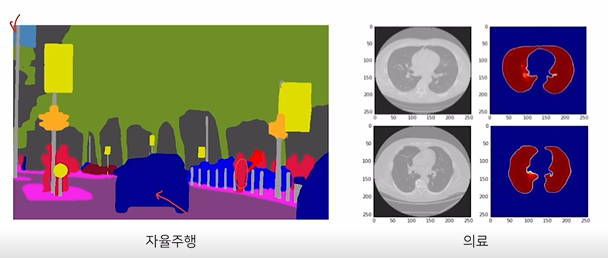
Semantic Segmetation과 다른분야 비교
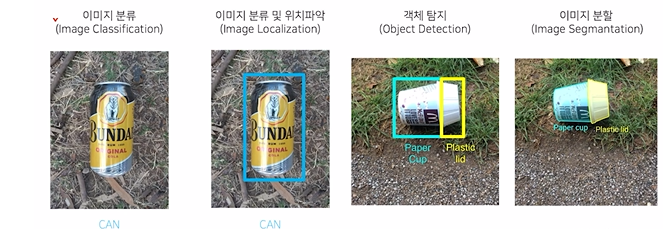
Semantic Segmetation 활용분야
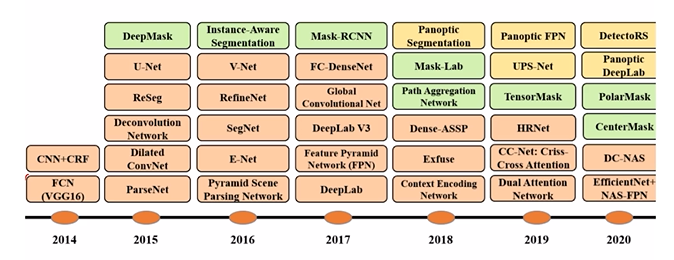
Semantic Segmetation history
(02강) Competition Overview (EDA & Metric)
COCO dataset
COCO Data set의 각각의 image의 annotation 값은 “train.json” 파일에 존재
-
COCO Format - info
“Info”에는 data set에 대한 high-level의 정보가 포함되어 있음
-
COCO Format – licenses“licenses”에는 image의 license 목록이 포함되어 있음

-
COCO Format – images“images”에 data set의 image 목록 및 각각의 width,heigh,file_name,id(image_id)등을포함

-
COCO Format – categories
“categories”에는 class에 해당하는 id, name 및 supercategory가 포함돼 있음
-
COCO Format – annotations – segmentation
“segmentation”에는 각 class에 해당되는 pixel의 x, y 좌표들이 포함되어 있음

-
Segmentation에서 필요한 image 및 target에 대한 이해
• Shape of Images : (batch, 3, height, width)
• Shape of targets : (batch, height, width)
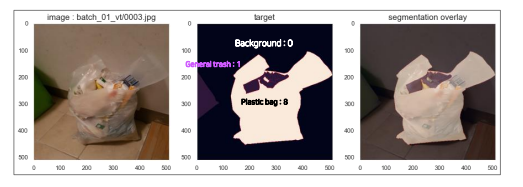
- CustomDataLoader
• data_dir : 데이터셋 경로 (e.g. train.json)
• mode : 생성될 객체의 용도가 train인지 test인지 분기
• mode=“train” → (images, masks, image_infos)
• mode=“test” → (images, image_infos)
• transform :
• image size 조절 및 data format 변환 등의 전처리 작업
mode = train인 경우 image data(batch, 3, height, width) 및 target 데이터(batch, height, width) 생성
get_item
coco.getImgIds : index로 이미지 아이디 얻음
coco.loadImgs(img id) : img id를 입력으로 넣어 image info 얻음
cv2 imread, cvtcolor로 이미지 불러옴
coco.getAnnIds, loadAnns -> annotation정보
coco.getCatIds, loadCats -> category 정보
mask : size가 (height, value)인 2D arr, 각 pixel에는 category id 할당, background = 0 /
segmentation 영역 기준 내림차순 sort 하여 저장
transform
mode=train : images, mask ToTensor
mode=test : image, image_info ToTensor
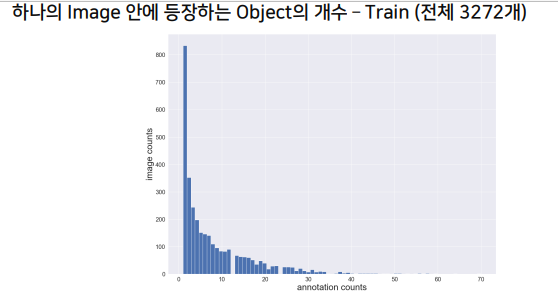
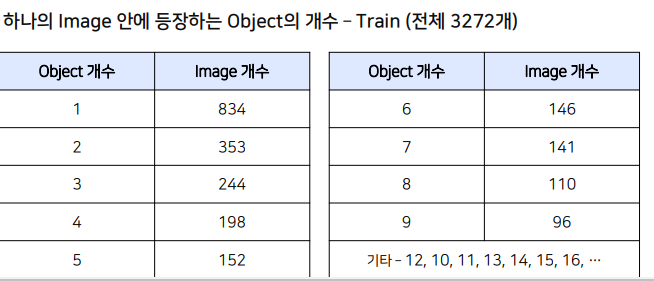
EDA

paper-paper bag
plastic-plastic bag 유사한 class 주의
plastic, plastic bag은 plastic으로 라벨린






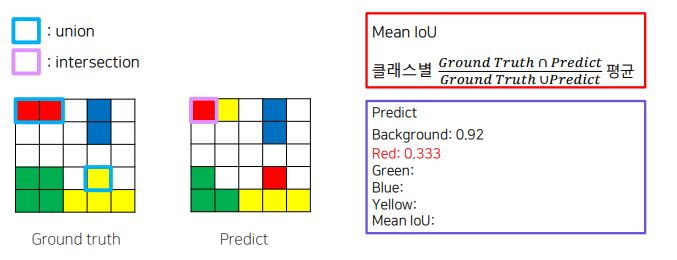
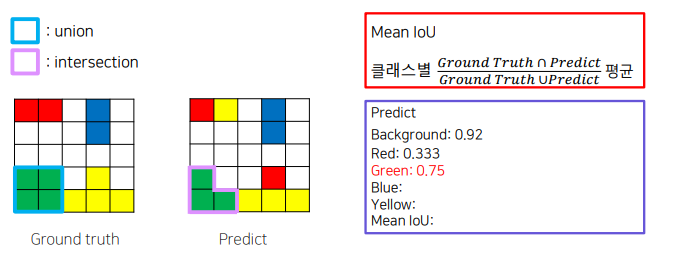
평가 metric : mIOU
Baseline code
4.1 torchvision.models.segmentation.fcn_resnet50
torchvision 모델 불러오고
마지막 classifier class 갯수 맞춰주기
4.2 loss / optimizer 설정
loss - softmax + cross entropy loss
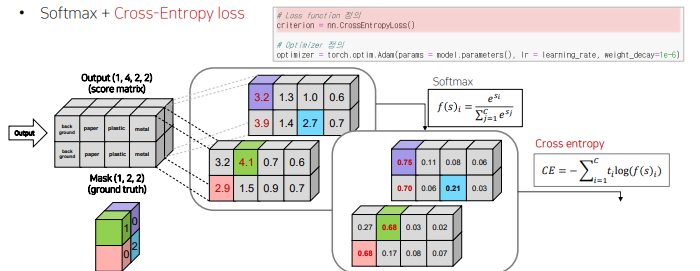
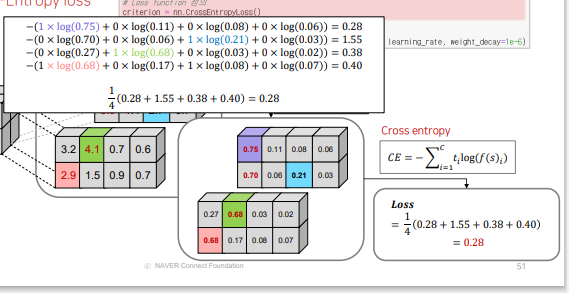
optimizer = Adam
4.3 train / validation 함수 정의
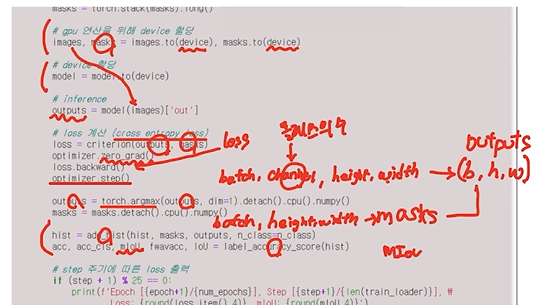
4.4 학습 시키기
앞에서 선언된 변수 및 모델을 활용하여 학습 진행
4.5 best model 불러오기
miou 기준 beat모델 저장, 불러오기
4.6 test
각 class 별로 잘 inference하고 있는지 EDA
// Battery, Clothing 잘 분류 안됨
Ref
(03강) Semantic Segmentation의 기초와 이해
1. 대표적인 딥러닝을 이용한 세그멘테이션 FCN
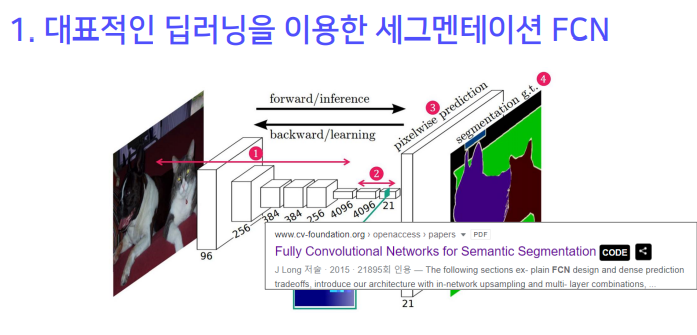
특징
1. VGG 네트워크 백본을 사용 (Backbone : feature extracting network) - VGG,Alex,Res, Efficient
2. VGG 네트워크의 FC Layer (nn.Linear)를 Convolution 으로 대체
3. Transposed Convolution을 이용해서 Pixel Wise prediction을 수행
1.1 Abstract
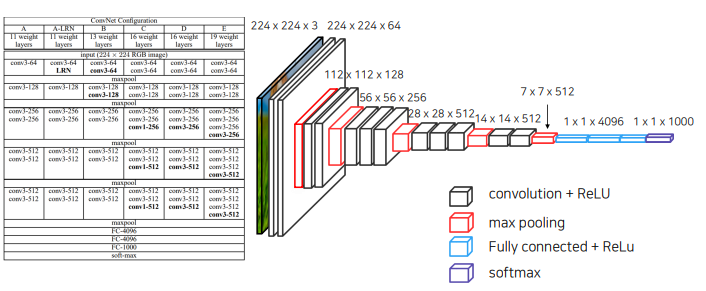
미리 학습된(성능이 좋은) 가중치 사용 가능
FC-> conaolution으로 바꾼것의 의미 -> 1.2
1.2 Fully Connected Layer vs Convolution Layer
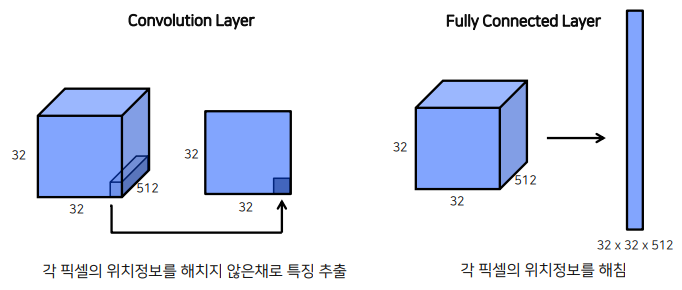 FCN은 flatten이후에 fc layer를 적용하므로 위치정보 해침
FCN은 flatten이후에 fc layer를 적용하므로 위치정보 해침
 1x1 Convolution을 사용할 경우, 임의의 입력값에 대해서도 상관 없는 이유
1x1 Convolution을 사용할 경우, 임의의 입력값에 대해서도 상관 없는 이유
-> Convolution은 kernel의 파라미터에 의해 영향을 받고, 이미지 혹은 레이어의 크기에 대해서는 상관 없음
1.3 Transposed Convolution
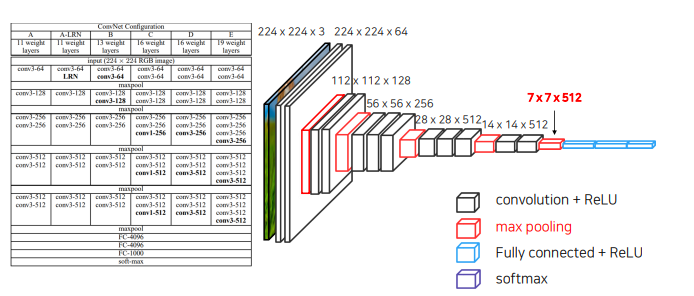 7x7 로 줄어든 image를 다시 224x224 크기로 늘려줘야 함 -> UpSampling -> Transposed Convolution
7x7 로 줄어든 image를 다시 224x224 크기로 늘려줘야 함 -> UpSampling -> Transposed Convolution
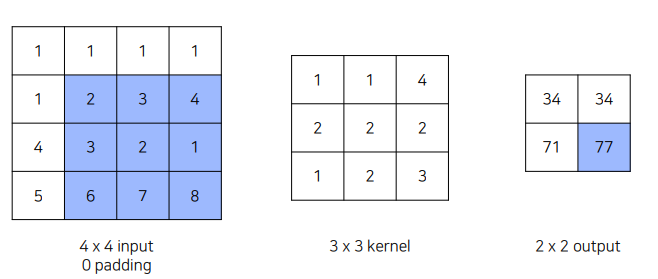
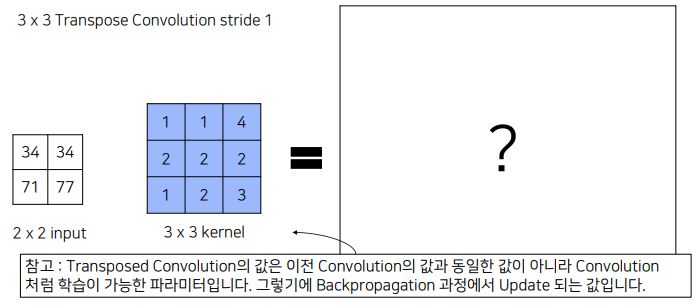 2x2 inpu과 kernel을 곱해 더 큰 output 만듬
2x2 inpu과 kernel을 곱해 더 큰 output 만듬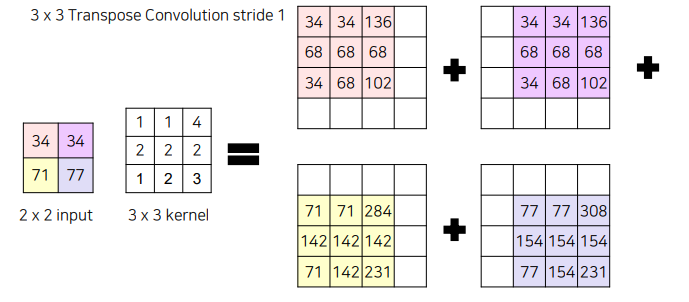
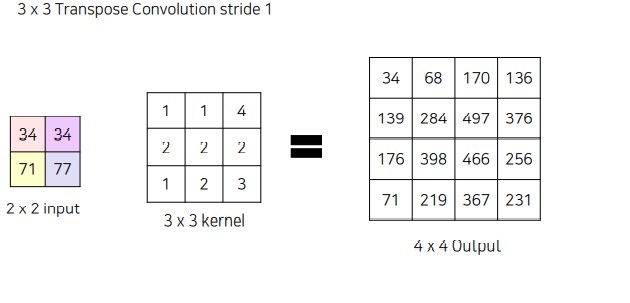 겹치는 부분은 그냥 더해줌
겹치는 부분은 그냥 더해줌
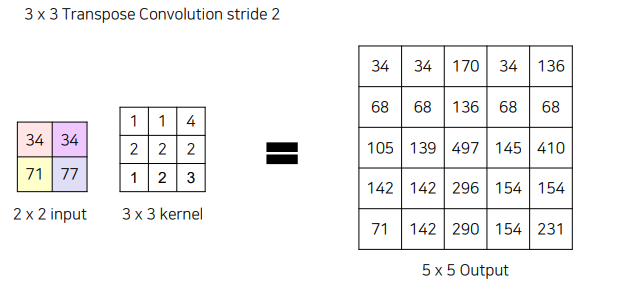
5x5 output을 만들고 싶다면 stride = 2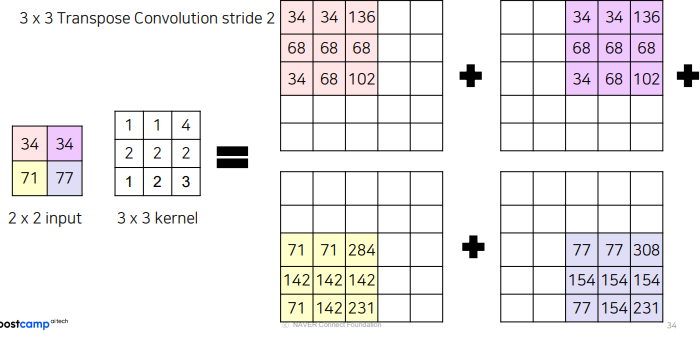
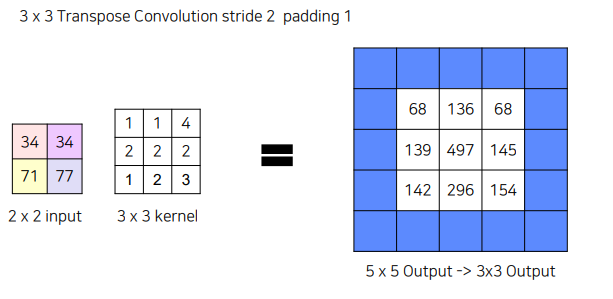 stride 2, padding 1 넣어주면 최종 결과는 내부의 3x3만 남게됨
stride 2, padding 1 넣어주면 최종 결과는 내부의 3x3만 남게됨
Transposed Convolution?

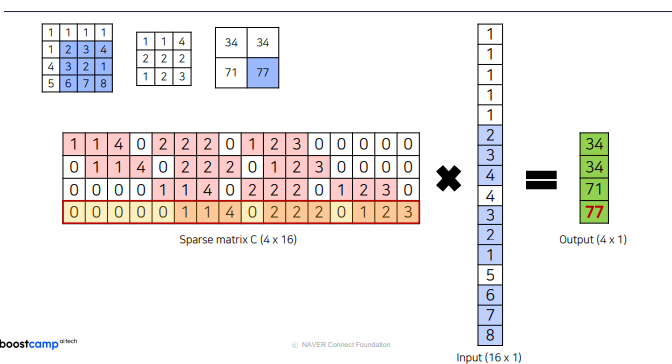 2d 로 했을때와 동일한 결과 나옴
2d 로 했을때와 동일한 결과 나옴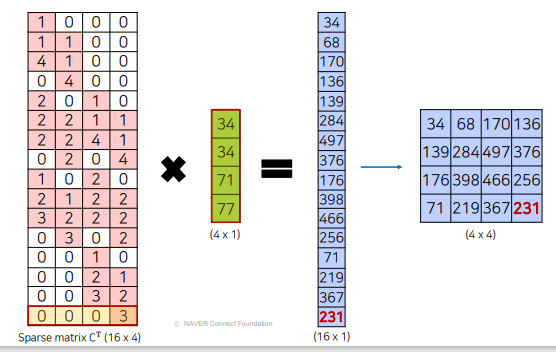 마찬가지로 동일한 결과
마찬가지로 동일한 결과
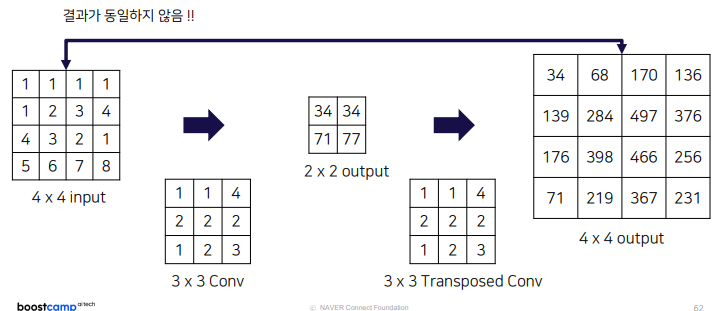 하지만 input의 값과 동일하지는 않음. 따라서 엄밀히 말하면 DeConvolution이라는 이름보다는 Transposed Convolution이라는 이름이 맞음. 하지만 혼용해서 사용. 둘 다 학습 가능한 파라미터를 통해서 이미지를 다시 키우는 convolution을 의미함.
하지만 input의 값과 동일하지는 않음. 따라서 엄밀히 말하면 DeConvolution이라는 이름보다는 Transposed Convolution이라는 이름이 맞음. 하지만 혼용해서 사용. 둘 다 학습 가능한 파라미터를 통해서 이미지를 다시 키우는 convolution을 의미함.
1.4 FCN에서 성능을 향상시키기 위한 방법
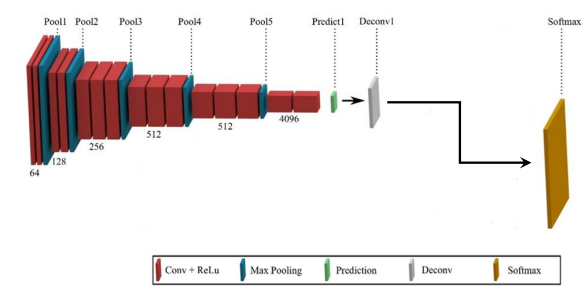

Conv1~Conv5까지 Conv layer 로 채널 수 증가
Pooling layer 로 각 layer 마다 이미지 사이즈 1/2씩 감소
Fc6, FC7 -> Conv
Score -> prediction을 channel수 만큼으로 반환하는 Conv 연산
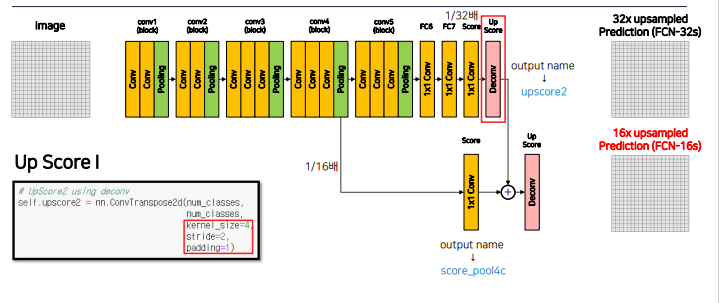
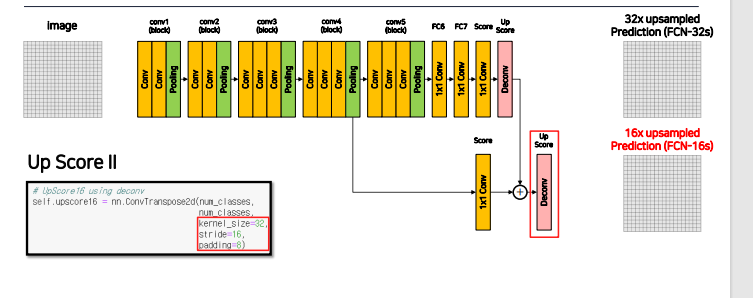
Up Score -> ConvTransposed2d에 kernel_size = 64, stride = 32, padding=16으로 이미지 사이트 32배 늘림
 너무 한번에 늘리면 디테일한 부분의 정보 사라짐
너무 한번에 늘리면 디테일한 부분의 정보 사라짐
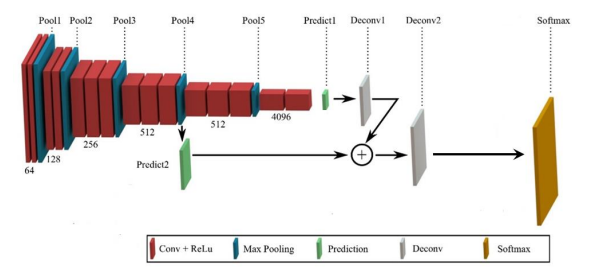
최종 prediction feature map을 2배 키우고, 4번 layer의 feature map(입력의 1/16)과 더해준 후 이를 다시 16배 키우는 DeConv를 진행
이를 통해 1. MaxPooling에 의해서 잃어버린 정보를 복원해주는 작업을 진행
2. Upsampled Size를 줄여주기에 좀 더 효율적인 이미지 복원이 가능함.
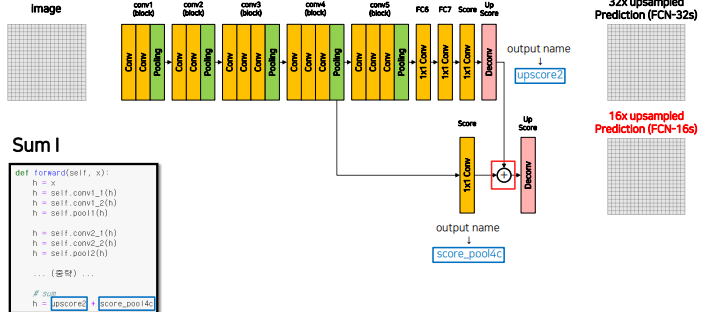
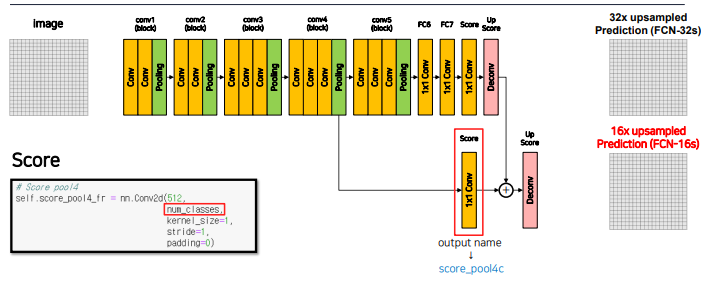 summation을 위해서는 resolution과 channel수가 맞아야 하기 때문에
summation을 위해서는 resolution과 channel수가 맞아야 하기 때문에
4번째 layer output에 1x1 conv를 통해 channel을 class 갯수로 줄임, + 마지막 feature map(그림에서 Score부분)의 resolution은 입력의 1/32이기 때문에 한번의 Decont 연산으로 이미지 크기 2배로 만들어줌
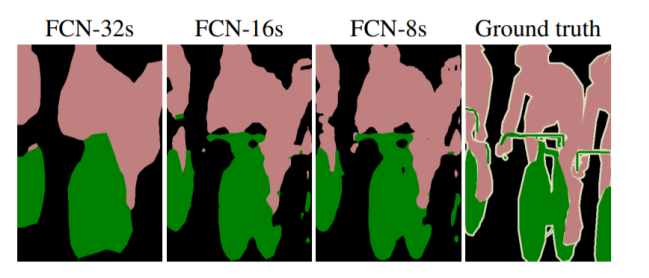
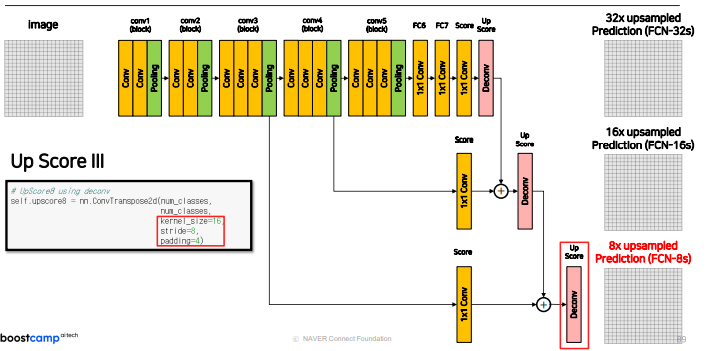
논문에서는 마지막에 8배만큼 이미지를 키우는 FCN-8s 도 제안하는데 다음과 같다.
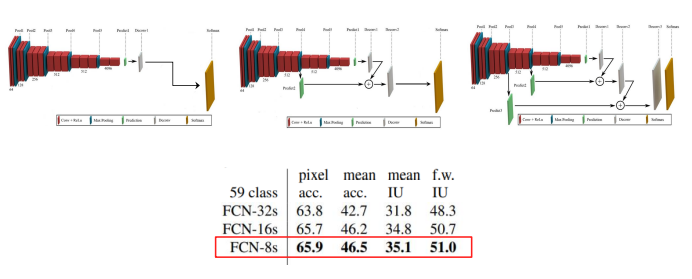 32s보다 8s가 UpSamplig결과가 더 좋은 것을 확인 할 수 있다.
32s보다 8s가 UpSamplig결과가 더 좋은 것을 확인 할 수 있다.
1.5 평가지표
-
Pixel Accuracy
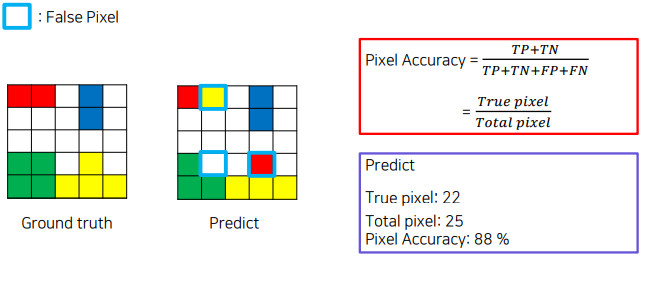
-
Mead IoU
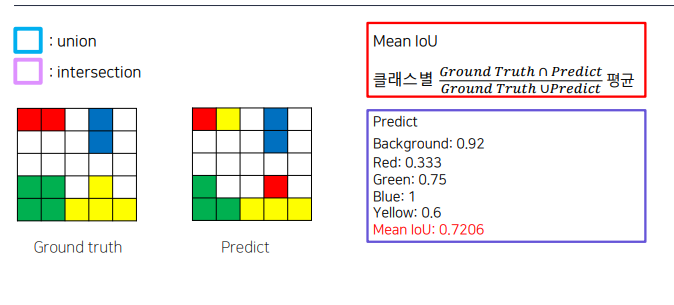
2. 결론
2.1 Further Reading
1x1 을 7x7 convolution으로 바꿀때 발생하는 문제
1. 입력 이미지크기가 달라지는 문제 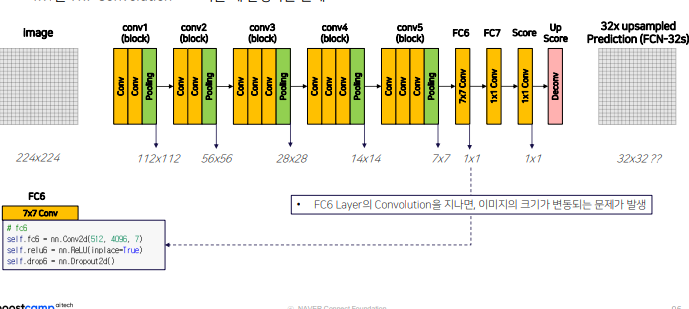

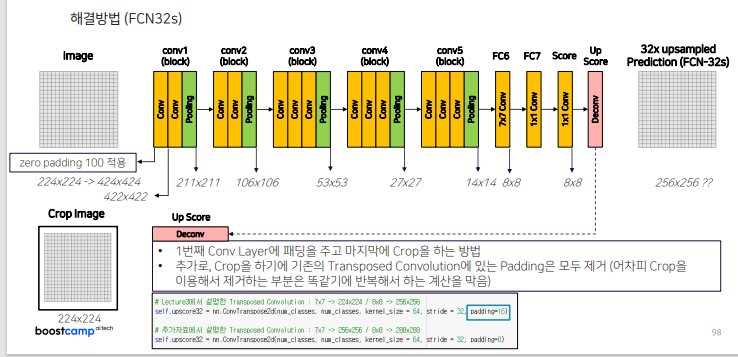
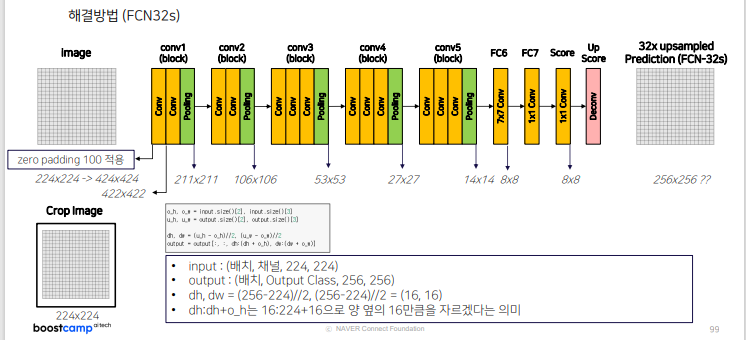
16s, 8s 도 마찬가지로 마지막에 crop 해서 크기 맞춤
2.2 정리
- VGG 네트워크 백본을 사용 (Backbone : feature extracting network) - VGG,Alex,Res, Efficient
- VGG 네트워크의 FC Layer (nn.Linear)를 Convolution 으로 대체
- Transposed Convolution을 이용해서 Pixel Wise prediction을 수행
Further Reading
FCN
과제 수행 과정 및 결과
- FCN8, FCN16, FCN32 중에서 하나를 선택하고 만들어보기
피어 세션
대회 관련 계획
학습 회고
강의 듣는 것에 집중하기
