강의 내용 복습
(9강) Ensemble
Ensenble
더 나은 성능을 위해 "서로 다른" 여러 학습 모델을 사용하는 것
왜 서로 다른 모델을 사용할까?
모델 마다 잘 잡는 특징이 다르기 때문
앙상블 기법 설명출처
-
Boosting
기초 분류기를 훈련시킬 때 직렬적(serial)인 방식을 사용하여 각 기초분류기 사이에 의존 관계가 존재한다. 기본 아이디어는 기초분류기를 층층이 더해 각 층이 훈련될 때 이전 층 기초 분류기가 잘못 분류한 샘플에 더 큰 가중치를 주고, 테스트할 때는 각 층 분류기 결과의 가중치에 기반에 최종 결과를 얻는다.부스팅은 점차적으로 기초 분류기가 잘못 분류한 샘플에 초점을 맞춰 앙상블 분류기의 bias를 줄이므로 bias 가 높을 때 사용하는 방식
-
Bagging
배깅은 부스팅의 직력적인 훈련방식과 다르게, 훈련 과정에서 각 분류기 사이의 의존관계가 거의 존재하지 않고 병렬적으로 훈련을 진행한다.
기초 분류기를 상호 독립적으로 만들기 위해 훈련 데이터셋을 몇개의 하위 집합으로 분류하고, 최종적으로는 각 분류기가 단독으로 판단을 내린 후 투표방식으로 최종 결과를 얻는다. ex-random forest배깅은 분할 정복 전략을 사용해 훈련 셋에 대한 여러차례 샘플링을 통해 다수의 서로다른 모델을 훈련시키고 종합하여 앙상블분류기의 variance를 줄이므로 variance가 높을 때 사용하는 방식
기초분류기 결과 병합 방법 설명출처
-
voting
투표 방식으로 더 많은 표를 얻은 결과를 최종 결과로 채택한다. -
stacking
직렬적인 방법으로, 이전 기초 분류기의 결과를 다음 분류기로 출력하고 모든 기초 분류기릐 출력 결과를 더해 최종 출력으로 설정한다.
Model Averaging(Voting)
각 모델이 다른 error를 가지고 있을 때 좋은 성능을 낸다.

Hard Voting
모델이 예측한 결과를 다수결로 모아 정답 예측
Soft Voting
모델이 예측한 각 class 의 확률까지 고려하여 각 모델이 예측한 logits을 더하고, 모두 더한 logit에서 가장 값이 큰 class를 정답으로 예측
Cross Vlaidation
훈련 셋과 검증 셋을 분리하되, 검증 셋을 학습에 활용하는 방법
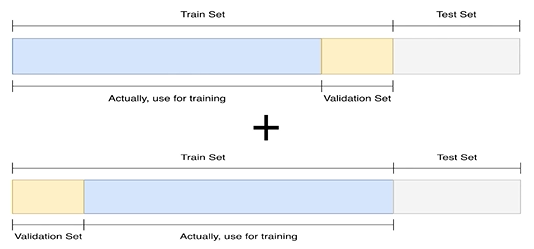
Stratified K-Fold Cross Validation
가능한 경우를 모두 고려 + split 시에 class 분포까지 고려한다.
k 값에 따라 학습에 사용되는 데이터양이 조절되므로 적절한 k값을 찾아야 한다.
예를 들어 k가 3이면 매 학습시 33%데이터는 검증 셋으로 사용되고, 66% 만이 학습에 사용되기 때문에 일반화 성능이 낮아질 수 있다.
반대로 k가 10이면 학습 데이터의 손실은 적어지겠지만 앙상블해야하는 모델이 많아져 학습시간이 너무 길어지는 단점이 있다.
Stratified
split 하는 과정에서 검증 셋에 class 의 분포가 일정하게 하는 것
TTA(Test Time Augmentation)
테스트를 할 때에 데이터를 augmentation 후 모델 추론, 출력된 여러가지 결과를 앙상블하는 것
훈련 데이터셋을 augmentation할 때, 실제 test data에서 나올 수 있는 상황을 고려하여 다양한 상황에서 robust할 수 있도록 augmentation을 한다.
하지만 test set 또한 다른 환경에서는 다르게 관측될 수 있다. 그렇다면 test set에도 여러 다른 상태를 적용하여 모델에 넣었을 때도 똑같은 결과를 낼까?
이를 위해 test data에도 여러 Variance를 추가하여 추론하고 , 결과를 합치는 것 (logit을 더해 평균을 내는 등)
참고 dacon
성능과 효율의 trade-off
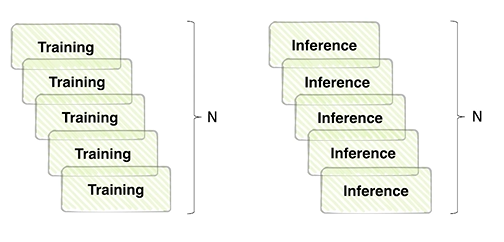
앙상블 효과는 확실히 있지만 그만큼 학습, 추론시가닝 배로 소모된다.
Hyperparameter Optimization
Hiddien Layer 갯수, k-fold, learning rate, Batch size 등 시스템의 매커니즘에 영향을 주는 주요한 파라미터
파라미터를 변경할 때마다 학습을 해야하기 때문에 시간적 효율이 떨어진다.
Optuna
파라미터 범위를 주고 그 범위 안에서 trials 만큼 시행하는 도구
Further Reading
Optuna github
Hyper parameter Opt 포스팅
AutoML 관련 포스팅
(10강) Experiment Toolkits & Tips
Training Visualization
Tensorboard
학습 과정을 기록하고 트래킹하는 모듈
사용법
Weight and Bias(wandb)
딥러닝 로그의 깃허브 같은 느낌

설정한 프로젝트의 log를 사이트 페이지에서 확인 가능
Machine Learning Project
jupyter notebook
코드를 아주 빠르게 cell 단위로 실행해볼 수 있는 것이 장점. 보통 EDA를 할 때 사용
단점은 진행도중 노트북 창이 꺼지면 돌아갈 수 없음
Python IDLE
구현은 한번만, 사용은 언제든, 간편한 코드 재사용. 디버깅 사용 가능
argparse를 통해 자유로운 실험 핸들링이 가능하다.
Further Reading
- Weight&Biases 홈페이지 실험관리 툴 wandb 홈페이지 - wandb가 지정한 프로젝트 결과 확인 가능
- Paperswithcode 최신논문과 해당논문의 코드 확인
과제 수행 과정 및 결과
피어 세션
대회관련 얘기
-utkface 데이터셋에 마스크 붙여서 데이터 셋 제작
-준지도 학습 도전
학습 회고
코드 구현이 너무 느리다 좀 빠르게,,,
