논문
End-to-End Semi-Supervised Object Detection with Soft Teacher
Contribution
- end-to-end semi supervised framework
- SOTA 달성
dataset : MS-COCO
Train2017 : 118k labeled images
unlabeled2017 : 123k unlabeled images
val2018 : 5k images for validation
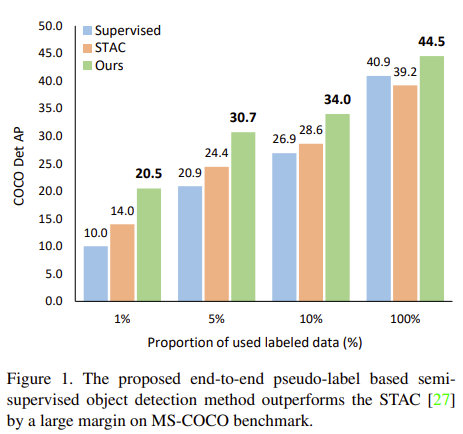
Figure 1. COCO dateset에서 labeled dataset의 비율을 1, 5, 10% 로 실험했을 때 가장 성능이 좋다.
*STAC : A simple semi-supervised learning framework for object detection. arXiv 2020
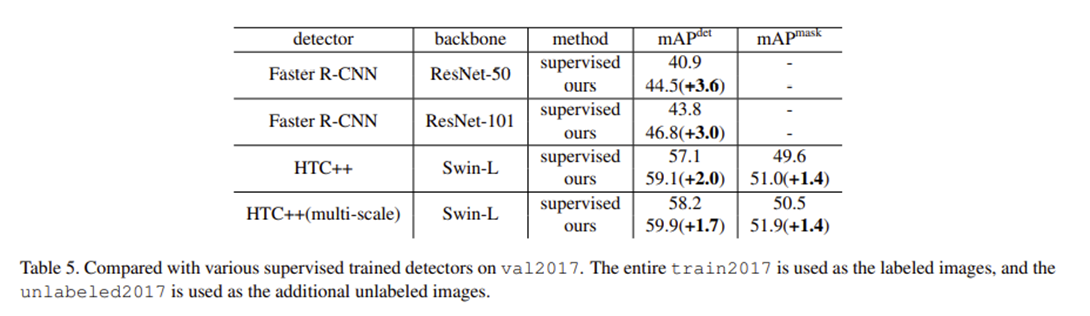
Table 5. 다른 detector와의 비교. SOTA인 detector HTC++ with Swin-L backbone의 supervised detection이 58.9 map, 본 논문의 방법론은 1.5 더 높은 60.4 map을 보여준다. 이는 Coco object detection benchmark에서 처음으로 60 map를 넘긴 것이다.
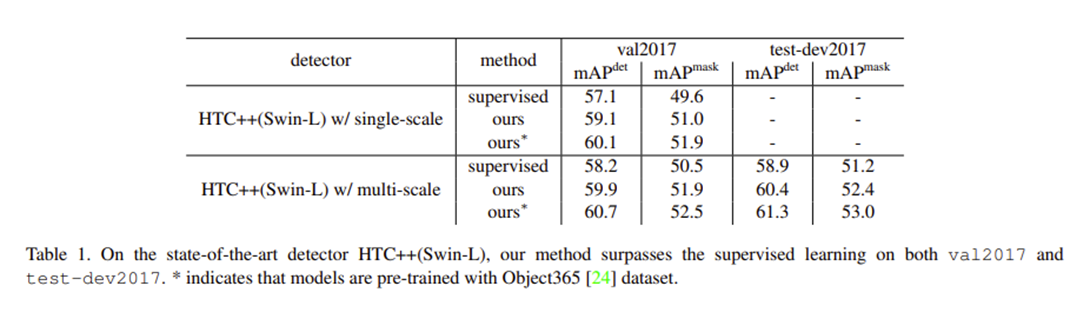
Table 1. 다른 detector와도 비교하기위해 val2017 set으로 검증했다. SOTA인 detector HTC++ with Swin-L backbone 에서도 더 높은 map를 보여준다.
Abstract
Object Detection 에서 semi-supervised learning을 통해 teacher-student model을 학습하는 방법.
1. End-to-End Pseudo-Labeling Framework
semi-supervised learning을 제안한 이전 논문들은 teacher model과 student model의 학습을 여러번 반복해야 하는 multi stage 학습법을 제안하지만 이 논문에서는 end-to-end frmaework를 통해 모델의 성능을 발전시키는 방법을 제안한다.
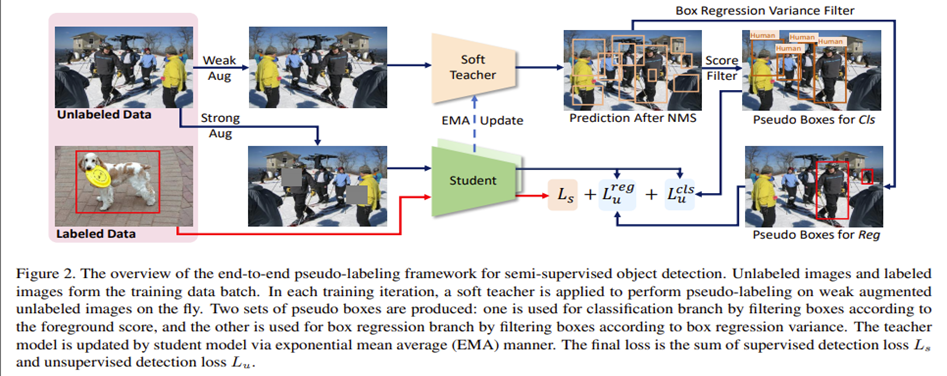
teacher model은 unlabeled data에 pseudo label을 생성하고, student model은 detection training을 담당한다. 선생모델은 학생모델의 EMA로 업데이트된다. (Mean Teacher)
Teacher model은 두 set의 pseudo label을 생성하는데, 하나는 student model의 Classification branch를 학습하기 위함이고 다른 하나는 student model의 Regression branch를 학습하기 위함이다.
end-to-end framework에서 가장 중요한 두 요소는 다음과 같다.
2. Soft Teacher
Student model의 classification branch 성능향상을 위한 방법.
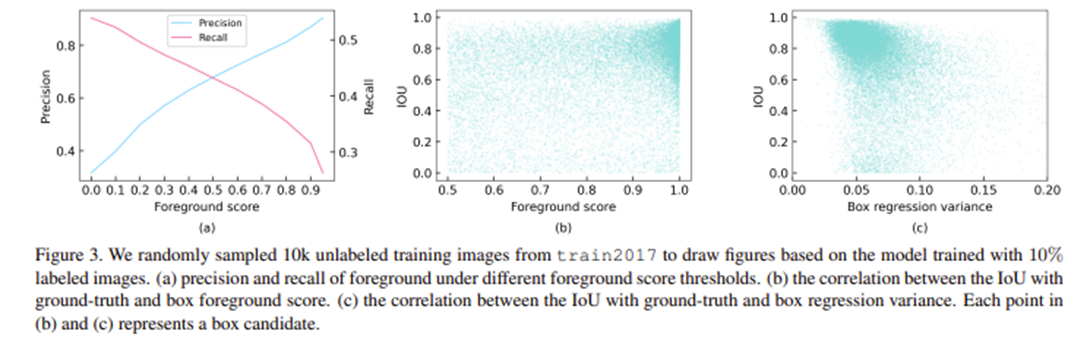 Detector의 성능은 Pseudo-label의 질이 결정하는데, 실제로 높은 foreground threshold (0.9)일 때 map에서 가장 좋은 성능이 나온다. 하지만 높은 threshold는 precision은 높여주지만 recall은 낮아지게 한다.(Figure3.a) 이렇게 되면 실제로는 객체인 박스가 배경(negative)으로 잘못 판단되어 성능이 낮아진다. 이 문제를 해결하기위해 soft teacher를 제안.
Detector의 성능은 Pseudo-label의 질이 결정하는데, 실제로 높은 foreground threshold (0.9)일 때 map에서 가장 좋은 성능이 나온다. 하지만 높은 threshold는 precision은 높여주지만 recall은 낮아지게 한다.(Figure3.a) 이렇게 되면 실제로는 객체인 박스가 배경(negative)으로 잘못 판단되어 성능이 낮아진다. 이 문제를 해결하기위해 soft teacher를 제안.
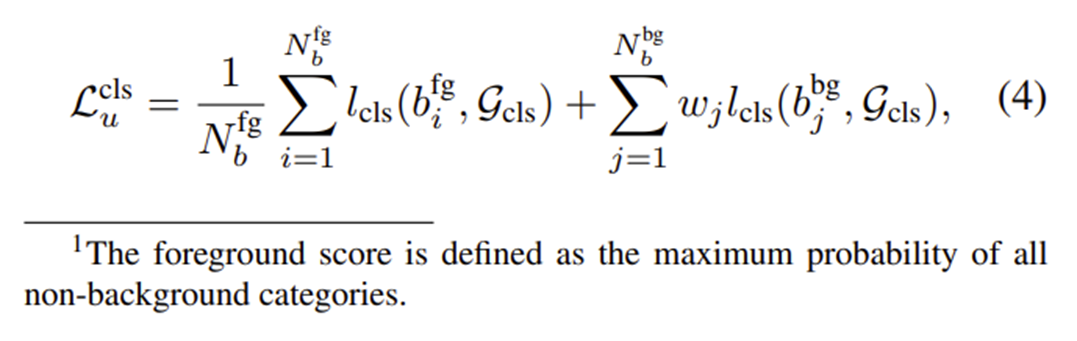
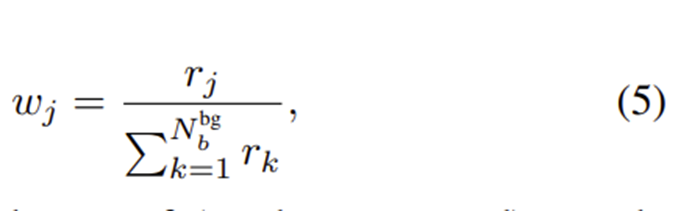
수식(4) : 객체로 판단된 박스와 배경으로 판단된 박스 셋이 주어졌을 때 reliable weight이 포함된 unlabeled image의 classification loss
: teacher-generated pseudo boxes used for classification
: box classification loss
: reliability score for j-th background box candidate
, : 각각 객체로 판단된 후보박스셋()에서 박스의 개수 , 배경으로 판단된 후보박스셋()에서 박스의 개수
: reliability. weak augmentation을 적용한 teacher model에 의해 생성된 background score
student model이 생성한 후보박스들을 teacher model의 classification branch로 전달하여 background score를 내고, reliability measure를 계산하여 classification loss의 가중치로 사용한다. reliability measure는 따라서 후보박스의 background score가 작다면 loss 계산시에도 작은 가중치가 곱해지게 된다.
3. Box Jiterring
Student model의 regression branch 성능향상을 위한 방법.
Figure3.b 에 보이는 것처럼 것처럼 localization accuracy와 후보박스의 foreground score는 강한 양의 상관관계를 보이지 않는다. 이는 높은 foreground score를 가진 박스가 정확한 localization정보를 제공하지는 않는다는 말이다. 즉 teacher model이 생성한 box를 선택할 때 foreground score로만 판단하면 box regression에는 적합하지 않다.
이를 해결하기 위해 논문에서는 box regression variance 를 지표로 사용한다.
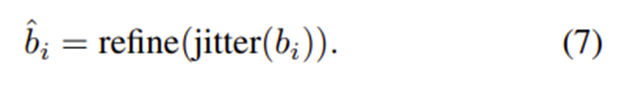
계산 비용을 위해 foreground score가 0.5이상인 박스에만 jiterring 을 한다. Jiterring이란 teacher model이 예측한 박스주변으로 랜덤한 offset을 주어 흐트러뜨리는 것을 말한다.

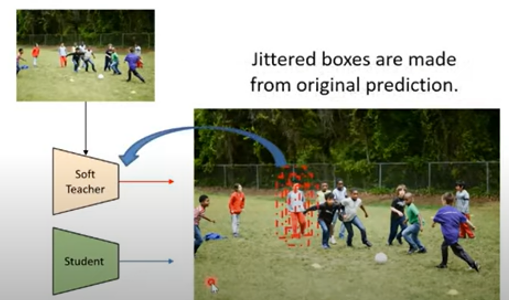
Teacher model이 생성한 후보박스 를 jitter하여 다시 선생모델에 넣어 refine 하여 box 를 생성한다.
이렇게 하는 이유는 원래 예측이 잘됐던 박스를 흐트러뜨리면 jiterred boxes는 탐지 대상인 객체 근처에 있을 것이기 땨문에 다시 원래자리로 돌아올 것이다 라는 가정 - 최종적으로 jittered된 박스들을 다시 soft teacher가 regression을 했을 때 원래 자리로 돌아오기 때문에 각각의 박스에 대한 분산도가 적을 것이다라고 예측.
Teacher model이 pseudo-label을 생성할 때 만약 teacher model의 예측이 좋지 않았다고 해도 (bad regression) Jittered 된 박스들을 다시 teacher 모델에 넣으면 박스들이 jittered 되면서 완전히 배경 쪽으로 밀려나기 때문에 regression 결과가 여러군데로 흩어질것이다 라는 가정.
그래서 이 가정대로 실험을 했을 때 Box regression variance 와 iou가 역의 상관관계를 보이는 것을 확인하였고, Box regression variance를기준으로 박스들을 필터링해서 학습에 사용한다. box regression variance가 threshold 보다 작으면 box regression 단계에서 해당 박스들을 unlabeled image의 pseudo label로 두었다.
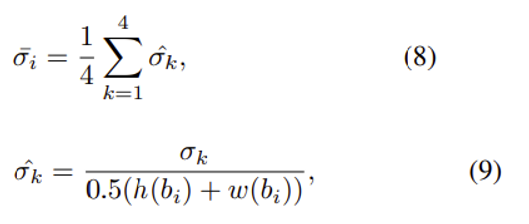
: k번째 refined jittered boxes set의 표준편차
: 후보박스의 높이와 너비의 합의 절반으로 정규화된(나누어진) 값
이에 대한 regression loss는 다음과 같다.
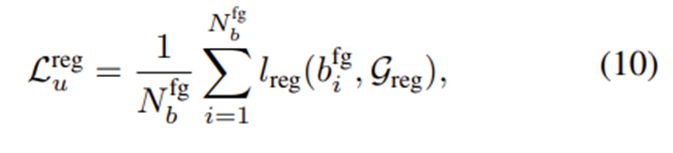
: foreground로 판단된 i번째 박스
: foreground box의 총 개수
: box regression loss
따라서 최종적으로 unlabeled image 의 loss는 다음과 같다.
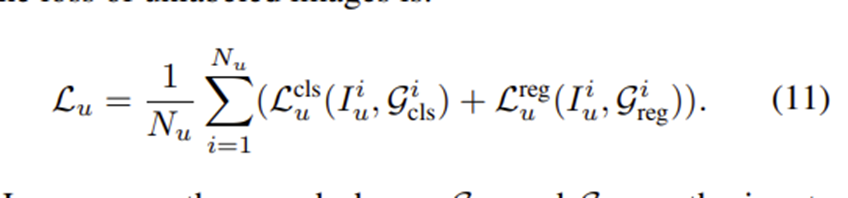
Experiments
Dataset and Evaluation Protocol
Validation을 위한 두가지 환경
Partially Labeled Data : 1, 5, 10% train2017 labeled data 로 쓰고 나머지 안쓴 train2017을 unlabeled data로 사용
Fully Labeled Data : train2017 전체를 labeled data로 넣고 unlabeled2017을 추가적인 unlabeled data로 사용
Implementation Details
Backbone : ImageNet pre-trained ResNet-50
default detection framework : Faster R-CNN equipped with FPN (Feature Pyramid Network)
Hyperparameter : MMDetection
Anchors : 5 scales and 3 aspect ratio
NMS threshold : 0.7 (for training and inference)
In each training step : 512 proposals are sampled from 2k proposals as the box candidates to train RCNN
Conclusion
- Unlabeled dataset을 추가로 활용하여 성능을 높이는 semi-supervised 방법론 제안
- Multi-stage training이 필요한 기존 방법과 달리 end-to-end 학습
- 학습을 진행하면서 점점 정확한 pseudo label을 만들어나가는 방식
- classification loss와 regression loss 따로 학습
- classfication : soft teacher가 계산한 box의 filtering score에 따라 가중치를 두어 loss 계산
- regression : box jittering으로 계산한 box regression variance가 threshold보다 낮은 box만 이용하여 loss 계산
- COCO dataset detection benchmark에서 SOTA 달성
Feedback
-
Soft Teacher 에 대해 다시 설명
teacher model 이 생성한 paeudo label에 대한 foreground threshold를 매우 높게 잡으면 확실히 객체인 박스만을 객체박스라고 판단할 수는 있지만, 실제로는 객체인 박스가 score가 threshold보다 낮아 배경으로 판단될 수 있다. 이렇게 되면 실제로는 객체인데 객체로 판단되지 못해 recall이 낮아지는 문제가 생긴다.
이를 해결하기 위한 것이 Soft Teacher로, student model이 만든 후보박스에 대한 background score를 teacher 가 계산하여 만약 score가 낮다면 실제로 배경인 것이 확실하지 않으므로 loss를 계산할때도 해당 박스에 대한 가중치를 작게주어 영향을 줄이는 것. -
Box Jittering에 대해 다시 설명
보통은 foreground score가 높으면 박스의 위치를 예측하는 regression 결과도 당연히 좋을 것이라고 생각하는데, 그러면 GT의 IOU와 box foreground score는 양의 상관관계를 가져야한다. 그런데 둘의관계를 실제로 그래프로 그리면 큰 양의 상관관계가 보이지 않는다.
따라서 box foreground score는 regression 성능에는 큰 관계가 없으니, 새로운 지표인 Box regression variance를 제안한다.이는 teacher model이 생성한 결과가 괜찮은 객체 후보박스를 jitering하여 다시 teacher model에 넣어 refine하면 (-> 여기서 refine은 (이후에 박스들간의 분산을 계산하므로) teacher model로 다시 regression하는 것으로 이해한다.) jittered 된 박스들의 위치도 다시 원래대로(jittering 하기 전의 위치로) 돌아올 것이고, 따라서 해당 박스 위치간의 (수식에서는 width, height 로 계산) 분산을 계산해보면 분산이 작을 것이고,
teacher model이 생성한 박스가 배경일 경우에는 jiterring - refine 하면 박스들이 배경을 찾아 밀려나니 해당 박스들간의 분산이 커질것이다 라는 가정을 가지고 실험한 결과.
GT의 IOU와 Box regression variance 간의 상관관계를 그래프로 그리자 확실함 음의 상관관계가 보인다. 이는 박스의 분산이 낮을수 록 GT에 가까워진다는 말이므로 Box regression variance는 regession branch의 성능을 계산하는데에 좋은 지표가 될 것이다. 따라서 본 논문에는 box regression variance를 기준으로 후보박스를 filtering 하여 pseudo label로 채택한다.
-
loss에 regularization이 없는건지
SoftTeacher의 detector로 쓰인 Faster R-CNN의 mmdetection config를 확인해보면
rpn head, roi head 모두 cls loss 는 Cross Entropy, reg loss는 L1 loss를 사용했다. reg loss 는 L1 regularization 을 적용했다.
Inference 해보기
microsoft/soft teacher Github 을 보면 MMDetection으로 구현되어 있다.
pytorch 1.9.0 환경에서 make install로 필요한 라이브러리를 설치한다.
Github에서 원하는 model weight를 다운받는다. 이 글에서는 Full Labeled Data, Faster R-CNN(ResNet-50),map 44.05의 model weight을 받았다.
inference할 이미지도 준비해준다.
이후 python demo/image_demo.py /tmp/tmp.png configs/soft_teacher/soft_teacher_faster_rcnn_r50_caffe_fpn_coco_full_720k.py work_dirs/downloaded.model --output work_dirs/ 명령어로 inference를 해보면 결과는 다음과 같다.
| 원본 이미지 | Inference 결과 이미지 |
|---|---|
 |  |
이 때 사용한 Config는 다음과 같다.
configs/soft_teacher/soft_teacher_faster_rcnn_r50_caffe_fpn_coco_full_720k.py
data config에서 sup(supervise), unsup(unsupervise)두 가지의 데이터셋과 annotation 위치를 전달한다.
semi_wrapper에서 unsup_weight=2.0은 supervies loss와 unsupervise loss로 이루어진 전체 loss에서 unsupervise loss 에게 주는 가중치를 말한다. (수식에서 )
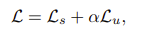
_base_="base.py"
data = dict(
samples_per_gpu=8,
workers_per_gpu=8,
train=dict(
sup=dict(
ann_file="data/coco/annotations/instances_train2017.json",
img_prefix="data/coco/train2017/",
),
unsup=dict(
ann_file="data/coco/annotations/instances_unlabeled2017.json",
img_prefix="data/coco/unlabeled2017/",
),
),
sampler=dict(
train=dict(
sample_ratio=[1, 1],
)
),
)
semi_wrapper = dict(
train_cfg=dict(
unsup_weight=2.0,
)
)
lr_config = dict(step=[120000 * 4, 160000 * 4])
runner = dict(_delete_=True, type="IterBasedRunner", max_iters=180000 * 4)configs/soft_teacher/base.py
strong pipeline과 weak pipeline을 따로 정의하여 unsup_pipeline에서 student model에게는 strong augmentation을, teacher model에게는 weak augmentation을 준다.
data config에서 sup(supervise), unsup(unsupervise)두 가지의 데이터셋을 train에 넣어준다.
semi_wrapper에서는 각종 threshold와 같은 hyper parameter를 정의한다. test_cfg를 보면 inference를 student model이 하는 것을 알 수 있다.
mmdet_base = "../../thirdparty/mmdetection/configs/_base_"
_base_ = [
f"{mmdet_base}/models/faster_rcnn_r50_fpn.py",
f"{mmdet_base}/datasets/coco_detection.py",
f"{mmdet_base}/schedules/schedule_1x.py",
f"{mmdet_base}/default_runtime.py",
]
model = dict(
backbone=dict(
norm_cfg=dict(requires_grad=False),
norm_eval=True,
style="caffe",
init_cfg=dict(
type="Pretrained", checkpoint="open-mmlab://detectron2/resnet50_caffe"
),
)
)
img_norm_cfg = dict(mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
train_pipeline = [
dict(type="LoadImageFromFile"),
dict(type="LoadAnnotations", with_bbox=True),
dict(
type="Sequential",
transforms=[
dict(
type="RandResize",
img_scale=[(1333, 400), (1333, 1200)],
multiscale_mode="range",
keep_ratio=True,
),
dict(type="RandFlip", flip_ratio=0.5),
dict(
type="OneOf",
transforms=[
dict(type=k)
for k in [
"Identity",
"AutoContrast",
"RandEqualize",
"RandSolarize",
"RandColor",
"RandContrast",
"RandBrightness",
"RandSharpness",
"RandPosterize",
]
],
),
],
record=True,
),
dict(type="Pad", size_divisor=32),
dict(type="Normalize", **img_norm_cfg),
dict(type="ExtraAttrs", tag="sup"),
dict(type="DefaultFormatBundle"),
dict(
type="Collect",
keys=["img", "gt_bboxes", "gt_labels"],
meta_keys=(
"filename",
"ori_shape",
"img_shape",
"img_norm_cfg",
"pad_shape",
"scale_factor",
"tag",
),
),
]
strong_pipeline = [
dict(
type="Sequential",
transforms=[
dict(
type="RandResize",
img_scale=[(1333, 400), (1333, 1200)],
multiscale_mode="range",
keep_ratio=True,
),
dict(type="RandFlip", flip_ratio=0.5),
dict(
type="ShuffledSequential",
transforms=[
dict(
type="OneOf",
transforms=[
dict(type=k)
for k in [
"Identity",
"AutoContrast",
"RandEqualize",
"RandSolarize",
"RandColor",
"RandContrast",
"RandBrightness",
"RandSharpness",
"RandPosterize",
]
],
),
dict(
type="OneOf",
transforms=[
dict(type="RandTranslate", x=(-0.1, 0.1)),
dict(type="RandTranslate", y=(-0.1, 0.1)),
dict(type="RandRotate", angle=(-30, 30)),
[
dict(type="RandShear", x=(-30, 30)),
dict(type="RandShear", y=(-30, 30)),
],
],
),
],
),
dict(
type="RandErase",
n_iterations=(1, 5),
size=[0, 0.2],
squared=True,
),
],
record=True,
),
dict(type="Pad", size_divisor=32),
dict(type="Normalize", **img_norm_cfg),
dict(type="ExtraAttrs", tag="unsup_student"),
dict(type="DefaultFormatBundle"),
dict(
type="Collect",
keys=["img", "gt_bboxes", "gt_labels"],
meta_keys=(
"filename",
"ori_shape",
"img_shape",
"img_norm_cfg",
"pad_shape",
"scale_factor",
"tag",
"transform_matrix",
),
),
]
weak_pipeline = [
dict(
type="Sequential",
transforms=[
dict(
type="RandResize",
img_scale=[(1333, 400), (1333, 1200)],
multiscale_mode="range",
keep_ratio=True,
),
dict(type="RandFlip", flip_ratio=0.5),
],
record=True,
),
dict(type="Pad", size_divisor=32),
dict(type="Normalize", **img_norm_cfg),
dict(type="ExtraAttrs", tag="unsup_teacher"),
dict(type="DefaultFormatBundle"),
dict(
type="Collect",
keys=["img", "gt_bboxes", "gt_labels"],
meta_keys=(
"filename",
"ori_shape",
"img_shape",
"img_norm_cfg",
"pad_shape",
"scale_factor",
"tag",
"transform_matrix",
),
),
]
unsup_pipeline = [
dict(type="LoadImageFromFile"),
# dict(type="LoadAnnotations", with_bbox=True),
# generate fake labels for data format compatibility
dict(type="PseudoSamples", with_bbox=True),
dict(
type="MultiBranch", unsup_student=strong_pipeline, unsup_teacher=weak_pipeline
),
]
test_pipeline = [
dict(type="LoadImageFromFile"),
dict(
type="MultiScaleFlipAug",
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type="Resize", keep_ratio=True),
dict(type="RandomFlip"),
dict(type="Normalize", **img_norm_cfg),
dict(type="Pad", size_divisor=32),
dict(type="ImageToTensor", keys=["img"]),
dict(type="Collect", keys=["img"]),
],
),
]
data = dict(
samples_per_gpu=None,
workers_per_gpu=None,
train=dict(
_delete_=True,
type="SemiDataset",
sup=dict(
type="CocoDataset",
ann_file=None,
img_prefix=None,
pipeline=train_pipeline,
),
unsup=dict(
type="CocoDataset",
ann_file=None,
img_prefix=None,
pipeline=unsup_pipeline,
filter_empty_gt=False,
),
),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline),
sampler=dict(
train=dict(
type="SemiBalanceSampler",
sample_ratio=[1, 4],
by_prob=True,
# at_least_one=True,
epoch_length=7330,
)
),
)
semi_wrapper = dict(
type="SoftTeacher",
model="${model}",
train_cfg=dict(
use_teacher_proposal=False,
pseudo_label_initial_score_thr=0.5,
rpn_pseudo_threshold=0.9,
cls_pseudo_threshold=0.9,
reg_pseudo_threshold=0.02,
jitter_times=10,
jitter_scale=0.06,
min_pseduo_box_size=0,
unsup_weight=4.0,
),
test_cfg=dict(inference_on="student"),
)
custom_hooks = [
dict(type="NumClassCheckHook"),
dict(type="WeightSummary"),
dict(type="MeanTeacher", momentum=0.999, interval=1, warm_up=0),
]
evaluation = dict(type="SubModulesDistEvalHook", interval=4000)
optimizer = dict(type="SGD", lr=0.01, momentum=0.9, weight_decay=0.0001)
lr_config = dict(step=[120000, 160000])
runner = dict(_delete_=True, type="IterBasedRunner", max_iters=180000)
checkpoint_config = dict(by_epoch=False, interval=4000, max_keep_ckpts=20)
fp16 = dict(loss_scale="dynamic")
log_config = dict(
interval=50,
hooks=[
dict(type="TextLoggerHook", by_epoch=False),
dict(
type="WandbLoggerHook",
init_kwargs=dict(
project="pre_release",
name="${cfg_name}",
config=dict(
work_dirs="${work_dir}",
total_step="${runner.max_iters}",
),
),
by_epoch=False,
),
],
)
설명에 이상한 점이 있다면 댓글로 말씀해주시면 감사하겠습니다!
REF
[논문 읽기] Soft Teacher(2021)
2021 ICCV SOTA Semi Supervised
