Self-training
준지도 학습(Semi-Supervised Learning, SSL)의 방법 중 하나인 Self-training은 labeled data를 활용하여 학습한 모델이 예측한 결과(confident한 결과)를 unlabeled data의 Pseudo-Label로 가정해서 unlabeled data를 사용하는 방법이다.
여기서 self-training은 semi-supervised 방법론과 self-supervised 방법론을 적당히 아우르는 말 같다. teacher-student 식으로 pre-train된 weight를 재사용하는 과정이 있으면 (the term "self") self-supervised인지, semi-supervised인지 구분짓지 않고 self-training 방법으로 소개를 하는 듯.
그렇다면 self-supervised와 semi-supervised의 차이는 뭘까.
self-supervised learning는 레이블링 되어있지 않은 데이터를 이용해 모델 스스로 레이블링 되게 하는 것이다. 입력데이터의 한 부분이 다른 부분의 supervision 이 되게하는 것이다. 즉 입력에 대한 레이블 없이 입력 그 자체만으로 만든 label에 대해 discriminative하게 훈련시켜 데이터의 representation을 얻는 방법.
self-supervised learning 의 과정은 다음과 같다.
- pretext task(연구자가 직접 만든 task)를 정의한다.
- label이 없는 데이터셋을 이용하여 1의 pretext task를 목표로 모델을 학습시킨다. (=레이블이 없는 데이터를 입력하여 입력된 데이터를 잘 설명할 수 있도록 학습을 따로 진행)
이때, 데이터 자체의 정보를 적당히 변형/사용하여 이를 label은 아니지만, supervision(지도)으로 삼는다.
- 2에서 학습시킨 모델을 downstream task(실제로 풀고자 하는 문제에 pretext task에서 학습된 가중치를 가져와 적용하는 과정)에 가져와 weight는 freeze 시키고 transfer learning을 수행한다.(2에서 학습한 모델의 성능만을 보기 위해)
처음에는 label이 없는 상태에서 직접 supervision을 만들어 학습한 뒤, transfer learning 단계에서는 label이 있는 ImageNet 등에서 Supervised Learning을 수행하여 2에서 학습시킨 모델의 성능(feature를 얼마나 잘 뽑아냈는지 등)을 평가하는 방식이다. 사람이 직접 labeling한 데이터를 사용하지 않기 때문에 Unsupervised learning으로 보기도 하지만, 모델이 스스로 supervision을 만들어 학습하기 때문에 Unsupervised learning으로 보는 것은 잘못되었다는 의견도 있다.
데이터를 변형하여 supervision으로 삼는 특징 때문에 Contrastive learning도 self-supervised learning의 한 종류로 볼 수 있다고 한다. Contrastive learning 또한 input data에 변형을 가한 뒤 해당 데이터들의 유사도(거리)를 가깝게/멀게 하는 방식으로 학습을 하기 때문에,,,
semi-supervised learning은 레이블링 된 데이터가 충분하지 않을 때, 레이블이 없는 데이터도 함께 이용하여 모델을 학습시키는 방법이다. 적은 양의 labeled data로 supervised-learning을 한 후, 해당 모델로 하여금 unlabeled data의 label을 예측하게 하는 것이다. 이렇게 예측한 label을 pseudo-label이라고 부르고, downstream task 학습시에는 모든 데이터셋을 labeled data로 간주하고 사용하는 방법이다.
암튼 두 방법의 공통점은 labeling 된 데이터가 부족한 문제를 해결하기 위해 고안된 방법이라는 것이다. 좀 더 자세한 내용을 알고싶다면 요 글도 도움이 될 것 같다.
1. Entropy Minimization
Semi-supervised Learning by Entropy Minimization (EntMin), NIPS 2004
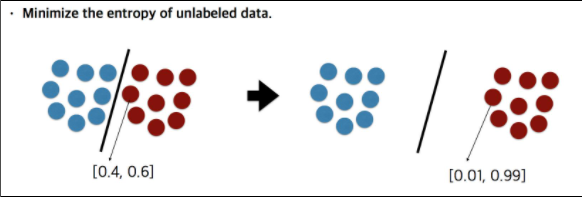
EntMin은 entropy regularization, 즉 모델이 unlabled data에 대한 prediction 시 entropy를 작게 만드는 방법이다.
Classifier A가 예측한 y에 대한 확률이 [0.1, 0.8, 0.1]이고,
Classifier B가 예측한 y에 대한 확률이 [0.1, 0.6, 0.3] 이라고 하자.
이때, Classifier A가 더 confident하고 낮은 entropy를 갖는다. (class 1을 예측하는데 좀 더 확신을 갖고 있다.)
EntMin은 unlabeled data에 대한 예측의 entropy를 낮추는 것을 목표로 한다.
Abstract
- unlabeled data의 hidden representation을 학습할 때, entropy가 다소 높다면, 다른 클래스와의 decision boundary 주변에 feature vector가 위치할 (또는 그렇게 되도록 학습이 될) 가능성이 높고, 이는 성능 저하를 불러일으킬 수 있다.
- Loss에 entropy minimization term을 추가하여 학습을 진행한다.

- entropy minimization의 장점은 밀도가 높은 데이터를 분류할 때 dicision boundary가 데이터의 밀도가 높은 부분에 생성되는 것을 방지한다.
Take-home Message
semi-supervised learning에서 entropy minimization을 통해 unlabeled data의 예측에 대한 confidence를 높인다.
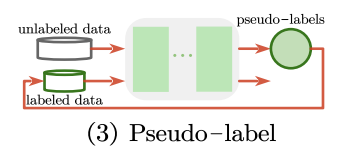
2. Pseudo-label
Abstract
- labeled data와 unlabeled data를 동시에 사용하여 network를 학습시키는 방법
- labeled data를 사용하여 지도학습시킨 모델(cross-entropy loss)로 unlabled data의 class를 예측한다. maximum confidence prediction을 pseudo-label, 즉 unlabeled data의 class로 가정한다.
- 전체 loss function 은 지도학습에 대한 loss와 unlabeled data에 대한 loss를 더하고 둘의 밸런스를 계수로 조절한다.
: the number of mini-batch in labeled data for SGD
: the number of mini-batch in unlabeled data for SGD
: the output units of m’s sample in labeled data
: label of
: the output units of m’s sample in unlabeled data
: the pseudo-label
: coefficient balancing the supervised and unsupervised loss terms
Take-home Message
지도학습 시킨 모델로 unlabeled data에 대한 pseudo-label을 만들어 데이터 부족 또는 class 불균형 문제를 완화할 수 있다.
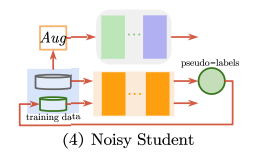
3. Noisy Student
Self-training with noisy student improves imagenet classification, CVPR 2020
Abstract
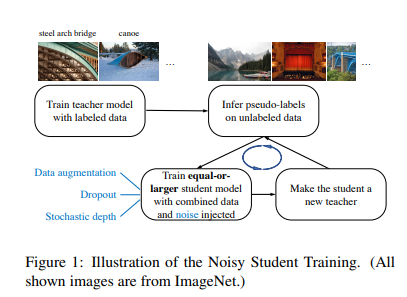
- teacher model과 크기가 같거나 더 큰 student model을 사용하는, knowledge distillation 에 영감을 받은 semi-supervised 방법론
- 논문에서는 teacher model 보다 더 큰 크기의 student model을 사용하여 capacity를 늘리고 학습이 noise를 주는 측면에서는 knowledge expansion이라고 말할 수 있다고 한다.
- teacher model EfficientNet은 labeled image로 학습 후 unlabeled data의 pseudo label을 생성
- teacher model의 EfficientNet보다 크기가 큰 EfficientNet을 student model로 사용하여 laebled+unlabeled data 학습
- student model 학습 시에는 dropout, stochastic depth, data augmentation(RandAugment)와 같은 noise를 추가하여 모델의 일반화 성능을 높인다.
- 이렇게 만들어진 student model을 다시 teacher model로 사용하는 것을 반복한다.
Take-home Message
- student model 학습 시 noise 추가로 모델의 일반화 성능을 높이고 이를 반복하여 성능을 향상시킨다.
4. Self-supervised Semi-supervised Learning (S4L)
Self-supervised Semi-supervised Learning (S4L), IEEE 2019
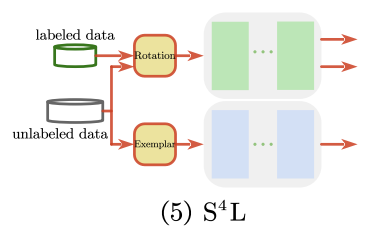
self-supervised learning은 supervised-learning보다는 좋지 않은 visual representation을 학습하므로 실제 적용가능성은 제한적이다. 이 논문에서는 self-supervised learning이 적은 양의 labeled examples가 있을 때 더욱 잘 작동한다고 가정하고, self-supervised와 semi-supervised를 연결한 framework를 제안한다.
Abstract

본 논문에서 제안한 주된 기법은 S4L-Rotation과 S4L-Exemplar이다.
-
S4L-Rotation(predicting image rotation)
input image에 적용된 rotation transformation의 각도를 예측하는 pretext task
S4L에서는 0, 90, 180, 270도 4가지 각도를 사용하여 이미지를 회전변환한다.
S4L rotation loss는 회전된 이미지에 대한 output의 cross-entropy loss이다. -
Exemplar
Exemplar loss : 모델이 heavy image augmentatino에도 변하지 않는 representation을 학습하도록 하는 loss
하나의 이미지에서 inception cropping, random horizontal mirroring, HSV-space color randomization등을 통해 8개의 다른 instance를 생성한다. unsupervised image의 loss term은 soft margin을 사용한 batch hard triplet loss 이다.
이 loss가 변환을 적용해도 같은 이미지는 similar respresentation을 가지게하고, 다른 이미지는 다양한 representation을 갖게한다.
학습시
첫번째로는 4가지 각도로 회전된 4가지 input image를 생성
어떤 각도로 회전되었는지를 예측하는 single network를 학습
추가적으로 annotated image 의 semantic label을 예측한다.
개념적으로는 semi-supervised learning 방법이며, self-supervised 와 semi-supervised를 연결하는 framework를 제안한다.
Take-home Message
no unlabeled data로 학습된(=labeled data로만 학습된) baseline을 carefully tuning시 S4L이 높은 성능을 내며, self-supervised leaning을 활용하는 semi-supervised learning이 self-supervised 만 사용하는 것보다 성능이 좋다.
5. Meta Pseudo Labels
Meta Pseudo Labels, CVPR 2021
기존의 Pseudo Labels 방법론은 teacher 모델이 fixe되어 있어 teacher model이 생성한 pseudo label의 quality가 좋지 않을 경우(= pseudo label이 부정확할 경우) student model도 부정확한 데이터를 학습하므로 성능이 떨어질 수 밖에 없다. 본 논문에서는 이러한 단점을 해결하는 학습방법을 제안한다.
Abstract
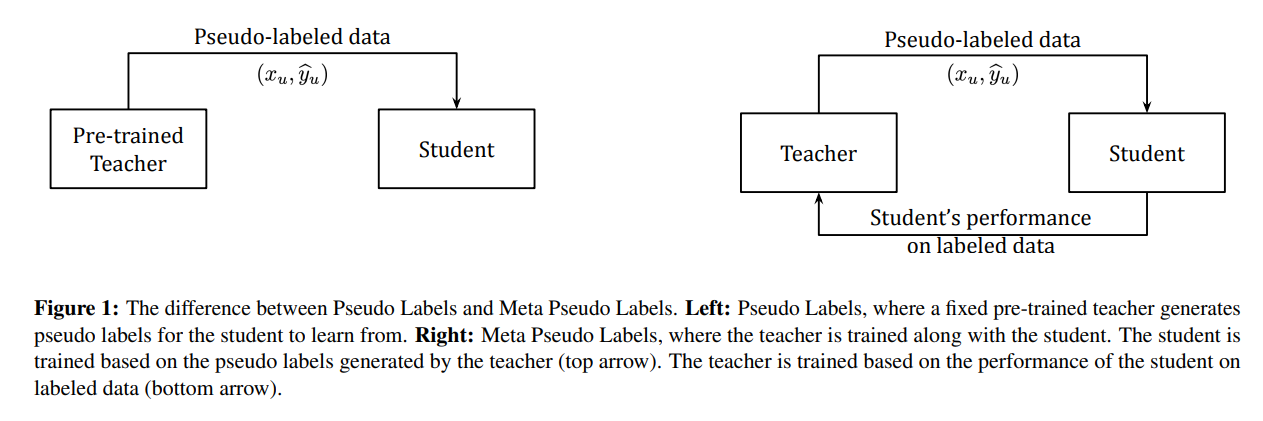
MPL에서는 student model의 validation set(labeled data)에 대한 성능을 측정하고 이를 feedback으로 삼아 teacher model 또한 update한다. 즉 teacher와 student가 동시에 학습된다.
1. student는 teacher가 생성한 minibatch of pseudo labeled data를 학습한다.
2. teacher는 minibatch drawn from the labeled dataset에 대한 student의 성능을 reward signal로 고려하고 학습된다.
학습 과정은 다음과 같다.
1. teacher model이 student model을 학습하기 위한 conditional class distribution을 생성한다.
2. 입력데이터와 1에서 생성한 conditional dictribution pair가 student model의 입력으로 들어가고 cross-entropy loss에 의해 student model의 parameter가 업데이트된다.
3. student model이 업데이트되면, held-out validation dataset을 사용하여 student의 new-parameter를 evaluate한다.(hold-out dataset : Sometimes referred to as “testing” data, a holdout subset provides a final estimate of the machine learning model’s performance after it has been trained and validated.)
student의 new-parameter는 teacher model에 의존적이므로 그 의존성이 teacher model의 parameter를 업데이트할 loss(gradient)를 계산하도록 한다. 수식으로 보면 아래와 같다.
(1) Pseudo Labels (PL) trains the student model to minimize the cross-entropy loss on unlabeled data
는 궁극적으로 labeled data 에 대한 loss를 작게 만든다.
(2) the optimal student param 는 teacher parameter 에 의존적이다. 이때 dependency =
이고, 이를 반영한 을 최적화한다.
Take-home Message
PL 방법론의 단점을 해결하기 위해 teacher model과 student model을 동시에 학습시켜 teacher model로 하여금 더 좋은 pseudo label을 생성하도록 했다.
6.EnAET
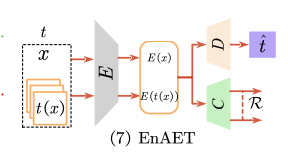
Abstract
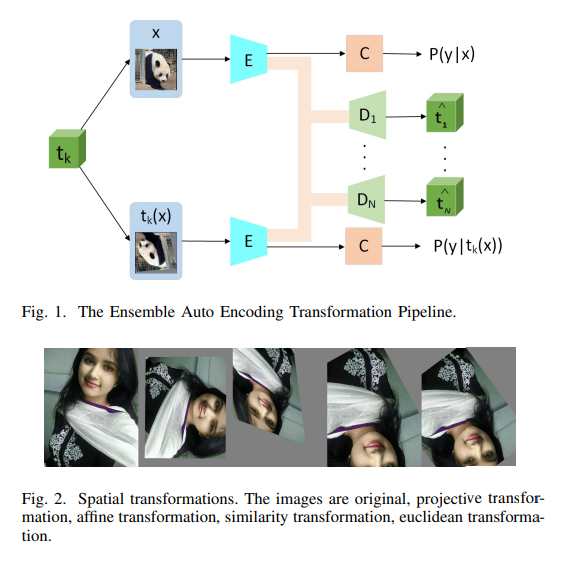 S4L 과 달리 EnAET는 모델의 학습능력 향상을 위해 Auto-Encoding Transformations 의 Ensemble을 학습한다.
S4L 과 달리 EnAET는 모델의 학습능력 향상을 위해 Auto-Encoding Transformations 의 Ensemble을 학습한다.
Auto-Encoder : 입력이 들어왔을 때, 해당 입력 데이터를 최대한 compression 시킨 후, compressed data를 다시 본래의 입력 형태로 복원 시키는 신경망. 이때, 데이터를 압축하는 부분을 Encoder라고 하고, 복원하는 부분을 Decoder라고 부른다. 압축 과정에서 추출한 의미 있는 데이터 Z를 보통 latent vector라고한다.
Encoder 모델이 학습을 통해 자동적(automatically)으로 latent vector를 찾아준 것 - 고차원 데이터를 잘 표현해주는 latent vector를 자동으로 추출해주는 모델.
data의 compressed representation(=latent vector)를 찾기 위한 Auto Encoder의 학습방식은 unsupervised learning(=self-supervised learning) 이라고 할 수 있다.
이 프레임워크의 핵심은 EnAET가 공간(spatial) 및 비공간(nonspatial) 변환의 앙상블을 통합하여 우수한 feature representation을 self-train한다는 것이다.
EnAET는 4개의 spatial transformations과 combined non-spatial transformation을 통합한다.
-
spatial transformations
Projective transformatio
Affine transformation
Similarity transformation
Euclidean transformation -
non-spatial transformation
composed of different colors, contrast, brightness and sharpness with four strength parameters.
EnAET는 original instance와 그것의 transformations에 대해 encoder E를 학습한다.
그동안,
decoder D는 input transformation인 를 추정하기 위해 학습된다.
이렇게 해서 Auto-Encoding Transformation(AET) loss 를 얻을 수 있다.
EnAET는 이 AET loss를 SSL loss 에 regularization term으로 추가한다.
AET loss와는 별개로 EnAET는 original sample x에 대한 P(y|x)와 transformation t(x)에 대한 P(y|t(x)) 사이의 KL-divergence 를 최소화하여 pseudo-labeling의 일관성을 향상시킨다.
Take-home Message
Transform의 emsemble을 예측하는 Auto-Encoder 학습으로 우수한 feature representation을 학습할 수 있다.
7. SimCLRv2
Big Self-Supervised Models are Strong Semi-Supervised Learners, 2020
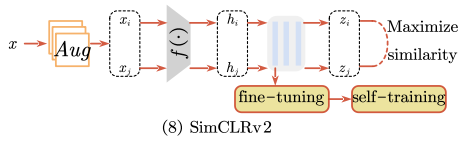
SimCLR 에서 연장된 SimCLRv2는 self-supervised learning으로 뽑아낸 representation을 이용하여 semi-supervised learning을 수행한다.
Abstract
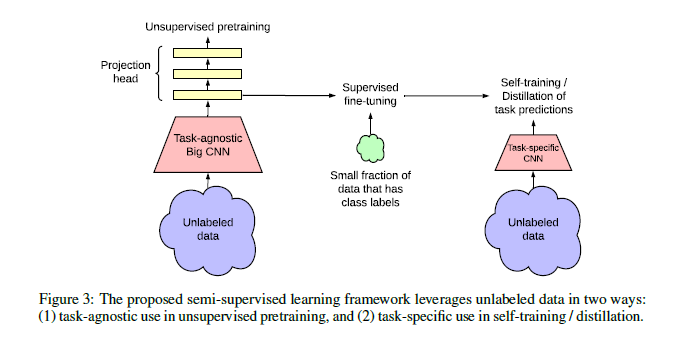
unsupervised pretraining 이후에 supervised fine-tuning을 하는 방법.
SimCLRv2는 task-specific이 아닌 task-agnostic한 방법으로 unlabeled data를 사용하여 pretraining을 하고
이때 (deep and wide)한 big-model을 사용하면 semi-supervised learning에 효과적임을 보인다.
(큰 모델이 self-supervised learning이나 그 이후의 fine tuning에서 성능상의 강점이 있다.)
학습은 다음의 3단계로 요약된다.
1. unsupervised or self-supervised pre-training
2. supervised fine-tuning on 1% or 10% labeled samples
3. self-training with task-specific unlabeled examples (=distillation)
첫번째 pre-training 단계에서는 letent space의 contrastive learning loss를 최대화하는 방향으로 representation을 학습한다.
해당 loss function은 같은 sample에 다른 augmentation이 적용되었어도 일관성을 유지하도록 한다.
(i, j) is a pair of positive example augmented from the same sample
sim(·, ·) is cosine similarity
τ is a temperature parameter
세번째 self-training 단계에서는 fine-tuning 이후에 model을 compact하게 개량하기 위해 task-specific하게 unlabeled sample을 사용하여 distillation을 수행한다.
이를 위해 fine-tuning network를 teacher model로 두고 teacher model의 pseudo label을 이용해서 더 작은 student model을 학습한다.
이때 distillation loss는 다음과 같다.
and are produced by teacher network and student network, respectively.
Take-home Message
큰 모델을 이용한 self-supervised learning으로 뽑아낸 representation을 이용하여 semi-supervised learning을 하면 적은 양의 labeled data를 사용할 때에 성능이 좋다.
Summary
일반적으로 self-training은 pseudo-label이나 unlabeled data를 통해 더 많은 양의 training data를 얻는 방법이다.
EntMin과 pseudo-label 방법론은 entropy minimization을 사용하여 더 높은 confidence score를 가지는 pseudo-label을 unlabeled data의 ground truth로 가정한다.
Noisy Student는 student network를 학습할 때 data augmentation, dropout and stochastic depth와 같은 다양한 기술을 사용한다.
S4L은 data augmentation technique을 사용함과 동시에 4-category task를 추가하여 model의 성능을 높인다.
MPL은 student model로부터 feedback을 받아 teacher model 또한 학습을 진행하기 위해 Pseudo-label을 변형한 방법이다.
Emerging techniques (e.g., rich data augmentation strategies, metalearning, self-supervised learning )과 network architectures (e.g., EfficientNet, SimCLR)를 통해 self-training이 발전하였다.
연구의 흐름 쫓아가보기
연구의 흐름을 보면 self-training이 어떻게 발전하고 있는지 알 수 있다.
처음에는 semi-supervised learning, 즉 unlabeled data의 예측/pseudo label의 정확성을 높이기 위한 연구가 활발하다. 이후에는 self-supervised learning에서 모델로 하여금 data를 잘 표현하는 representation을 얻는 연구가 활발해진다.
조금 더 자세히 살펴보면 먼저 semi-supervised learning의 연구 예시는
entropy minimazation을 통해 unlabeled data의 예측에 대한 confidence를 높이거나,
Noisy Student와 같이 student model 학습 시 noise를 주어 모델의 일반화 성능을 향상시킨다. Psuedo label - MPL 의 발전과 같이 teacher model로 하여금 더욱 정확한 pseuso label을 만들게 하는 연구가 이루어진다.
반면 self-supervised learning에서는 2014년 Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks라는 논문에서 Pretext task 라는 개념을 처음으로 제시한다. 이는 사용자가 정의한 새로운 문제를 뜻하는데, 이 pretext task를 학습하면서 데이터 자체에 대한 이해를 높일 수 있다.
 위 논문에서는 그림과 같이 좌상단 opriginal image를 다양하게 augmentation을 주어 많은 이미지를 생성하고, 그 이미지마다 개별 class를 부여한다. 그리고 분류기로 하여금 이 이미지들을 모두 같은 class로 분류하도록 학습시킨다.
위 논문에서는 그림과 같이 좌상단 opriginal image를 다양하게 augmentation을 주어 많은 이미지를 생성하고, 그 이미지마다 개별 class를 부여한다. 그리고 분류기로 하여금 이 이미지들을 모두 같은 class로 분류하도록 학습시킨다.
이러한 방법의 문제는 데이터(원본 이미지와 변환된 모든 이미지)의 갯수가 class 수가 되므로 큰 데이터셋에는 적용이 어렵다는 점이다. 그래서 self-supervised learning에서 새로운 학습 방법인 Contrastive learning이 등장하게 된다.
Contrastive learning은 지도학습의 학습 결과에서 아이디어를 얻었다.
 지도학습 기반으로 분류기를 학습시키면, 비슷한 이미지들의 logits이 높게 나오는 것을 보고 잘 추출된 특징값(rerpresentation)은 instance간의 유사도 정보를 가지고 있을 것이라는 가정을 하게된다.
지도학습 기반으로 분류기를 학습시키면, 비슷한 이미지들의 logits이 높게 나오는 것을 보고 잘 추출된 특징값(rerpresentation)은 instance간의 유사도 정보를 가지고 있을 것이라는 가정을 하게된다.
따라서 Contrastive learning은 같은 class끼리는 거리가 가까워지도록(유사도가 높아지도록), 다른 class끼리는 거리가 멀어지도록 한다. 이때 같은 class는 Positive pair, 다른 class 는
Negative pair 라고 일컫는다.
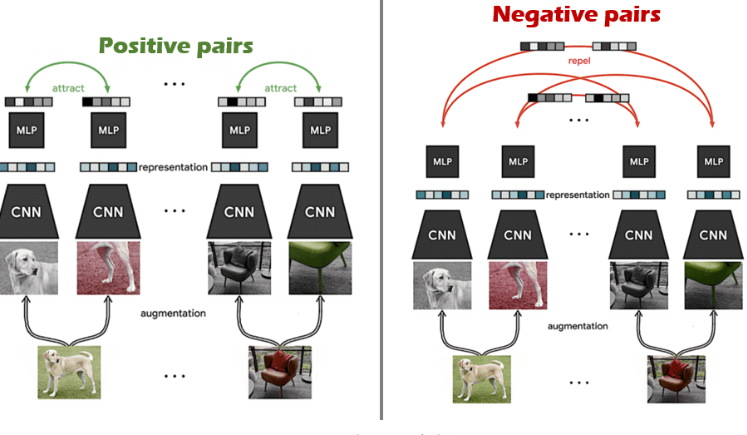
강아지와 의자는 다리가 네개라는 공통점이 있다. 두 이미지에 각각 augmentation을 취하고 같은 이미지로부터 augmentation된 것은 positive pair 로 두고 거리가 가까워지도록 학습한다. 강아지와 의자는 다른 instance이기 때문에 negative pair 로 두고 거리가 멀어지도록 학습하는 것이다.
결론은 self-supervised learning에서는 pretext task를 거쳐 Contrastive learning으로 이어지면서 data를 잘 표현하는 representation을 얻어 이들의 유사도를 높게/낮게 하는 연구가 많다. facebook의 MOCO, google의 SimCLR 가 version 2까지 나오면서 꾸준히 self-supervised learning - contrastive learning 연구가 진행되고 있다.
Ref
Semi-Supervised Learning 정리
ESTSoft Semi-supervised learning 방법론 소개
Self-Supervised Learning(자기지도 학습 설명)
Self-Supervised vs Semi-Supervised Learning 특징 차이 비교
SimCLRv2
Self-Supervised Learning (algorithm & application)

잘 읽었습니다~ 부캠 이후 논문읽기를 게을리했던 저를 돌아보게 되네요..