1. 인코딩 vs 임베딩
컴퓨터에게 단어를 숫자로 표현하기 위해서, 단어장(Vocabulary)을 만들고, 중복되지 않는 인덱스(index) 로 바꿉니다.
궁극적으로 모든 문장을 일련의 정수로 바꿔줍니다. 이를 인코딩(Encoding) 이라고 합니다.
하지만 관계없는 숫자의 나열로 인코딩하는 것은 우리가 원하는 것이 아닙니다. 여전히 주관적인 숫자들 뿐입니다.
우리는 비슷한 의미의 단어는 같이 있고, 아니면 멀리 떨어져 있는 관계를 만들고 싶습니다. 그렇다면 어떻게 관계를 만들어 줘야 할까요?
한 가지 방법으로 "One hot Encoding"이 있을 수 있습니다.
길이가 단어장의 총 길이(∣V∣)인 벡터에서, 단어의 index 위치에 있는 값은 1, 나머지는 0으로 구성합니다.
- 단점: 모든 토큰 간에 거리가 같습니다. 하지만 모든 단어의 뜻이 같지 않기 때문에 거리가 달라져야 저희가 원하는 단어간의 관계가 성립 됩니다.
어떻게 신경망이 토큰의 의미를 잡아낼수 있을까요?
결론은 각 토큰을 연속 벡터 공간(Continuous vector space) 에 투영하는 방법입니다. 이를 임베딩(Embedding) 이라고도 합니다.
- Table Look Up: 각 one hot encoding 된 토큰에게 벡터를 부여하는 과정입니다. 실질적으로 one hot encoding 벡터( x )와 연속 벡터 공간( W )을 내적 한 것 입니다.
Table Look Up 과정을 거친후 모든 문장 토큰은 연속적이고 높은 차원의 벡터로 변합니다.
2. RN vs CNN
Relation Network(Skip-Bigram):
문장안에 있는 모든 토큰 쌍(pairs)을 보고, 각 쌍에 대해서 신경망을 만들어서 문장표현을 찾습니다.
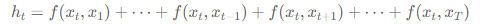
- 장점: 여러 단어로 된 표현을 탐지 할 수 있습니다.
- 단점: 모든 단어간의 관계를 보기 때문에, 전혀 연관이 없는 단어도 보게 됩니다.
Convolution Neural Network(CNN):
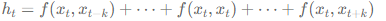
- 특징:
k-gram을 계층적으로(hierachically) 보게 됩니다.
Layer 를 쌓을 때 마다, 점진 적으로 넓은 범위를 보기 때문에, "단어> 다중 단어 표현> 구절 > 문장"순으로 보는 인간의 인식과도 알맞습니다.
1차원의 Convolutional Network 입니다.
장점: 좁은 지역간 단어의 관계를 볼수 있습니다.
3. Self Attention
RN:
모든 다른 토큰의 관계를 봅니다. 모든 단어간의 관계를 봐서 효율적이지 못합니다.
CNN:
작은 범위의 토큰의 관계를 봅니다. 따라서 더 먼 거리의 단어간의 관계가 있을 경우 탐지할 수 없거나 더 많은 convolution 층을 쌓아야합니다.
하지만 CNN 방식을 가중치가 부여된 RN의 일종으로 볼 수도 있습니다.
: filter 가 위치한 부분에만 가중치 1을 주고 나머지는 0을 주어 무시하는 방식
그렇다면 가중치가 0 과 1 이 아닌 그 사이의 값으로 계산 할 수 있다면 어떨까요?
--> Self Attention
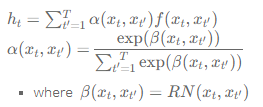
알파는 해당 관계가 중요한지 아닌지를 나타내는 weighting function(weight을 크게 줄지 작게 줄지를 결정), weight 범위 [0,1] (->sigmoid) 또는 다 더해서 1 의 contraint(->softmax)를 주는 식으로 구현
- 장점:
Long range & short range dependency 극복할 수 있습니다.
관계가 낮은 토큰은 억제하고 관계가 높은 토큰은 강조할 수 있습니다.
단점
계산 복잡도가 높고 counting 같은 특정 연산이 쉽지 않습니다.
--> 문장전체를 보는 방식 : computational efficiency 문제 있음
--> optimaization 방식 :
일반적으로 gradient 를 이용한 BP 가능 .
: loss를 보고 각 노드마다 loss func에 contribute 정도가 있음 정도에 따라 값 조절
처음에 weight이 flat할 때 : learning이 잘 진행안됨 -> parameter initialization 이 까다로움
self attention을 이용한 machine transation system 을 만들때 어떤 hyper parameter가 중요한지에 대한 technical report 있음
4. RNN
Recurrent Neural Network(RNN):
메모리를 가지고 있어서 현재까지 읽는 정보를 저장할 수 있습니다.
문장의 정보를 시간의 순서에 따라 압축 할 수 있습니다.
- 단점:
문장이 많이 길어질 수록 고정된 메모리에 압축된 정보를 담아야 하기 때문에, 앞에서 학습한 정보를 잊습니다. 이는 곧 정보의 손실을 뜻합니다.
토큰을 순차적으로 하나씩 읽어야 하기 때문에, 훈련 할때 속도가 기타 네트워크 보다 느립니다. - Long Term Dependency 해결방법:
bidirectional network를 쓰게됩니다.
LSTM, GRU 등 RNN의 변형을 사용합니다.
출처 : 조경현 교수님 강의
