1. 언어 모델이란? (LM, Language Model)
단어 시퀀스에 확률을 할당하는 모델, 이전 단어들을 이용하여 다음 단어를 예측함 // BERT는 양쪽 단어들로부터 가운데 단어 예측
통계를 이용한 방법과 인공신경망을 이용한 방법
최근에는 인공신경망 방법이 더 성능 좋음
2. 통계적 언어 모델 (SLM, Statistical Language Model)
2-1. 조건부 확률의 연쇄법칙
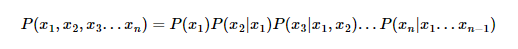
- 문장의 확률
: 각 단어들이 이전 단어가 주어졌을 때 다음 단어로 등장할 확률의 곱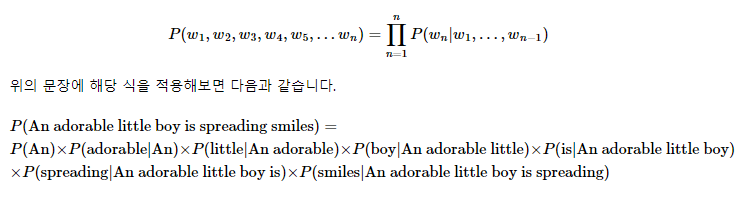
2-2. 카운트 기반의 접근

- 카운트기반의 한계 - 희소문제 (sparsity problem)
: 기계가 훈련한 코퍼스에 An adorable little boy is라는 단어 시퀀스가 없었다면 이 단어 시퀀스에 대한 확률은 0. 또는 An adorable little boy라는 단어 시퀀스가 없었다면 분모가 0이 되어 확률은 정의되지 않음.
즉 훈련 코퍼스에 확률을 계산하고 싶은 문장이나 단어가 없을 수 있다는 점.
희소문제 : 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제
희소문제 완화 : n-gram, 스무딩(분모, 분자에 숫자를 더해 카운팅 결과가 0이 되는 걸 방지), 벡오프 --> 해결은 안됨 -> 인공신경망 방법
2-4. n-gram
앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용. 그리고 이때 일부 단어를 몇 개 보느냐를 결정하는데 이것이 n-gram에서의 n이 가지는 의미.
SLM에서는 확률을 계산하고 싶은 문장이 길어질수록 갖고있는 코퍼스에서 그 문장이 존재하지 않을 가능성이 높다는 한계. 이를 해결하기 위해 참고하는 단어를 줄이는 것이 n-gram
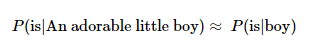
n-gram은 n개의 연속적인 단어 나열을 의미. 갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주함.
n-gram을 통한 언어 모델에서는 다음에 나올 단어의 예측은 오직 n-1개의 단어에만 의존.
- n-gram 방식의 한계
- 희소문제 여전히 존재
- n 선택에 대한 trade-off문제
n이 크면 정확도는 높아지지만 희소문제가 심각해지고 모델크기가 커짐.
n이 작으면 훈련 코퍼스에서 카운트는 잘 되지만 정확도가 떨어짐.
일반적으로 n 은 5이하가 권장됨.
모델 평가 방법
-
펄플렉서티(PPL, Perplexity)
단어의 수로 정규화(normalization) 된 테스트 데이터에 대한 확률의 역수, '낮을수록' 언어 모델의 성능이 좋음문장 W의 길이가 N 이라고 하였을 때의 PPL
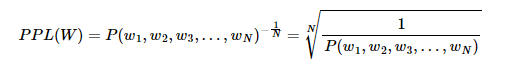
문장의 확률에 연쇄법칙 적용
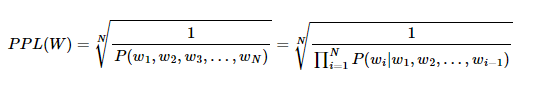
카운트 기반의 단어 표현
-
Bag of Word
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법BoW는 각 단어가 등장한 횟수를 수치화하는 텍스트 표현 방법이기 때문에, 주로 어떤 단어가 얼마나 등장했는지를 기준으로 문서가 어떤 성격의 문서인지를 판단하는 작업에 쓰임
-
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰임
- 두방법의 한계
기본적으로 단어의 빈도 수를 이용한 수치화 방법이기 때문에 단어의 의미를 고려하지 못한다는 단점
토픽 모델링(Topic Modeling)
기계 학습 및 자연어 처리 분야에서 토픽이라는 문서 집합의 추상적인 주제를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미 구조를 발견하기 위해 사용되는 텍스트 마이닝 기법.
1. 잠재 의미 분석(Latent Semantic Analysis, LSA)
TF-IDF 행렬을 만든후 SVD(특이값 분해)
장점 : 쉽고 빠르게 구현이 가능할 뿐만 아니라 단어의 잠재적인 의미를 이끌어낼 수 있어 문서의 유사도 계산 등에서 좋은 성능
단점 : SVD의 특성상 이미 계산된 LSA에 새로운 데이터를 추가하여 계산하려고하면 보통 처음부터 다시 계산해야함. 즉, 새로운 정보에 대해 업데이트가 어려움
2. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘.
BoW의 행렬 DTM 또는 TF-IDF 행렬을 입력으로 하는데, 이로부터 알 수 있는 사실은 LDA는 단어의 순서는 신경쓰지 않음.
- 수행과정
-
사용자는 알고리즘에게 토픽의 개수 k를 알려줌
-
모든 단어를 k개 중 하나의 토픽에 랜덤 할당
-
모든 문서의 모든 단어에 대해서 아래의 사항을 반복 진행
3-1. 어떤 문서의 각 단어 w는 자신은 잘못된 토픽에 할당되어져 있지만, 다른 단어들은 전부 올바른 토픽에 할당되어져 있는 상태라고 가정. 이에 따라 단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당.
단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당.
- p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
- p(word w | topic t) : 각 토픽들 t에서 해당 단어 w의 분포
잠재 디리클레 할당과 잠재 의미 분석의 차이
-
LSA : DTM을 차원 축소 하여 축소 차원에서 근접 단어들을 토픽으로 묶음.
-
LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출함.
인공신경망 모델
-
순환 신경망, Recurrent Neural Network (RNN)
// 재귀 신경망(Recursive Neural Network)과는 전혀 다른 개념입력과 출력을 시퀀스 단위로 처리하는 모델
RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징
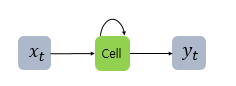
RNN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 함. (메모리 셀 또는 RNN 셀)은닉층의 메모리 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 함.
메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값을 은닉 상태(hidden state)라고 함.
다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용.RNN은 입력과 출력의 길이를 다르게 설계 할 수 있으므로 다양한 용도로 사용.
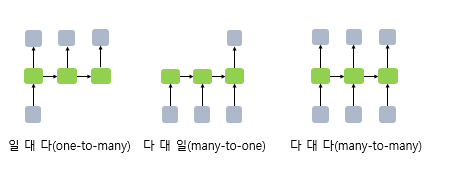
- 다 대 일
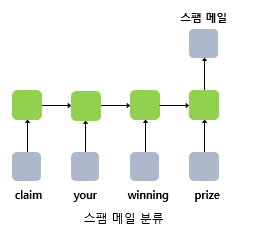
모델은 입력 문서가 긍정적인지 부정적인지를 판별하는 감성 분류(sentiment classification), 또는 메일이 정상 메일인지 스팸 메일인지 판별하는 스팸 메일 분류(spam detection)에 사용
- 다 대 다
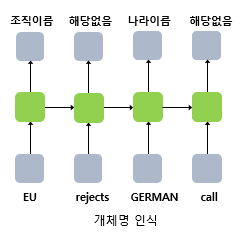
입력 문장으로 부터 대답 문장을 출력하는 챗봇과 입력 문장으로부터 번역된 문장을 출력하는 번역기, 개체명 인식이나 품사 태깅과 같은 작업
