강의 내용 복습
(06강) 모델 불러오기
model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델 형태(architechture)와 파라미터를 저장
- 모델 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
- 만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
# 모델의 파라미터 표시
model.state_dict()
# 모델의 파라미터 저장
torch.save(model.state_dict(),
os.path.join(MODEL_PATH, "model.pt"))
# 모델의 형태가 같을 경우 파라미터만 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(
MODEL_PATH, "model.pt")))
# 모델의 architecture와 함께 저장 및 load
torch.save(model, os.path.join(MODEL_PATH, "model_pickle.pt"))
model = torch.load(os.path.join(MODEL_PATH, "model_pickle.pt"))checkpoints
- 학습의 중간결과를 저장하여 최선의 결과를 선택
- earlystopping 기법 사용시 이전 학습의 결과물을 저장
- loss 와 metric값을 지속적으로 확인 저장
- 일반적으로 epoch, loss, metric을 함께 저장하여 확인
- colab에서 지속적인 학습을 위해 필요
# epoch단위로 모델의 파라미터 저장
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")pretrained model transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 일반적으로 대용량 데이터셋으로 만들어진 모델의 성능이 좋다
- 현재의 DL에서는 가장 일반적인 학습 기법
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함
- TorchVision. HuggungFace
- https://github.com/rwightman/pytorch-image-models#introduction
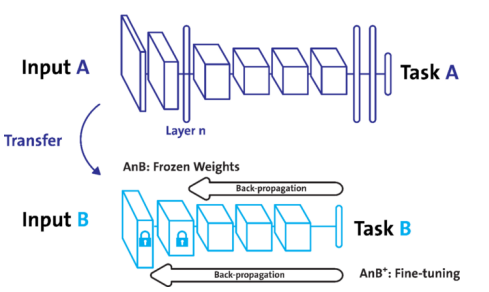
- pretrained model활용시 모델의 일부분을 frozen 시킨다.
import torch
from torchvision import models
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg = models.vgg16(pretrained=True).to(device)
vgg.fc = torch.nn.Linear(1000, 1)
vgg.cuda()
vgg = models.vgg16(pretrained=True).to(device)
# 특정 모듈만 바꿀 수도 있음
vgg.classifier._modules['6'] = torch.nn.Linear(4096, 1)
vgg.cuda()# 내가 만든 모델 + pretrained 모델
from torch import nn
from torchvision import models
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# 모델 instance 초기화
my_model = MyNewNet()
my_model = my_model.to(device)
# pretrained model parameter frozen
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
# loss, optimizer 정의
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(my_model.parameters(), lr=LEARNING_RATE)
# 학습
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = my_model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}')computer vision 모델 레포
segmentation 모델 레포
(07강) Monitoring tools for PyTorch
Tensorboard
-
Tensorflow의 프로젝트로 만들어진 시각화 도구
-
학습 그래프, metric, 학습 결과의 시각화 지원
-
PyTorch도 연결가능 -> DL 시각화 핵심도구
-
scalar : metric등 상수 값의 연속(epoch)을 표시
-
graph : 모델의 computational graph 표시
-
histogram : weight 등 값의 분포를 표현
-
Image : 예측 값과 실제 값을 비교 표시
-
mesh : 3d 형태의 데이터를 표현하는 도구
# tensorboard 기록을 위한 directory 생성
import os
logs_base_dir = "logs"
os.makedirs(logs_base_dir, exist_ok=True)
# 기록 생성 객체 SummaryWriter 생성
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# 실험 프로젝트 명 / 실험 이름
exp = f"{logs_base_dir}/ex3"
writer = SummaryWriter(exp)
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter) # add_scalar : scalar 값 기록
writer.add_scalar('Loss/test', np.random.random(), n_iter) # Loss/train(test) : Loss category에 train(test) 값
writer.add_scalar('Accuracy/train', np.random.random(), n_iter) # n_iter : x축의 값
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.flush() # 값 기록 (disk에 쓰기)
%load_ext tensorboard # colab에서 tensorboard 실행
%tensorboard --logdir "logs" # 파일 위치 지정(logs_base_dir)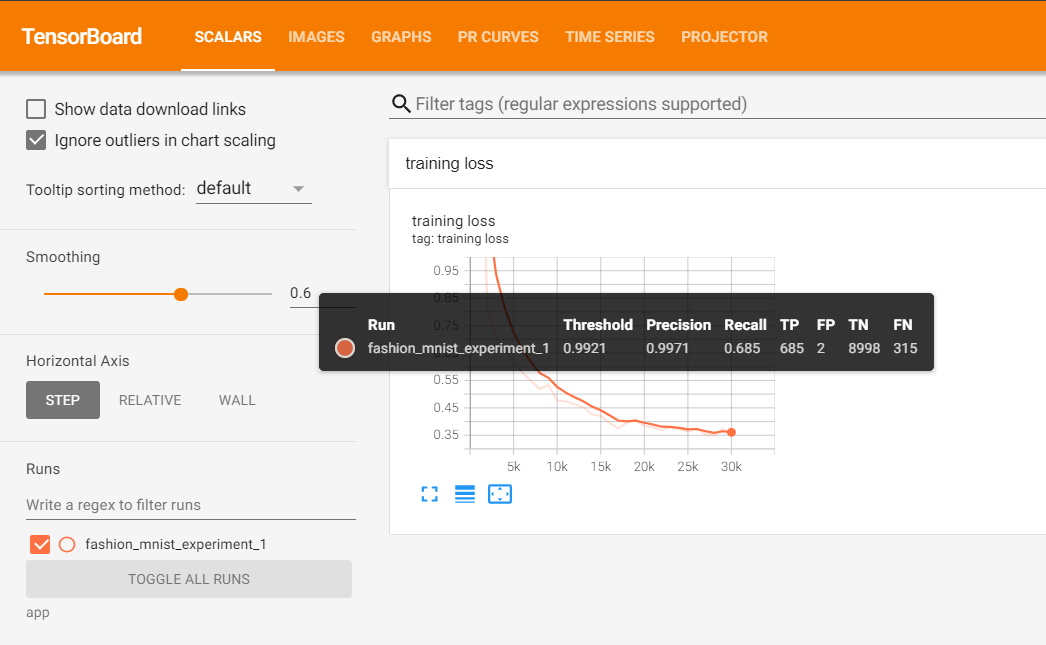
weight & biases (wandb)
- 머신러닝 실험을 원활히 지원하기 위한 상용도구
- 협업, code versioning, 실험 결과 기록 등 제공
- MLOps의 대표적인 툴로 저변 확대 중
wandb 가입
Ref
https://pytorch.org/tutorials/beginner/saving_loading_models.html
WandB monitoring tool
pytorch tensorboard
Pytorch Lightning Logger 목록들
과제 수행 과정 및 결과
Transfer Learning and Hyperparameter Tuning
imagenet으로 pretrain된 모델 사용헤서 mnist 분류하기
1. torchvision에서 imagenet으로 학습된 pretrained model 불러오기
imagenet_resnet18 = torchvision.models.resnet18(pretrained=True)- mnist 데이터셋을 본인이 불러온 모델(여기서는 resnet)에 입력으로 넣을 수 있도록 transform
common_transform = torchvision.transforms.Compose(
[
torchvision.transforms.Grayscale(num_output_channels=3), # grayscale의 1채널 영상을 3채널로 동일한 값으로 확장함
torchvision.transforms.ToTensor() # PIL Image를 Tensor type로 변경함
]
)mnist는 grayscale이기 때문체 채널을 1에서 3으로 바꾸어주었고, 데이터 타입도 PIL Image에서 tensor로 바꾸어준다.
2.5 만약 데이터셋이 아니라 모델을 변형하고 싶다면
target_model = imagenet_resnet18
FASHION_INPUT_NUM = 1
FASHION_CLASS_NUM = 10
target_model.conv1 = torch.nn.Conv2d(FASHION_INPUT_NUM, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
target_model.fc = torch.nn.Linear(in_features=512, out_features=FASHION_CLASS_NUM, bias=True)target 모델의 입력크기와 출력크기를 변환하여 준다.
- fine tuning을 위해 모델에 dense layer를 추가
MNIST_CLASS_NUM = 10
mnist_resnet18.fc = torch.nn.Linear(in_features=512 , out_features=MNIST_CLASS_NUM, bias=True) # resnet18.fc의 in_features의 크기
# 가중치 초기화
torch.nn.init.xavier_uniform_(mnist_resnet18.fc.weight)
stdv = 1 / math.sqrt(mnist_resnet18.fc.weight.shape[1])
mnist_resnet18.fc.bias.data.uniform_(-stdv, stdv)- 학습
학습시 tqdm 이용하여 print문 없이 epoch, accuracy, loss 출력하기
with tqdm(dataloaders[phase], unit = 'batch') as pbar:
for ind, (images, labels) in enumerate(pbar):
pbar.set_description(f'Epoch {epoch}')
...
학습내용
...
running_loss += loss.item() * images.size(0) # 한 Batch에서의 loss 값 저장
running_acc += torch.sum(preds == labels.data) # 한 Batch에서의 Accuracy 값 저장
pbar.set_postfix(running_loss=loss.item() * images.size(0), running_accuracy=torch.sum(preds == labels.data).item() / len(labels) * 100.)
sleep(0.1)이렇게 하면 학습이 되는 과정에서 batch별 running acc과 loss가 실시간으로 업데이트 되는것을 볼수 있다. 아래 이미지에서 progress bar로 출력한 것은 한 epoch안에서 모든 iteration마다 update되고, print문은 하나의 epoch이 끝나고 평균 loss, accuracy를 출력한 것이다.
Hyper Parameter Tuning - Ray Tune
Ray는 Distributed application을 만들기 위한 프레임워크로, 분산 컴퓨팅 환경에서 많이 사용되고 있다. Ray 프레임워크 안에 있는 Tune이라는 라이브러리를 통해 간단하게 학습 파라미터 튜닝을 할 수 있다.
Tune을 사용할 때에는 2가지 progress로 나누어 생각한다.
- Tuning의 목적 정하기 (종속변인)
Hyper Parameter Tuning을 할 때에, 사용자가 정한 Objective가 존재해야 해당 값을 최대/최소화하는 값을 찾을 수 있다. 본 실습에서는 Fashion-Mnist의 Test 데이터셋의 Accuracy의 "최대화"를 목표로 한다. - Tuning할 Hyper Parameter 정하기 (조작변인, 통제변인)
딥러닝 학습을 할 때에도 조정하며 최적 값을 찾아볼 "조작변인", 그리고 값을 고정시킬 "통제변인"이 있다. "종속변인"은 1에서 정한 Objective!
실습에서는 "조작변인"은 빠른 실험을 위해 Epoch과 BatchSize, Learning Rate로 정하고, "통제변인"은 모델 구조 ImageNet Pretrained Resnet18, All Not-Freeze Fine Tuning으로 설정한다.
- 설치
!pip uninstall -y -q pyarrow
!pip install -q -U ray[tune]
!pip install -q ray[debug]피어 세션
통계학 스터디 질문


c. 2차원 분포의 최빈값을 구할 때 헤세행렬(Hessian Matrix : 이계도함수의 행렬)의 행렬식 (determinant)가 0보다 커야한다는 풀이가 있는데 이것이 의미하는 것은?
mode는 pdf그래프에서 극댓값(peak)를 의미한다. 즉 극댓값을 찾는 것이 mode값을 찾는 것과 같다. 1번 미분한 값이 0이 되고, 2번 미분한 값이 0보다 작으면 극댓값이라는 것을 single variable에서는 바로 판단할 수 있지만 multi-variable에서는 이계도함수들을 모아놓은 Hessian matrix의 eigenvalue 부호로 판단해야 한다. eigenvalue들이 모두 음수라면 극댓값, eigenvalue들이 모두 양수라면 극솟값, 부호가 다르다면 안정점이라고 한다. 아래 Theorem을 통해 어떤 행렬의 determinant는 그 행렬의 eigenvalue들의 곱으로 표현할 수 있고, 위 task에서 hessian matrix의 determinant 부호가 양수인 것은 해당 point에서 극값을 가지는지 여부를 판단하는 기준이 되는 것이다.
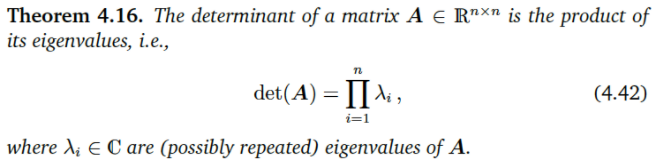
학습 회고
최성철 교수님의 마스터 강의에서 그동안 고민하던 것의 해답을 얻을 수 있었다.
부스트캠프를 진행하며 강의를 듣고 과제를 하는 것만으로는 현업에서 필요로 하는 AI Engineer가 될 수 없을 것 같아 어떤 활동을 더 해야할까하는 고민, 또 지금 내가 하는 공부방향이 맞는걸까 무엇을 더 공부해야할까 하는 고민이 있었다.
교수님께서 아주 명확하게 말씀해주셔서 앞으로의 공부 계획과 방향을 세울 수 있겠다!

회고해주세요..