[U stage DAY 14] pytorch (4) - multi GPU, hyperparameter tuning, trouble shooting
AI Boostcamp 2기
목록 보기
13/48
강의 내용 복습
(08강) Multi-GPU 학습
개념
- single vs multi
- GPU vs Node
node: 1대의 컴퓨터 - single Node Single GPU
한대의 컴퓨터에 한대의 GPU - single Node Multi GPU
한대의 컴퓨터에 여러대의 GPU - Multi Node Multi GPU
여러개의 컴퓨터에 여러대의 GPU (ex. GPU가 다 달려있는 서버실)
Model parallel
- 다중 GPU에 학습은 분산하는 두가지 방법 : 모델 나누기 / 데이터 나누기
- 모델을 나누는 것은 생각보다 예전부터 썼음 (alexnet)
- 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
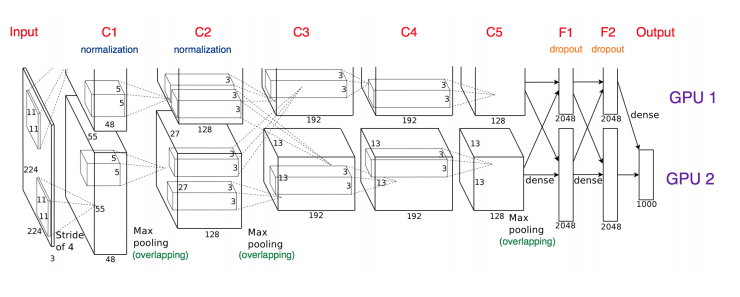
C2->C3에서 교차하는 부분 : GPU 간 병렬적인 채널 지원
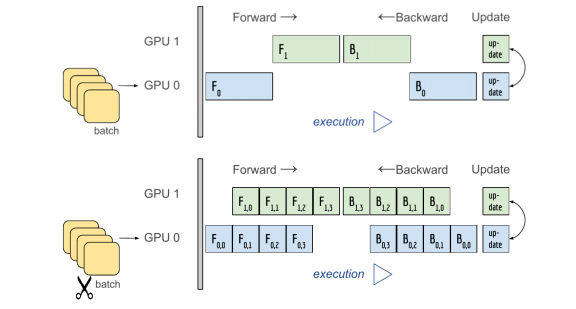
병렬화를 잘못하면 위의 예시처럼 하나가 끝나야 다음 걸 수행하게 됨.
아래의 예시가 이상적인 경우
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kargs):
...
self.seq1 = nn.Sequential(
self.conv1, self.bn1, ...
).to('cuda:0') # 첫번째 모델을 cuda 0 에 할당
self.seq2 = nn.Sequential(
self.layer3, self.layer4, ...
).to('cuda:1') # 두번째 모델을 cuda 1 에 할당
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1')) # 두 모델을 연결
return self.fc(x.view(x.size(0), -1))
Data Parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch 수식과 유사한데 한번에 여러 GPU에서 수행

- pytorch에서는 아래 두가지 방식을 제공
- DataParallel
단순히 데이터를 분배한 후 평균을 취함
GPU 사용 불균형 문제 발생, Batch 사이즈 감소 (한 GPU가 병목), GIL - DistributedDataParallel
각 CPU마다 process 생성하여 개별 GPU에 할당
기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄
- DataParallel
# DataParallel
parallel_model = torch.nn.DataParallel(model)
predictions = parallel_model(inputs)
loss = loss_function(predictions, labels)
loss.mean().backward() # average GPU loss + backward loss
optimizer.step()
---------------------------
# DistributedDataParallel
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=True,
pin_memory=pin_memory, num_workers=3,
shuffle=shuffle, sampler=train_sampler)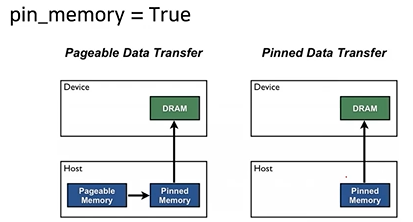
(09강) Hyperparameter Tuning
- 모델 스스로 학습하지 않는 값은 사람이 지정
(learning rate, 모델의 크기, optimizer 등) - 하이퍼 파라메터에 의해서 값의 크게 좌우 될 때도
있음 (요즘은 그닥?) - 마지막 0.01을 쥐어짜야 할 때 도전해볼만
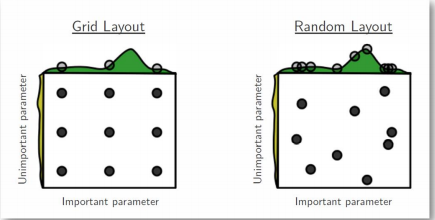
- 가장 기본적인 방법 – grid vs random
- 최근에는 베이지안 기반 기법들이 주도
Ray
- multi-node multi processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- 기본적으로 현재의 분산병렬 ML/DL 모듈의 표준
- Hyperparameter Search를 위한 다양한 모듈 제공
Further Question
- 모델의 모든 layer에서 learning rate가 항상 같아야 할까요?
- ray tune을 이용해 hyperparameter 탐색을 하려고 합니다. 아직 어떤 hyperparmeter도 탐색한적이 없지만 시간이 없어서 1개의 hyperparameter만 탐색할 수 있다면 어떤 hyperparameter를 선택할 것 같나요?
(10강) PyTorch Troubleshooting
GPU에서의 Out Of Memory (OOM)
- 왜 발생했는지 알기 어려움
- 어디서 발생했는지 알기 어려움
- Error backtracking 이 이상한데로 감
- 메모리의 이전상황의 파악이 어려움
Batch Size ⬇⬇ -> GPU clean -> Run
프로그래밍 도중 디버깅하기 어려운 GPU 사용시 발생할 수 있는 문제들이 발생할 때 GPU 메모리 디버깅을 도와주는 툴
GPUUtil 사용하기
- nvidia-smi 처럼 GPU의 상태를 보여주는 모듈
- Colab은 환경에서 GPU 상태 보여주기 편함
- iter마다 메모리가 늘어나는지 확인!!

torch.cuda.empty_cache() 써보기
- 사용되지 않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del 과는 구분이 필요
- reset 대신 쓰기 좋은 함수
- 매번쓰기 힘들면 학습전에 코드 넣어서 확인해보기
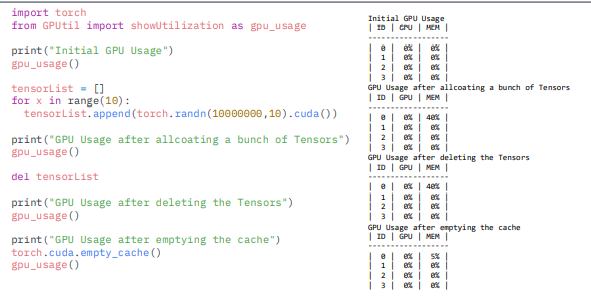
https://blog.paperspace.com/pytorch-memory-multi-gpu-debugging/
trainning loop에 tensor로 축적 되는 변수는 확인할 것
- tensor로 처리된 변수는 GPU 상에 메모리 사용
- 해당 변수 loop 안에 연산에 있을 때 GPU에
computational graph를 생성(메모리 잠식) - 1-d tensor의 경우 python 기본 객체로 변환하여 처리할 것 -> .item 이나 float 쓰면 기본객체로 변환됨

del 명령어를 적절히 사용하기
- 필요가 없어진 변수는 적절한 삭제가 필요함
- python의 메모리 배치 특성상 loop 이 끝나도 메모리를 차지함
가능 batch 사이즈 실험해보기
- 학습시 OOM 이 발생했다면 batch 사이즈를 1로 해서 실험해보기

torch.no_grad() 사용하기
- Inference 시점에서는 torch.no_grad() 구문을 사용
- backward pass 으로 인해 쌓이는 메모리에서 자유로움
예상치 못한 에러 메세지
- OOM 말고도 유사한 에러들이 발생
- CUDNN_STATUS_NOT_INIT 이나 device-side-assert 등
- 해당 에러도 cuda와 관련하여 OOM의 일종으로 생각될 수 있으며, 적절한 코드 처리의 필요
주의
colab에서 너무 큰 사이즈는 실행하지 말 것
(linear, CNN, LSTM)
- CNN의 대부분의 에러는 크기가 안 맞아서 생기는 경우(torchsummary 등으로 사이즈를 맞출 것)
- tensor의 float precision을 16bit로 줄일 수도 있음
Ref
8강
pytorch lightning multi GPU 학습
DDP 튜토리얼
9강
Pytorch와 Ray 같이 사용하기
10강
pytorch에서 자주 발생하는 에러질문
OOM시에 GPU 메모리 flush하기
GPU 에러 정리
과제 수행 과정 및 결과
--
피어 세션
- OOM 해결하는 하나의 방법 : Mixed Precision
- 통계학 문제풀이 스터디
학습 회고
keep
할일 미루지 말고 꼭!! 끝내고 자기
모르는 것, 얘기 나누고 싶은 것을 팀원들과 나누면 더욱 깊이 있는 공부를 할 수 있다!
problem
논문 읽고, 구현하는 경험이 꼭 필요한데 아직 시작을 못했다
try
필수 논문 읽고, 클론 코딩이라도 좋으니 구현 연습하기!

ML/AI Engineer