대회 (연습대회임)
https://dacon.io/competitions/open/235536/overview/description
코드
1. 라이브러리 및 데이터 불러오기
import pandas as pd
import lightgbm as lgb
# 데이터 불러오기
train = pd.read_csv('/content/drive/MyDrive/ml/dacon/영화관객수예측연습/movies/movies_train.csv')
test = pd.read_csv('/content/drive/MyDrive/ml/dacon/영화관객수예측연습/movies/movies_test.csv')
submission = pd.read_csv('/content/drive/MyDrive/ml/dacon/영화관객수예측연습/movies/submission.csv')2. EDA
train.head()
Column_name Description
1 title : 영화의 제목
2 distributor : 배급사
3 genre : 장르
4 release_time : 개봉일
5 time : 상영시간(분)
6 screening_rat : 상영등급
7 director : 감독이름
8 dir_prev_bfnum : 해당 감독이 이 영화를 만들기 전 제작에 참여한 영화에서의 평균 관객수(단 관객수가 알려지지 않은 영화 제외)
9 dir_prev_num : 해당 감독이 이 영화를 만들기 전 제작에 참여한 영화의 개수(단 관객수가 알려지지 않은 영화 제외)
10 num_staff : 스텝수
11 num_actor : 주연배우수
12 box_off_num : 관객수
test.head()
submission.head()
print(train.shape)
print(test.shape)
print(submission.shape)(600, 12)
(243, 11)
(243, 2)
train.info()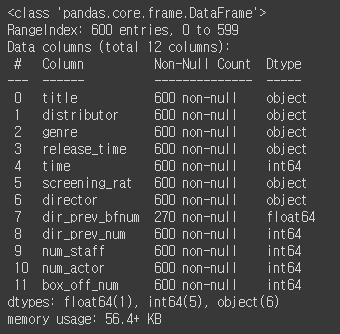
dir_prev_bfnum(해당 감독이 이전에 만든 영화의 관객 수) 에 결측치 있음
test.info()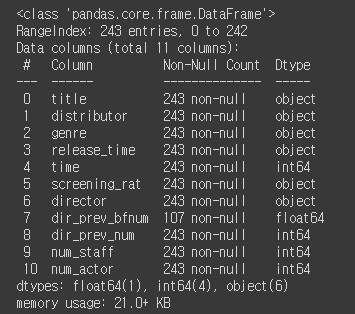
마찬가지 dir_prev_bfnum(해당 감독이 이전에 만든 영화의 관객 수) 에 결측치 있음
수치변수들 통계량 확인
train.describe().T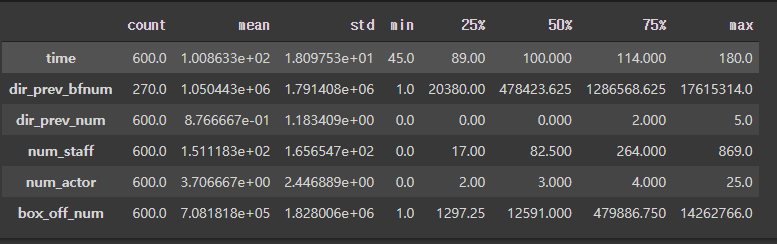
test.describe().T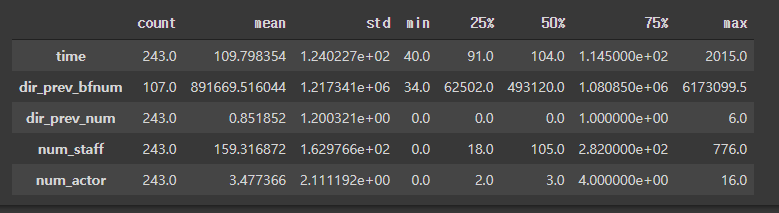
# 장르별 관객수
train[['genre', 'box_off_num']].groupby('genre').mean().sort_values('box_off_num')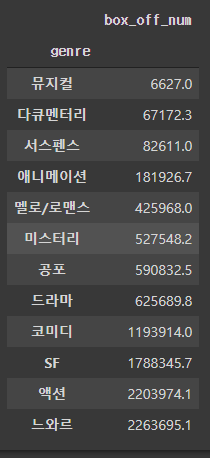
변수간 상관계수 확인
# heatmap 사용 불가 시
corr_mat = train.corr()
corr_mat['box_off_num'].sort_values(ascending =False)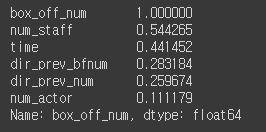
히스토그램으로 변수 분포 확인
# 히스토그램
import matplotlib.pyplot as plt
%matplotlib inline
train.hist(bins = 50, figsize = (20,15))
plt.show()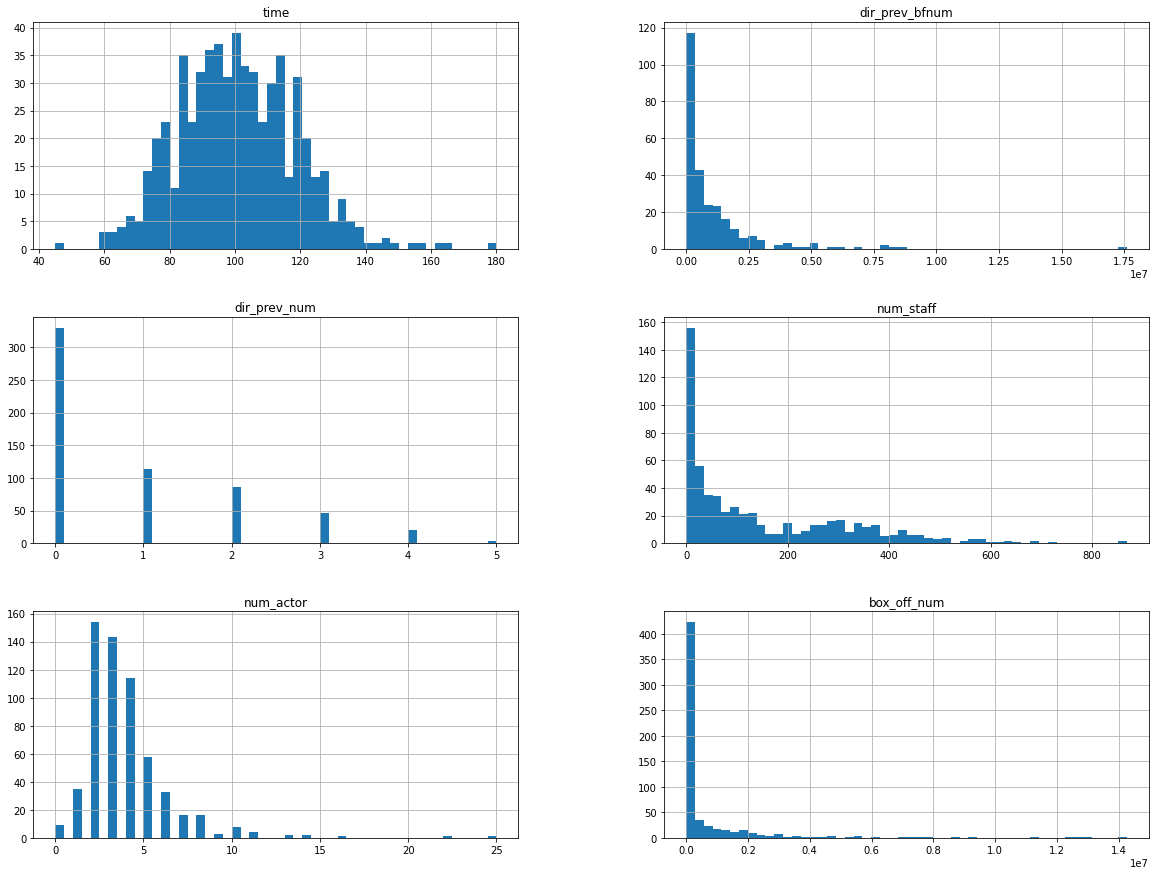
오른쪽으로 꼬리가 긴 분포를 가진 변수에는 log 변환 필요
| 변수 | 일반적인 변환 |
|---|---|
| 매출, 판매수량, 가격, 가구소득 | |
| 지리적 거리 | , |
| 효용에 근거한 시장점유율, 선호점유율 | |
| 우측으로 꼬리가 긴 분포 | , |
| 좌측으로 꼬리가 긴 분포 |
2. 전처리
- 결측치 제거
- 장르 별 관객 수 평균값으로 rank 인코딩(genre_rank)
- 배급사 별 관객 수 중앙값으로 rank 인코딩(dist_rank)
- 상영등급 pd.get_dummies 로 더미변수로 만들기(screening_rat)
X_train = pd.get_dummies(columns=['screening_rat'], data = X_train)
X_test = pd.get_dummies(columns=['screening_rat'], data = X_test)- target값인 관객 수 로그변환
y_train = np.log1p(y_train)예측한 값은 다시 원래 분포로 돌려놔야 함
pred = np.expm1([0 if x<0 else x for x in model.predict(X_train)])
- 출연 배우수 로그변환
X_train = pd.get_dummies(columns=['screening_rat'], data = X_train)
X_test = pd.get_dummies(columns=['screening_rat'], data = X_test)3. 모델링 - 변수 선택 및 모델 구축
- 학습에 사용 된 최종 독립 변수
features = ['time', 'dir_prev_num', 'num_staff', 'num_actor', 'dir_prev_bfnum', 'genre_rank', 'dist_rank', 'screening_rat']- 모델 선택은 XGBRegressor, GradientBoostingRegressor, RandomForestRegressor 를 학습데이터를 사용하여 RMSE 산출 - 가장 작은 모델 선택(XGBRegressor)
from xgboost import XGBRegressor
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.metrics import mean_squared_error
xgb = XGBRegressor(random_state = 42)
gbr = GradientBoostingRegressor(random_state=42)
rf = RandomForestRegressor(random_state=42)
md_label = ['XGBRegressor', 'GradientBoostingRegressor', 'RandomForestRegressor']
all_md = [xgb, gbr, rf]
all_rmse = []
for model, label in zip(all_md, md_label):
model.fit(X_train, y_train)
pred = np.expm1([0 if x<0 else x for x in model.predict(X_train)])
all_rmse.append({f'{label}' : mean_squared_error(y_train, pred, squared=False)})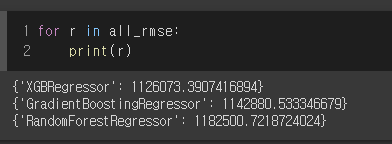
4. 모델 학습 및 검증
- from sklearn.model_selection import KFold 사용하여 5번의 cv
- cv결과 평균으로 예측 값 제출

ML/AI Engineer