1. 변수선택 없이 모든 변수 사용
만약 변수별 중요도, 영향도 등을 계산하여 변수선택을 한다면
https://wikidocs.net/16882 참고
데이터 전처리 pipe line
# 수치 변수 스케일링
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# 숫자형 컬럼 스케일링 pipeline
train_num = X_train.drop("ocean_proximity", axis=1)
num_pipeline = Pipeline([
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(train_num)
print(housing_num_tr)
# 숫자형, 범주형 컬럼 나누어서 한번에 전처리
num_attribs = list(train_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
X_train_prepared = full_pipeline.fit_transform(X_train)1. 다양한 회귀 모델 학습 및 모델 선택
# 모델링
from sklearn.linear_model import LinearRegression,Ridge,Lasso
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
# 모델 성능 평가
from sklearn.metrics import mean_squared_error # squared=False로 RMSE 바로 얻을 수 있음
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import cross_val_score
# 선형회귀
lin_reg = LinearRegression()
# Ridge
ridge_reg = Ridge()
# Lasso
lasso_reg = Lasso()
# DecisionTree
dt_reg = DecisionTreeRegressor(random_state=42)
# Random Forest ensemble
forest_reg = RandomForestRegressor(n_estimators = 100, random_state =42) # n_estimators = decision tree 개수
# SVR
svm_reg = SVR(kernel='linear')
reg_labels = ['LinearRegression', 'Ridge', 'Lasso', 'DecisionTreeRegressor',
'RandomForestRegressor', 'SVR']
all_reg = [lin_reg, ridge_reg, lasso_reg, dt_reg, forest_reg, svm_reg]
# 각 모델 학습 및 평가
all_rmse = []
for model, model_label in zip(all_reg, reg_labels):
# 학습 데이터 fit : 모델 훈련
model.fit(X_train_prepared, y_train)
# 학습 데이터 predict : 훈련세트로 모델 평가
pred = model.predict(X_train_prepared)
# rmse 확인
all_rmse.append({f'{model_label}' : mean_squared_error(y_train, pred, squared=False)})for rmse in all_rmse:
print(rmse)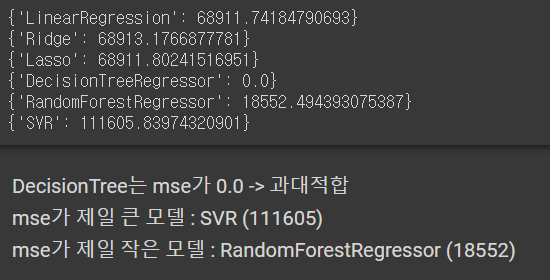
2. cross validation으로 모델 세부 튜닝
def display_scores(scores):
print("점수:", scores)
print("평균:", scores.mean())
print("표준 편차:", scores.std())
# sklearn의 교차검증 scoring매개변수 : 클수록 좋은 효용함수 기대 -> -rmse 사용
forest_scores = cross_val_score(forest_reg, X_train_prepared, y_train,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
3. GridSearchCV 로 최적의 하이퍼 파라미터 찾기
from sklearn.model_selection import GridSearchCV
param_grid = [
# 3x4 = 12개의 하이퍼 파라미터 조합
{'n_estimators':[5,10,30], 'max_features': [4,6,8,11]},
# bootstrap = False 로 하고 2x3=6개의 조합
{'bootstrap': [False], 'n_estimators':[3,10], 'max_features': [2,3,4]}
]
forest_reg = RandomForestRegressor(random_state=42)
# 다섯개의 폴드로 훈련 시 (12+6)x5 = 90개의 훈련이 일어남
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring = 'neg_mean_squared_error',
return_train_score = True)
grid_search.fit(X_train_prepared, y_train)
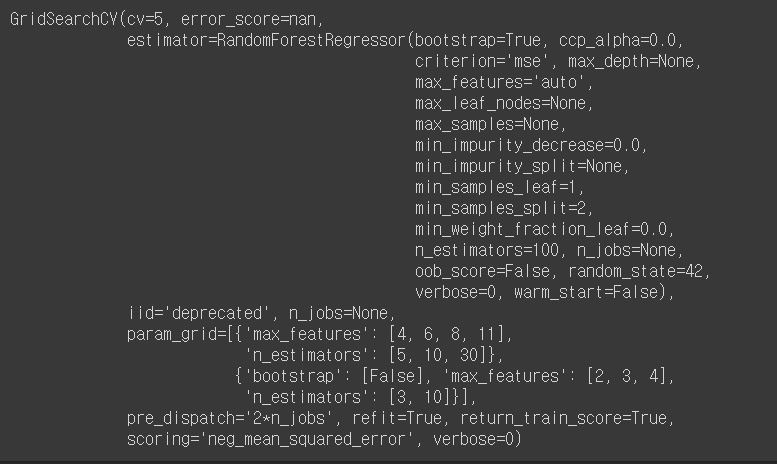
// 하이퍼 파라미터 확인 방법
# 설정할 수 있는 하이퍼 파라미터 확인
forest_reg.get_params
# 최상의 파라미터 조합
grid_search.best_params_
# 최상의 파라미터를 가진 모델
grid_search.best_estimator_
# grid search에서 테스트한 하이퍼 파라미터 조합 확인
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'], cvres['params']):
print(np.sqrt(-mean_score), params) - 최상의 파라미터 조합

- 최상의 파라미터를 가진 모델
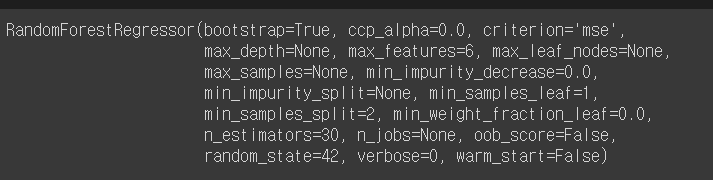
- 하이퍼 파라미터 조합

# 변수별 중요도
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ["roomPerHouse", "popPerHouse"]
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)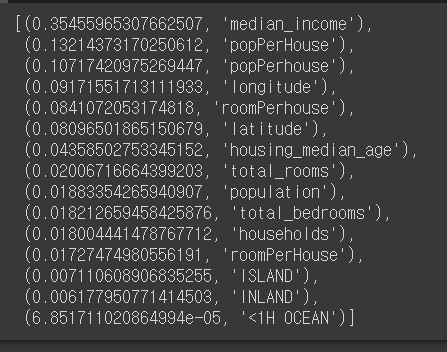
4. 최상의 모델 사용해서 테스트 데이터 예측
final_model = grid_search.best_estimator_
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
finaldf = pd.DataFrame(final_predictions, columns=['pred_median_house_value'])
finaldf.head()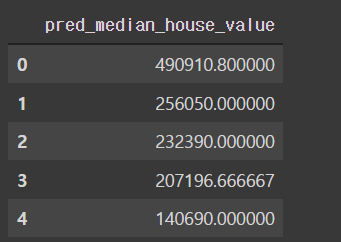
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse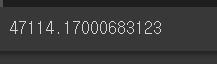

ML/AI Engineer