앙상블, 향상도 곡선을 이용한 최적 모델 선정
데이터 가져오기
!git clone https://github.com/rickiepark/handson-ml
%cd handson-ml
import pandas as pd
data_path = './datasets/housing/housing.csv'
housing = pd.read_csv(data_path)데이터 탐색
데이터 구조 훑어보기
housing.head() # 상위 5개 행
housing.info() # # 전체 행수, 각 컬럼의 데이터 타입과 널값 유무
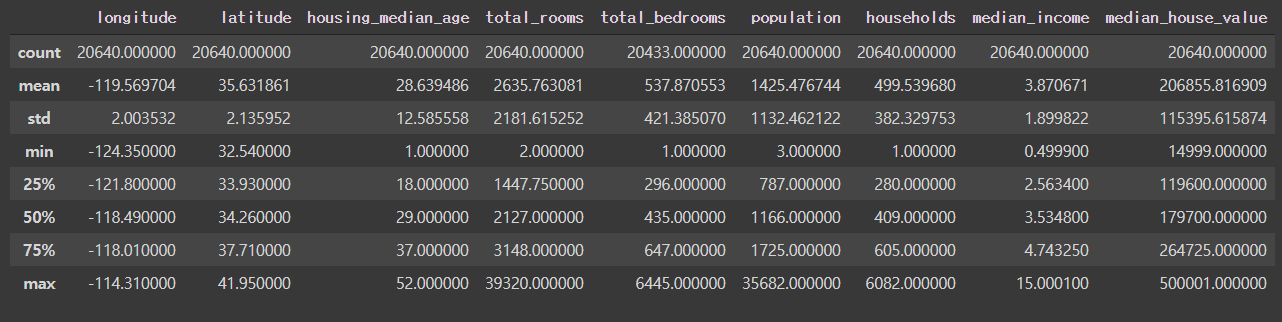
housing.describe() #수치형 변수
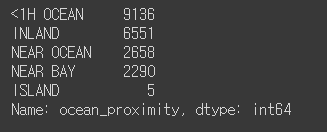
housing["ocean_proximity"].value_counts() #범주형 변수
# 히스토그램
import matplotlib.pyplot as plt
%matplotlib inline
housing.hist(bins = 50, figsize = (20,15))
plt.show()- head

- info
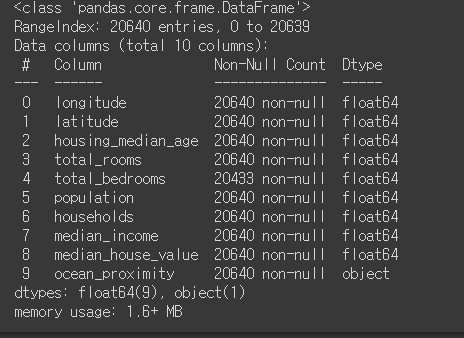
- describe
- value_counts
- 히스토그램

결측치 제거
# 결측치 확인 및 제거
housing.isnull().sum()
housing['total_bedrooms'].fillna(housing['total_bedrooms'].median(), inplace=True)
housing.isnull().sum()
상관관계 확인
# 데이터 간 상관관계 -> 모든 특성간의 피어슨상관계수
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending = False)
# 특성 간 산점도
from pandas.plotting import scatter_matrix
attrib = ['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']
scatter_matrix(housing[attrib], figsize=(20,15))
plt.show()
# 선형관계 있어보이는 애 확대
housing.plot(kind='scatter', x = 'median_income', y= 'median_house_value',alpha=0.1)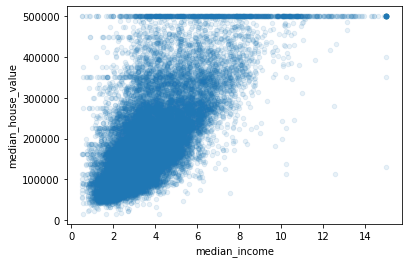
파생변수 생성
# 파생변수 생성
# 가구당 방 개수, 가구당 인구수
housing["roomPerhouse"] = housing["total_rooms"] / housing["households"]
housing["popPerhouse"] = housing["population"] / housing["households"]
# 다시 피어슨 상관계수
corr = housing.corr()
corr["median_house_value"].sort_values(ascending=False)

ML/AI Engineer