학습 / 테스트 데이터셋 나누기
계층적 샘플링
# median_income 이 종속변수와 상관계수가 높으니까 계층적 샘플링
# 계층적 샘플링을 위해 median_income 카테고리로 나누기
import numpy as np
incomes = ['median_income', 'income_cat']
housing['income_cat'] = np.ceil(housing['median_income'] / 1.5)
housing['income_cat'].hist(bins = 10, figsize=(5,5))
housing[incomes]

# income_cat이 5보다 큰건 5로 만듬
housing['income_cat'].where(housing['income_cat']<5 , 5.0, inplace = True)
housing['income_cat'].hist(bins=10, figsize=(5,5))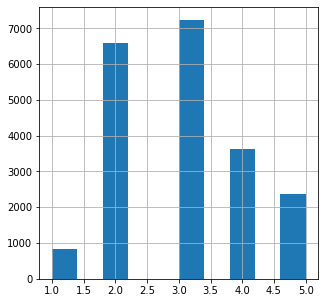
# 계층적 샘플링
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits = 1, test_size = 0.2, random_state = 42)
for train_idx, test_idx in split.split(housing, housing['income_cat']):
strat_train_set = housing.loc[train_idx]
strat_test_set = housing.loc[test_idx]
# 전체 데이터에서 소득 카테고리 비율과 비교
income_comp = pd.DataFrame({
'original' : housing['income_cat'].value_counts() / len(housing),
'strat_train' : strat_train_set['income_cat'].value_counts() / len(strat_train_set),
'strat_test' : strat_test_set['income_cat'].value_counts() / len(strat_test_set)
}).sort_index()
income_comp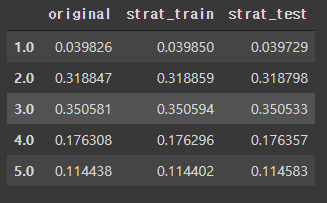
# train, test set에서 income_cat column 삭제
for set_ in (strat_train_set, strat_test_set):
set_.drop('income_cat', axis = 1, inplace=True)
strat_train_set.columns
# 라벨 분리한 데이터셋 만들기
X_train = strat_train_set.drop('median_house_value', axis = 1)
y_train = strat_train_set['median_house_value']
X_test = strat_test_set.drop('median_house_value', axis = 1)
y_test = strat_test_set['median_house_value']
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
X_train.hist(bins=50, figsize=(20,15))
plt.show()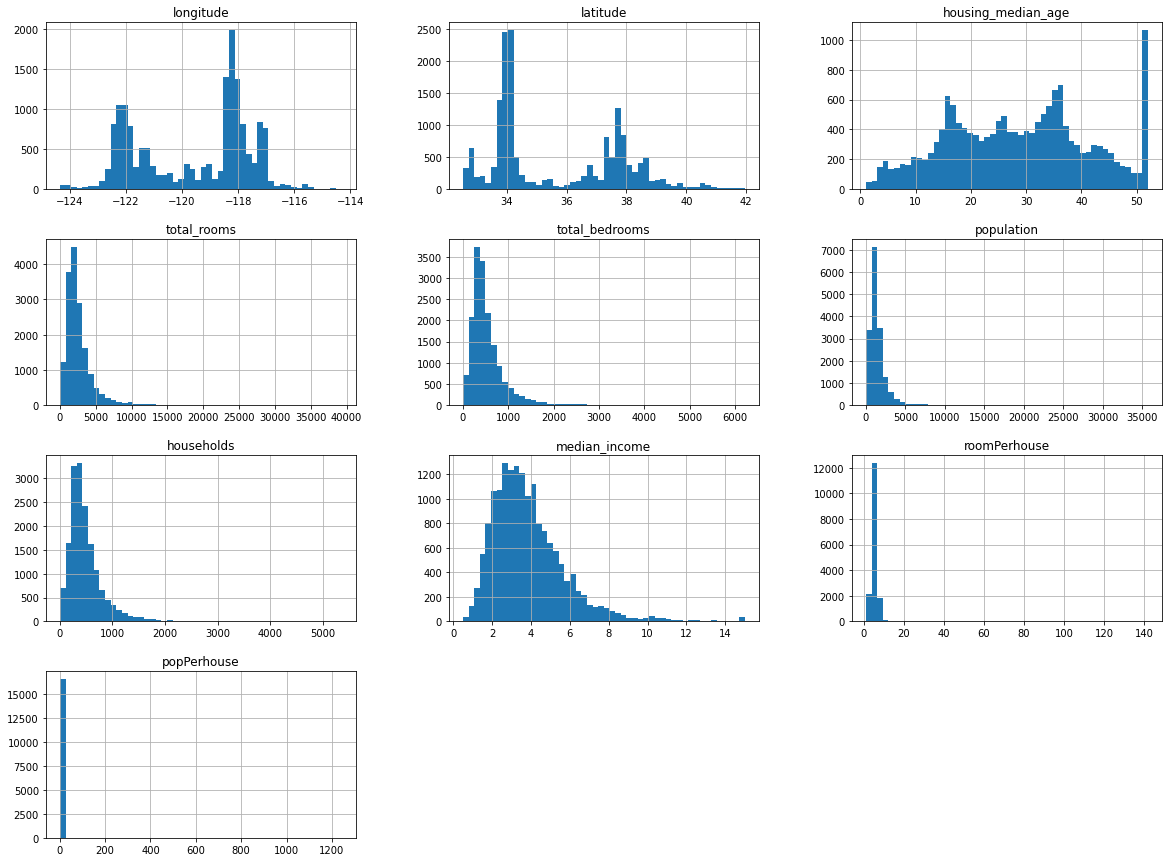
total_rooms, total_badrooms, population, households, median_income 대부분 오른쪽으로 꼬리가 김 --> log 등의 함수 적용 필요

ML/AI Engineer