Gradient Descent Methods
- Stochastic gradient descent
한 번에 하나의 샘플 데이터만 보고 이에 대해 gradient 구하고 업데이트 하겠다. - Mini-batch gradient descent
batch-size 만큼의 샘플 데이터를 보고 이에 대해 gradient를 구하고 업데이트 하겠다. - Batch gradient descent
전체 데이터를 보고 이에 대해 gradient를 구하고 업데이트 하겠다.
Batch-size Matters
batch-size를 1로 하자니 너무 오래 걸리고, 전체로 하자니 gpu memory가 터지는 문제가 발생하기 때문에 적절한 값으로 결정해야한다.
2의 거듭제곱으로 한다.
- large batch-size : sharp minimizers에 도달한다.
- small batch-size : flat minimizers에 도달한다.
=> 실험적으로 비교했을 때 flat minimizers 가 더 좋다.
(일반화 성능이 좋다라고 직관적으로 이해할 수 있다.)

1. (Stochastic) Gradient descent
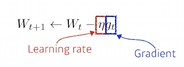
2. Momentum
batch로 진행했을 때를 예로 들면 이번의 batch의 gradient만 반영하는 것이 아니라 이전의 batch gradient도 반영하자는 아이디어이다.
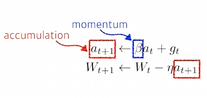
3. Nesterov Accelerated Gradient
local minimum에 빠지지 못하는 문제를 해결
4. Adagrad
현재까지 변화량을 역수로 곱해줌으로서 지금까지 많이 변화했던 parameters는 적게 변화시키고 적게 변화했던 parameters는 많이 변화시키는 아이디어이다.
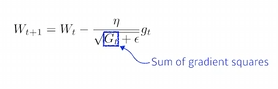
G가 점점 커지기 때문에 뒤로 갈수록 학습이 멈추게 된다.
5. Adadelta
G가 계속 커지는 것을 막겠다.
window 사이즈를 정해서 그만큼 time step의 변화량만 G에 적용하겠다.
learning rate 가 없다.!!
=> 잘 활용되지 않는다.
6. RMSprop
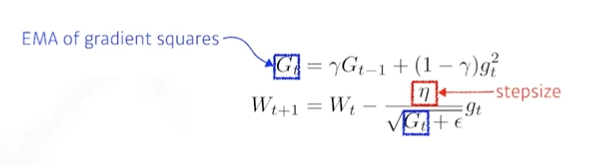
7. Adam
momentum과 Adapt의 컨셉을 같이 활용한다.
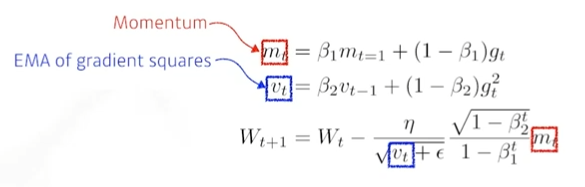
hyper parameters : beta1, beta2, lr, epsilon

연수돼지