Deep Learning 06 Backpropagation
Backpropagation :
DNN에서 컴퓨터가 파라미터 업데이트에 쓰일 Gradient를 잘 계산하도록 하는 방법

Single layer(perceptron)은 다음과 같이 y_hat에 대한 식을 입력인 x로부터 나타낼 수 있으며, f는 activation function이다.

Single layer에서의 각 input data element에 대한 gradient(밑의 노란 블록)
- 그 바로 위의 파란 형광펜처럼, weighted sum, activation funciton 통과, cost function 등의 계산 과정들이 미분될 수 있기에, Gradient를 chain rule에 따라 진행과정 부분부분의 미분으로 구할 수 있기 때문에 노란 블록에서 처럼 각 input data element에 대한 gradient를 계산할 수 있다.
- 심지어 계산이 그리 복잡하지도 않음. 그냥 기본적인 사칙연산이다.
- 참고로 네번째 줄의 C를 보면 계산 과정에서 MSE라서 Mean을 위해서 1/2가 아닌 1/n이어야할것같지만, 어차피 cost function 자체를 작게 하는 파라미터를 찾고자하는 거라서, 계수는 별 상관 없다. 그래서 미분할때 편하도록 1/2로 계수를 쓴 것이다.
- activation function은 예시에서는 sigmiod를 사용했다.
- 예시에서는 output 또한 스칼라로, 아주 간략화한 예시이다.
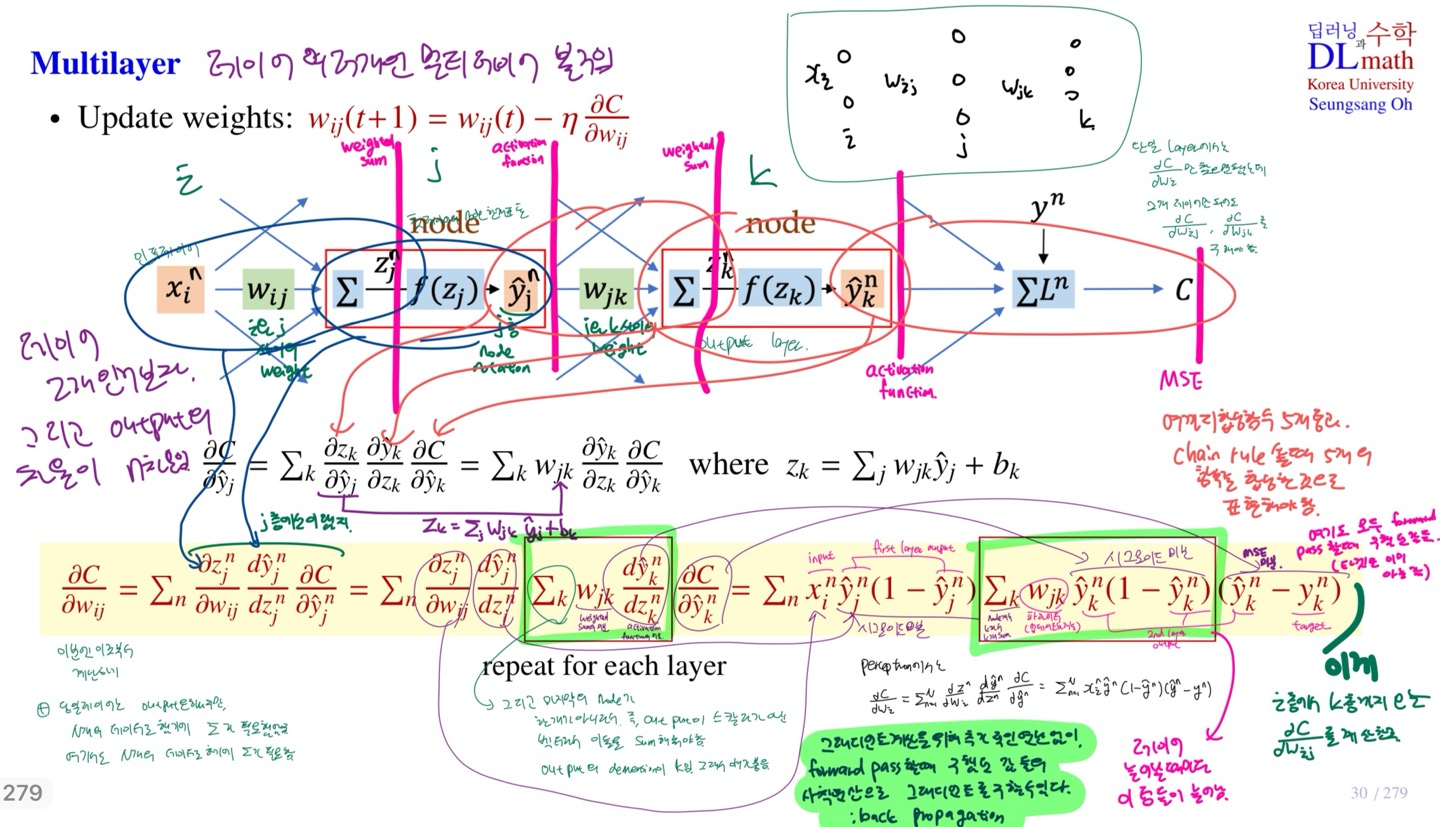
Multi layer에서의 각 input data element에 대한 gradient(밑의 노란 블록)
- layer가 많아진다고 해서 달라질건 없다. layer가 추가됨에 따라 추가되는 weighted sum과 activation function 통과 과정에 대한 미분만 추가될 뿐이다.(노란 블록의 초록 네모 부분)
- 이때, k개에 대한 sigma는 마지막 layer의 node(output)가 스칼라가 아닌 벡터이기에, 이들을 sum해줘야 한다.
- w_jk의 경우, d(z_k)/d(z_j) 값이다.
- 초록 형광펜 부분의 y_hat(1-y_hat)은 중간 layer(hidden layer)에서 다음 layer로 넘어갈때 쓰인 activation function에 대한 미분이다.
결론적으로, DNN에서는 chain rule을 이용한 backpropagation 방법으로 Gradient를 사칙연산으로 간단히 계산할 수 있다. hidden layer가 늘어날 때마다 위 사진에서의 초록 네모 부분만 그만큼 추가되는 것이다.
-
참고로 위 사진들에서 n의 의미는 input data의 요소의 개수이며, 데이터가 많을 경우, batch size일 것이다. 그들에 대해서 다 더해줘야 Gradient가 나온다.
-
이를 통해 파라미터(w,b)를 업데이트 할 수 있다. 중간에 끼어있는 weight와 bias는 dC/d(w_jk)를 구하여 경사하강법을 하면 되며, 이는 backprogation을 해당 weight와 bias가 있는 층까지만 하면 되는 것이다.
