Deep Learning 07 Vanishing Gradient
Vanishing Gradient :
layer의 개수가 많을 수록 input과 가까운 weight, bias 들은 gradient 크기가 지속적으로 작아진다.
- 이유 : activaion function인 sigmoid 함수의 미분의 특성 :
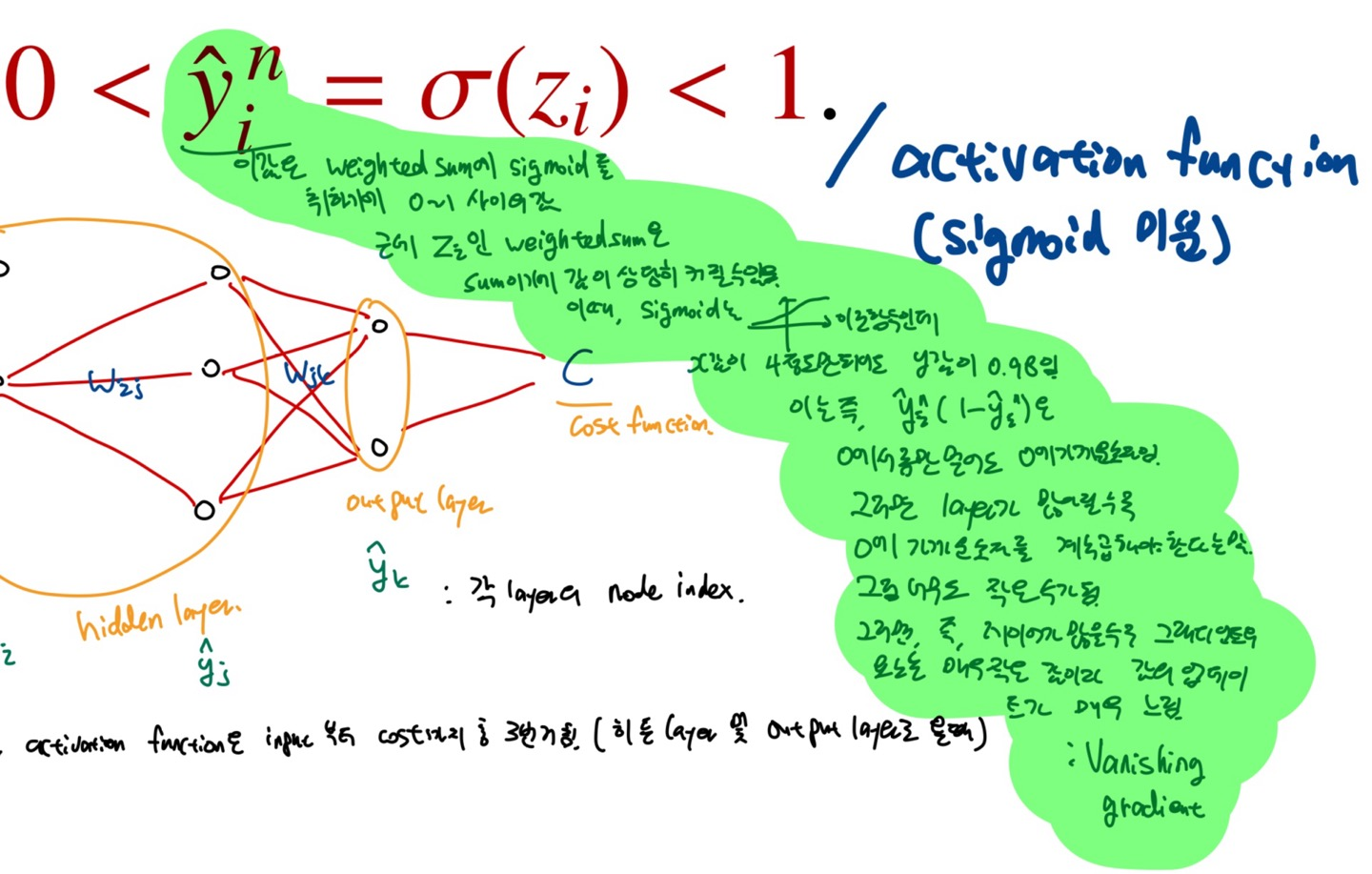
- 이는 파라미터의 학습을 느리게 하며, 특히 output에 가까운 파라미터들의 학습정도에 비해 input에 가까운 파라미터들의 학습정도가 지수적으로 늦음. 따라서 오래 여러번 학습해야함.
- Relu를 sigmoid function으로 쓰거나, ResNet(CNN 관련)처럼 Gradient 계산시 chain rule이랍시고 다 곱하지 않고, 중간중간 더하는 텀이 있게끔 하거나, 아니면 LSTM(RNN, timestep data 관련)처럼 극복할 수 있는 tool이 있으면 됨
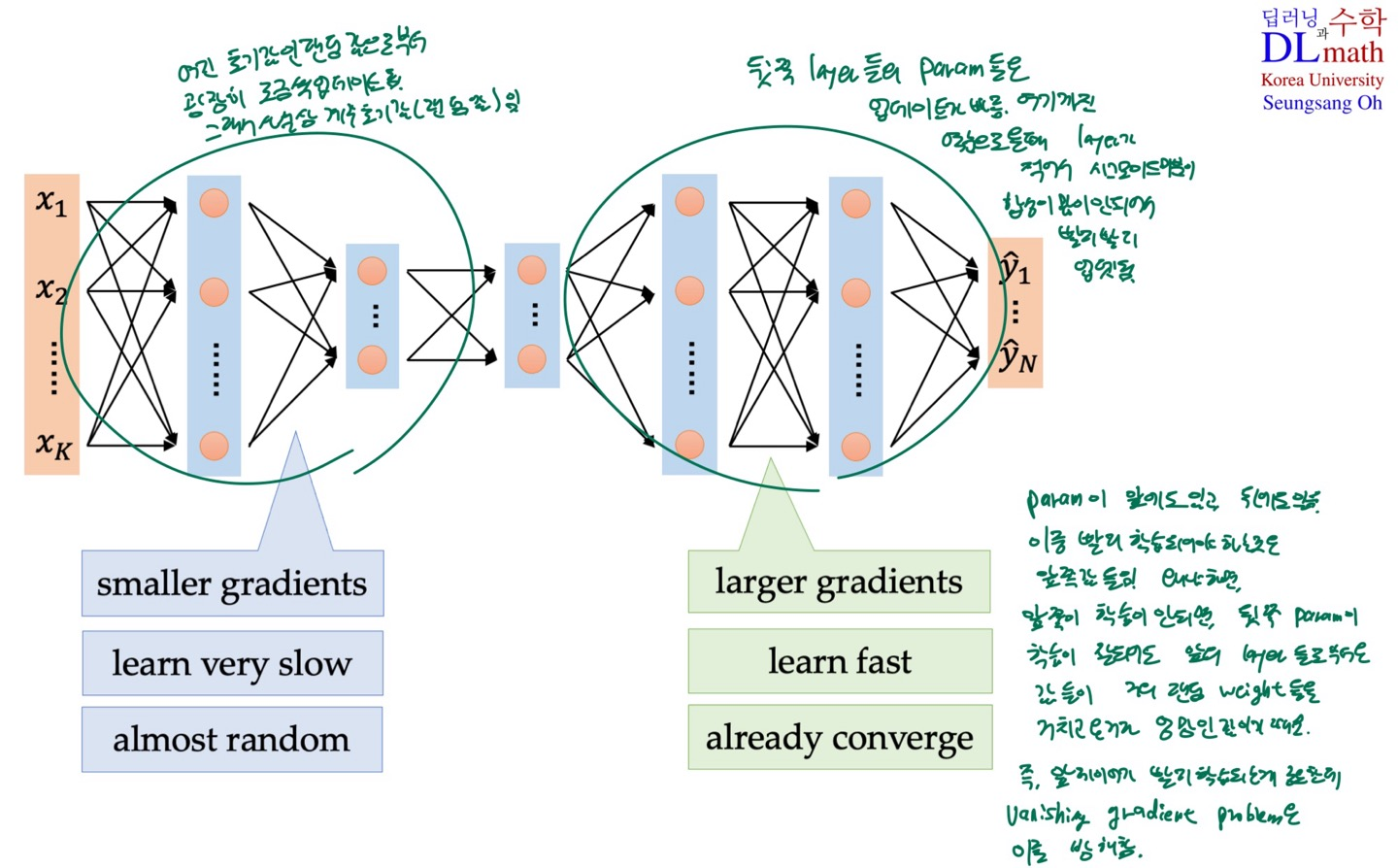
- Vanishing Gradient는 AI의 2차 빙하기를 가져옴. Relu의 사용으로 극복되었음.
DNN 학습과정
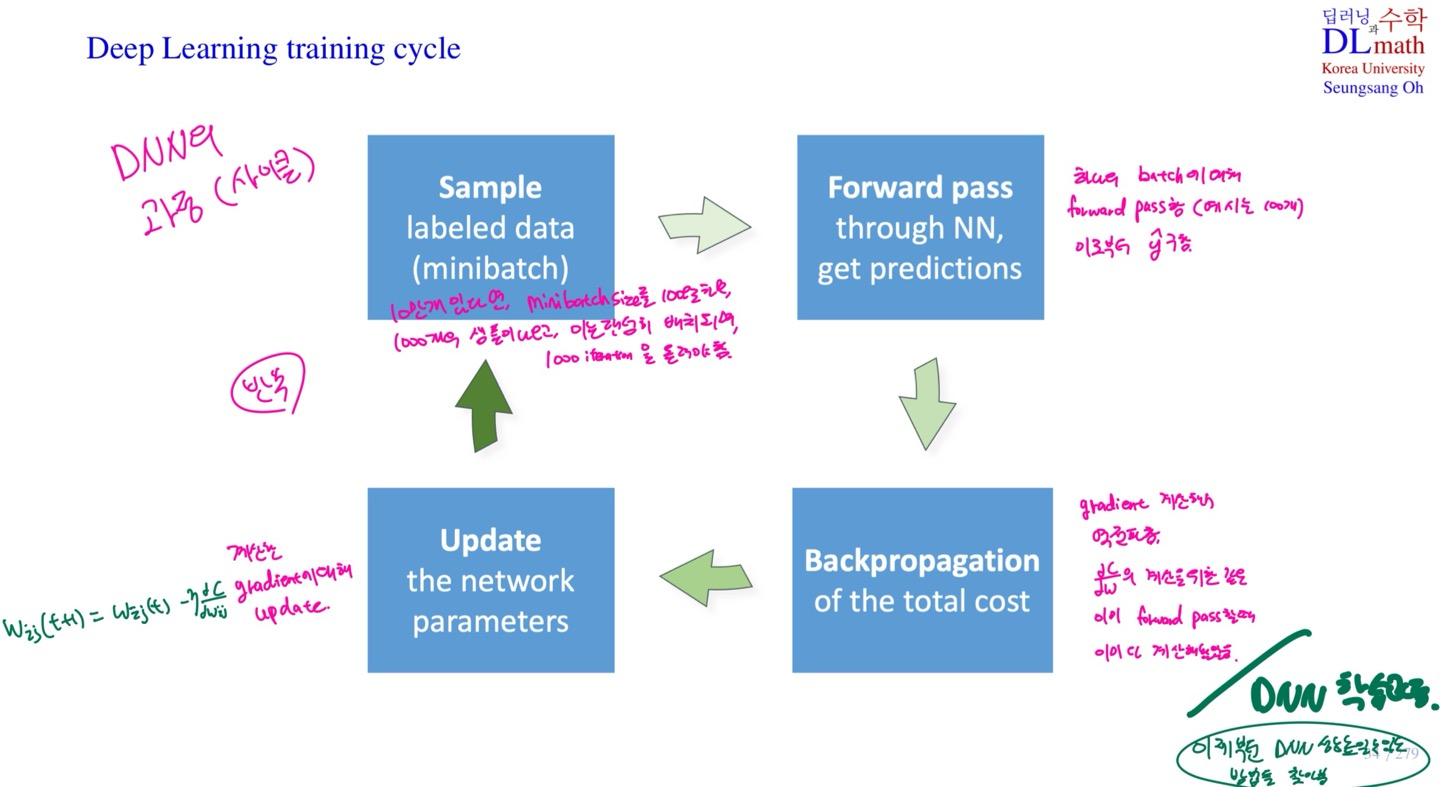
- DNN학습과정은 다음과 같이 Sample을 batch로 나누는 과정, forward pass과정, Backpropagation과정, Update과정으로 Cycle이 돌아감.
