
(Thumbnail Image made with ChatGPT)
From arXiv, 2025.04
3줄 요약
- 기존 LLM Agent Fine-Tuning 방법인 RFT는 간단한 작업만 잘한다.
- 어려운 작업을 해결하는 Agent Tuning 방법은 뭐가 있을까?
- 실패한 경로에서 ‘유용한 행동’을 식별해서 학습에 활용하면 성능 향상 → 우리가 제안하는 EEF
0. Abstract
- Rejection Sampling Fine-Tuning(RFT)은 LLM을 agent로 Fine tuning하는 효과적 방법으로 부상
- 전문가가 생성한 성공적인 trajectories를 모방하고,
- 성공적인 자가-생성 trajectories에 대한 반복적인 fine-tuning을 통해 agent 기술 향상
- GPT-4와 같은 전문가는 주로 더 간단한 작업에서 성공적, RFT는 본질적으로 간단한 시나리오 선호
- 복잡한 작업은 OOD(Out of Distribution), 해결되지 않음
- 실패한 전문가 경로에서 유익한 행동을 식별해 까다로운 작업에 대해 탐색 효율과 성능 향상에 도움을 줄 수 있음을 발견
- Exploring Expert Failures (EEF)
1. Introduction
- LLM을 에이전트로 활용할 때 주로 사용하는 RFT 방식은 간단하고 효과적이지만, 고난도 task에서는 여전히 해결되지 않는 부분이 많음
- RFT는 전문가가 생성한 성공적인 예시만을 사용해 모델을 학습하고, 더 단순한 task를 선호
- 복잡한 OOD task는 무시되고 해결되지 않음
- Exploring Expert Faliures (EEF) 제안
- 실패한 전문가 경로에도 적절한 계획, 탐색 전략 등의 유용한 행동이 포함되어 있으며, 이를 적극적으로 추출해 학습하는 접근
- WebShop에서 62% 승률 및 0.81 초과, SciWorld에서 81점 초과 달성하며 새로운 SOTA 달성
2. Background
- Text-based LLM Agent의 상호작용
- Markov Decision Process(MDP)로 모델링.
- RFT 기법
- 초기: GPT-4와 같은 전문가가 성공적인 경로 생성 후 positive 경로만 학습 데이터로 사용
- 반복: agent가 탐색 성공한 경로를 추가하여 재파인튜닝하는 과정 반복
- WebShop
- 실제 Amazon 상품 목록을 통해 온라인 쇼핑 행동을 시뮬레이션 하는 e-커머스 플랫폼
- Language understanding과 Multistep decision making을 연구하기 적합
3. Methodology
3.1 Motivation
- Webshop 실험에서 GPT-4조차 35%의 낮은 성공률
- 나머지 65%는 OOD 상태
- 실패한 경로에도 유용한 탐색 및 recovery 행동이 포함
- Ex) GPT-3가 failure 후 Back을 사용해 recover을 시도하는 등의 행동은 agent에게 학습 가치
3.2 Exploring Expert Failure (EEF)
3 main phases:
- Behavior Cloning: 전문가가 만든 긍정적(positive)한 경로를 모방해 기초 능력 학습
- Exploration: 모델이 스스로 혹은 전문가 상태로부터 탐색
- Fine-tuning: 유익한 행동만을 선별해 추가 학습
- Behavior Cloning (Algo 1. line 4)
- Input: 전문가 데이터셋
- 긍정적 경로 중 보상 1인 것만 사용
- 시퀀스 중 Action 부분만 마스킹하여 학습해 정책(πθ) 초기화
- Exploration (Algo 1. line 6-10)
- 정책(πθ)을 사용해 학습 데이터의 초기 상태 및 전문가 실패 경로 중 선택된 state에서 탐색
- 전문가 경로 τ_e에서 M개의 구간 선택해 시뮬레이션 → beneficial actions 추출
- Reinforcement Fine-Tuning (Algo 1. line 11-15)
- 시뮬레이션에서의 긍정적 경로 중, 중요한 state 기준으로 need recover state(복구 필요 상태)를 식별
- 해당 상태에 대해 가장 효과적인 경로를 선택하고 그 이후 행동만 학습
구체적 Algorithm :

- 전문가 데이터셋 D_e로부터 보상
R(τ_e) = 1인 경우만 초기 학습에 사용 - for :
- 모델을 환경에서 실행해 경로 수집
- 전문가 실패 경로에서 일정 간격으로 상태를 선택하고, 거기에서 정책을 실행해 성공 여부 확인
- 성공 경로는 D+에 저장
- 실패한 지점 기준으로 need recover state S_r 추출하고, 그 상태로부터 성공적인 경로가 있으면 학습에 사용
‘유익한 행동’의 정의와 선택 기준?
- 실험적 시뮬레이션 기반:
- 전문가 실패 trajectory (
τe)의 여러 상태(si)에서 현재 policy (πθ)로 시뮬레이션을 수행 - 만약 어떤 전문가 상태
sl에서 시작해서 성공하는 trajectory (τsl)를 만들 수 있다면,sl에 도달하기까지의 행동들(a0~al-1)은 유익한 행동으로 간주
- 전문가 실패 trajectory (
- 회복(recovery) 행동 식별:
- 이전 상태(
si−l)에서는 성공했지만, 다음 상태(si)에서는 실패하면,ai−l~ai−1구간의 행동은 잠재적 문제 행동으로 취급 - 이 실패한 상태
si에서 성공적인 trajectory가 생성되면, 이후 행동(ai이후)만을 학습 데이터로 사용
- 이전 상태(
- 데이터 편향 방지:
- 동일한 상태에 대한 multiple positive trajectories가 있을 경우, 가장 전문가 행동이 적은(shortest expert actions) trajectory를 선택해서 일반화 능력을 높임
- 이는 특정 도메인 행동으로 과적합(overfitting)되는 것을 방지하는 전략
- Loss Masking 적용:
- 선택된 beneficial actions 이후의 행동에만 학습 손실이 적용되며, 문제 행동이나 실패한 행동은 학습하지 않음
4. Experiments
4.1 Experimental Settings
- 데이터셋:
- WebShop 11k(전체), 3k(일부 샘플)
- ScienceWorld 2k (20단계 내외의 긴 trajectory 필요)
- 비교 대상:
- No Fine-Tune: GPT-3.5, GPT-4
- Fine-Tune Only: SFT-ALL, SFT-POS, NAT
- Exploration 기반: ETO, RFT, RFT×6
- 제안 방식: EEF GPT-4, EEF GPT-3&4
- 모델 세팅:
- Base Model: LLama3 8B Instruct
- 학습 파라미터: 6 epoch, lr=5e-5, batch size=64
- 반복 횟수 I=4, 시뮬레이션 횟수 M=5
4.2 Main Results
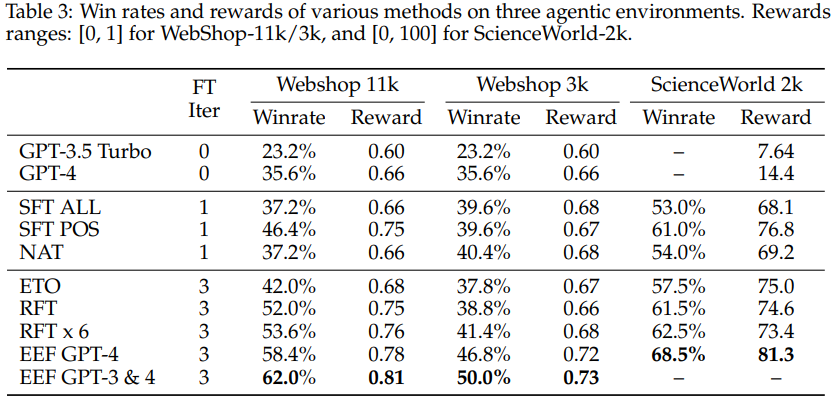
- Win Rate (Table 3):
- Webshop 11k: RFT×6 → 53.6% vs EEF GPT-4 → 58.4%, EEF GPT-3&4 → 62.0%
- Webshop 3k: RFT×6 → 41.4% vs EEF GPT-4 → 46.8%, EEF GPT-3&4 → 50.0%
- SciWorld: RFT×6 → 62.5% vs EEF GPT-4 → 68.5% (SOTA)
- 해석:
- EEF는 기존 RFT 기반 방식보다 휠씬 높은 성능
- 특히 GPT-3.5 Turbo 데이터를 추가하면, 비용 효율성을 유지하면서 성능이 더 향상
- EEF는 RFT의 구조는 유지하되, 실패 경로를 적극적으로 활용하는 것이 차별점
4.3 Ablation Studies
- Navigation Skill 개선
- Next / Back 사용 성공률 및 시도율 측정
- GPT-4는 시도율은 높으나 성공률 낮음 → 실행 역량 부족
- EEF는 시도율, 성공률 모두 높음 → 해당 스킬 습득 및 실용화 성공
- Case Studies
- 어려운 과제에서는 단순히 첫 페이지 상품을 선택하면 실패
- EEF는 Next, Back 등의 행동을 사용해 조건에 맞는 제품 탐색
- Ex) 원한 색상, 가격 조건을 갖춘 샴푸나 가구를 찾기 위해 여러 페이지 탐색
- Exploration Efficiency
- 적은 시뮬레이션(M=2)으로도 40% win rate
- GPT-3의 trajectory 탐색이 GPT-4보다 더 효과적인 경우도 있음 → 다양성, 편향 탈피 가능성
- Model Generalization
- mistral-7b-v0.3 모델에도 EEF 적용 시 동일한 성능 우수함 입증
5. Related Work
- LLM 기반 에이전트 학습 방식은 크게 3가지
- Fine-tune 없이 Prompt만 조정
- Exploration 없이 Fine-tune (SFT 등)
- Exploration 포함 Fine-tune (RFT, ETO, EEF 등)
- 대부분은 trajectory 전체를 하나의 보상으로 취급하지만, EEF는 stepwise 분석으로 유익한 행동만 학습
6. Conclusion and Future Work
- 결론:
- EEF는 실패한 전문가 trajectory 속 유익한 행동을 학습에 포함하여 RFT보다 성능 향상
- GPT-3.5 같은 약한 전문가의 trajectory에서도 유용한 정보 추출 가능
- SFT만 사용하기에 단순하고 효율적이며, reward 모델 불필요
- 미래 방향:
- 선택된 행동만을 사용한 preference learning
- Binary Search 기반 beneficial action 탐색
- MCTS 같은 트리 탐색 알고리즘과의 결합
- 전문가 소스 간 비용-효율 trade-off 전략 탐색

Anyone can be anything ... with agent!