From DeepSeek, 2025.01
(이 글은 논문을 바탕으로 재구성하여 쓴 글이므로 인덱스는 원 논문의 인덱스와 상이합니다.)

서론
DeepSeek-R1. 요즘 워낙 핫한 논문이라 연휴지만 안 읽어볼 수 없었다. o1급 성능을 구현하는데 모델 학습에 시간은 280만 H800 GPU hour 정도, 비용은 80억원 정도 밖에 들지 않았다고 한다.
이 논문이 발표되자마자 미국 기술주들(특히 매그니피센트 7)의 주가는 하락했다. 특히 GPU 물량빨로 학습을 이어나가는 추세에서 가성비있는 학습이 가능해짐이 보여지자 엔비디아는 17%가량 폭락했다(물론 다음날 상당 부분 회복했지만).
그렇다면 DeepSeek-R1은 어떻게 o1 수준의 성능을 적은 양의 학습으로 구현한 것일까?
바로 강화학습(Reinforcement Learning)을 통해 모델의 자율적인 추론 능력을 개발했다고 한다.
물론 기존 모델도 강화학습을 사용한다. 하지만 기존 모델들은 대규모 데이터 수집을 통한 지도학습(Supervised Fine-Tuning, SFT)으로 기본적인 능력을 학습한 이후에 강화학습을 적용했다. DeepSeek-R1은 순수 강화학습을 통해 모델 스스로 추론 능력을 발전시켰다고 한다.
논문에서 제시된 DeepSeek-R1의 핵심 특징 및 기여점은 다음과 같다.
- 지도학습(SFT)없이 강화학습(RL)만으로 추론 능력 발전
- 기존 모델들은 지도학습을 통해 먼저 기본적인 능력을 학습한 후 강화학습을 적용했지만, DeepSeek-R1-Zero는 base model(DeepSeek-V3-Base)에 곧바로 강화학습을 적용해 스스로 추론 능력을 발전시켰다.
- 강화학습을 통해 자율적으로 복잡한 추론 전략 학습
- DeepSeek-R1-Zero는 self-verification, reflection, long CoT generation 등 복잡한 추론을 자율적으로 습득했다
- Cold Start 데이터를 활용한 성능 향상
- DeepSeek-R1은 DeepSeek-R1-Zero의 초기 불안정성을 해결하고 성능을 높이기 위해 적은 양의 high quality cold start data를 활용했다.
- 소형모델 distilation을 통한 효율성 확보
- DeepSeek-R1의 추론 능력을 더 작은 모델로 distill해 효율성을 확보했다.
DeepSeek-R1 의 구조
- DeepSeek-R1은 DeepSeek-R1-Zero, DeepSeek-R1의 두 가지 모델로 구성된다.
DeepSeek-R1-Zero
-
이 모델은 지도 학습 없이 순수 강화학습 만으로 LLM의 추론 능력을 개발할 수 있음을 입증한 모델이다.
-
DeepSeek-V3-Base 모델을 기반으로 GRPO(Group Relative Policy Optimization) 알고리즘을 사용해 학습되었다.
-
기존 RL 알고리즘은 보통 정책(policy)과 비슷한 크기의 critic 모델을 사용하여 advantage를 계산
-
But, GRPO는 critic 모델을 사용하지 않고 그룹 내 sample의 상대적인 reward를 비교하는 방식으로 baseline 설정
-
GRPO 알고리즘
-
critic을 제거하고, 하나의 질문에 대해 여러 개의 답변을 생성한 후 그룹 내에서 상대적인 reward를 비교하여 advantage 추정
-
GRPO는 critic 모델 없이 group score에서 baseline을 추정해 학습 비용을 절감하는 방식이다.
-
아래 수식과 같이 GRPO는 policy model 𝜋를 최적화하여 목표를 최대화한다.
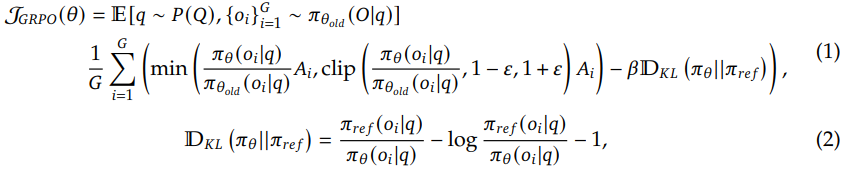
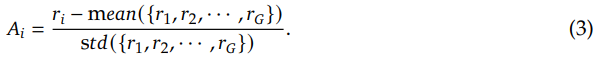
-
A는 어드밴티지, D_KL는 Kullback-Leibler 발산, β는 하이퍼파라미터이다.
-
-
Reward Model
- Accuracy reward와 Format reward의 두 가지 유형의 reward를 사용한다.
- Accuracy reward는 응답의 정답 여부를 평가하고, Format reward는 모델이 추론 과정을 및 태그 사이에 포함하도록 강제한다.
- 이 과정에서 Neural reward model은 reward hacking 문제와 추가적인 리소스 문제로 인해 사용하지 않았다.
-
Training Template
- 추론 과정과 최종 답변을 순서대로 생성하도록 요구하는 간단한 템플릿 사용

- 추론 과정과 최종 답변을 순서대로 생성하도록 요구하는 간단한 템플릿 사용
-
Performance
- DeepSeek-R1-Zero는 AIME 2024에서 초기 15.6%에서 71.0%로 크게 향상된 성능을 보였으며, majority vote를 통해 86.7%까지 향상시켜 OpenAI-o1-0912을 능가했다.
-
또한 모델 스스로 추론시간이 증가하면서 복잡한 문제를 해결하는 능력과 self-verification, reflection과 같은 advanced된 행동을 스스로 습득했다.
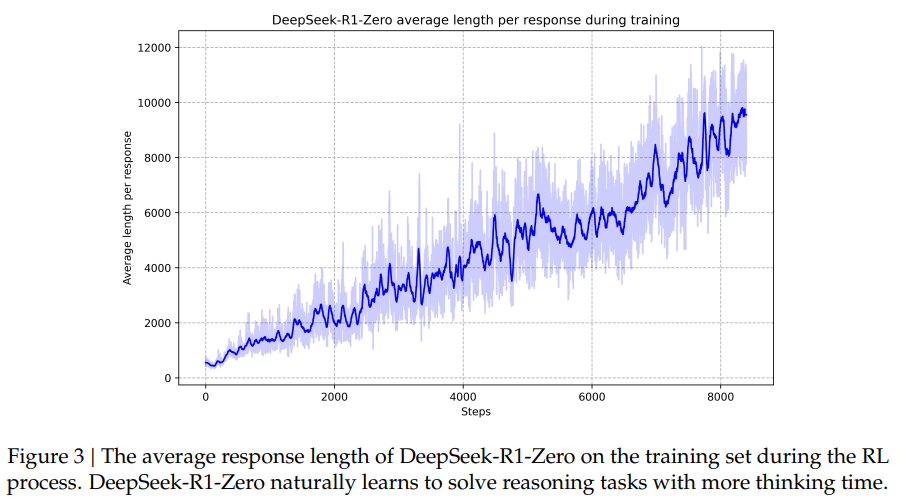
-
Aha-moment
- 학습을 진행하면서 모델이 스스로 "생각하는 시간"을 점점 늘리는 패턴을 보임.
- reasoning을 깊이 있게 수행하려는 경향이 자연스럽게 발생.
- DeepSeek-R1-Zero 학습 과정에서 모델이 중간에 ‘아하 모먼트’를 경험한다는 흥미로운 사실이 있었다고 한다.
- 이 순간이 발생하면, 모델은 문제에 대한 초기 접근 방식을 재평가하고, 더 많은 추론시간을 할당하는 방법을 학습한다.
- 예를 들어, 복잡한 수학 문제에서, 초기 풀이 과정이 막히자, 모델은 스스로 "Wait, wait. Wait. That’s an aha moment I can flag here.”와 같은 인간과 유사한 표현을 사용하며, 이전 단계를 재검토하는 모습을 보인다.

- 예를 들어, 복잡한 수학 문제에서, 초기 풀이 과정이 막히자, 모델은 스스로 "Wait, wait. Wait. That’s an aha moment I can flag here.”와 같은 인간과 유사한 표현을 사용하며, 이전 단계를 재검토하는 모습을 보인다.
- 이는 강화 학습이 명시적인 지시 없이도 모델 스스로 문제 해결 전략을 발전시킬 수 있다는 강력한 증거이다.
-
하지만, DeepSeek-R1-Zero는 가독성이 떨어지고, 여러 언어가 섞이는 등의 문제점이 있었다.
DeepSeek-R1
- DeepSeek-R1은 DeepSeek-R1-Zero의 개선된 버전이라고 할 수 있다.
- 요약하자면, Cold Start data로 사전학습된 base model을 초기 상태로 해서, (DeepSeek-R1-Zero와 동일한)대규모 강화학습을 적용한다. 강화학습이 수렴되면, 이 지점의 checkpoint에서 SFT 데이터를 수집한 뒤, 이 데이터를 기반으로 추가적인 강화학습을 진행한다. 이 강화학습에서는 모델의 helpfulness와 harmlessness를 향상시킨다.
- Cold Start
- Cold Start란 데이터 부족이나 초기 상태에서의 학습 부족으로 인해 낮은 성능을 보이거나 최적의 행동을 수행하기 어려운 문제를 보이는 것을 의미한다.
- DeepSeek-R1에서의 Cold Start 단계는 RL 초기 단계를 안정화하고 모델의 수렴 속도를 빠르게 하는 데에 목적이 있다.
- DeepSeek-R1-Zero는 V3-Base에 직접 RL을 적용해 모델 스스로 추론 능력을 발전시켰는데, 초기 학습 단계에서 불안정성이 크고 수렴 속도가 낮다는 문제점이 있었다.
- 따라서 DeepSeek-R1은 미리 준비된 고품질의 데이터(Cold Start data)로 모델을 초기화해 이런 문제점을 해결하고자 했다.
- Cold Start 데이터 수집 방법 (대망의…)
- 데이터는 크게 4가지 방법으로 수집되었다고 합니다. 근데 생성 방식만 다를뿐, 결국은 다 DeepSeek 계열 모델을 기반으로 생성한 거라고 하네요. (
절대 GPT는 사용하지 않았답니다!!)- DeepSeek-R1-Zero에서 생성된 데이터 활용
- 순수 RL 모델인 R1-Zero의 응답 일부 선택
- Readability가 낮거나 여러 언어가 혼합된 문제가 있는 sample은 필터링
- 즉, RL only인 R1-Zero에서 자연스럽게 학습된 CoT 패턴을 가져옴
- Few-Shot prompting을 통해 V3, V3-Base로 생성
- V3 또는 V3-Base를 활용해 long CoT 데이터 생성
- Few-shot으로 정제된 응답 유도
- 명확하고 논리적인 CoT 데이터 확보
- Human Annotator가 DeepSeek 모델 응답 Post-Process
- 1), 2) 로 생성된 데이터를 사람이 직접 검토
- 필요 시 수정하거나, 추가로 재구성해 가독성 향상
- 인간이 데이터를 새로 생성하지는 않으며, 모델의 응답을 개선하는 과정
- Post-processing을 통한 필터링 및 정제
- Markdown 형식 등으로 데이터 정리해 구조화
- 다국어 혼합 문제 제거
- 모델 생성 응답 중 논리적 일관성 부족한 부분 수정
- DeepSeek-R1-Zero에서 생성된 데이터 활용
- 데이터 수집 방법까지를 포함한 Cold-Start 데이터를 활용한 다단계(4단계) 학습 전략은 아래와 같이 정리할 수 있겠다
- Cold-Start 데이터 준비
- DeepSeek-V3-Base 모델을 수천 개의 long CoT 데이터를 활용해 fine-tune
- Readability를 높이기 위해 정형화된 Formatting
- Ex)
- |special_token| <reasoning_process> |special_token|
- 강화학습
- R1-Zero와 동일한 RL 기법을 적용해 reasoning 능력 강화
- Language Consistency Reward 추가
- CoT 내 언어 일관성 유지하도록 유도
- but 일부 성능 저하 부작용
- Rejection Sampling 및 SFT
- RL이 수렴한 이후, 새로운 SFT 데이터 수집
- R1의 checkpoint에서 600K 이상의 reasoning 데이터 생성
- non-reasoning data(번역, 요약 등) 200K 추가, 총 800K로 추가 학습
- RL for all scenarios
- 최종적으로 모든 유형의 입력에 대응할 수 있도록 광범위한 RL 적용
- Helpfulness(유용성?) 및 Harmlessness(안정성?) 향상 목표로 reward 모델 조정
- Cold-Start 데이터 준비
- 데이터는 크게 4가지 방법으로 수집되었다고 합니다. 근데 생성 방식만 다를뿐, 결국은 다 DeepSeek 계열 모델을 기반으로 생성한 거라고 하네요. (
Distillation (증류 모델)
- LLM은 말그대로 ‘Large’ Language Model이다. 성능이 강력하지만 그만큼 연산 비용이 높고 실시간 활용이 어렵다.
- Distillation은 이를 해결하기 위한 대표적인 방법이다. Diatillation은 무엇인가?
- 성능이 좋은 대형 모델(Teacher model이라 부른다)의 지식을 더 작은 모델(Student model)로 전이(transfer한다고 한다)하는 과정을 의미한다.
- 작은 모델을 별도로 fine-tuning하는 것이 아니라, 대형 teacher model이 학습했던 패턴과 추론 능력을 반영해서 학습한다는 것이 중요한 점이다.
- 이를 통해서 teacher model의 성능을 최대한 유지하면서도 연산량은 줄여서, 경량화된 모델을 제작할 수 있다는 것이 포인트이다.
- DeepSeek-R1도 그 추론 능력을 소형 모델로 transfer하기 위해 distillation 기법을 적용했다. 그리고 그 방식은 다음과 같다.
- DeepSeek-R1이 생성한 800K의 학습 데이터 활용
- 앞에서 설명한 Cold start 데이터와, RL로 학습된 R1의 지식으로 고퀄리티의 학습 데이터를 생성
- 이걸로 소형 오픈 소스 모델을 학습
- 오픈 소스 모델 기반으로 distillation
- LLM을 직접 만들지 않고 기존 오픈소스 모델 활용
- Qwen2.5-Math 시리즈 : 1.5B, 7B, 14B, 32B
- Llama : Llama-3.1-8B, Llama-3.3-70B-Instruct
- Llama-3.3이 3.1보다 조금 더 뛰어난 reasoning 능력이 갖고 있어서 3.3 썼다고 함
- LLM을 직접 만들지 않고 기존 오픈소스 모델 활용
- dilstilled된 모델에는 RL을 적용하지 않음
- R1에는 RL을 적용했지만, distilled 된 모델이는 SFT만 적용해 최적화
- distillation 목적 자체가 distill 만으로도 성능 향상됨을 입증하는 것이었고, RL 적용하느 것은 향후 연구 과제
- DeepSeek-R1이 생성한 800K의 학습 데이터 활용
DeepSeek-R1의 성능 (초간단)
- 논문에서 언급된 실험이나 성능 비교는 자세히 다루지 않겠다.
- 어짜피 o1과 비슷하거나 약간 높다고 하는 내용이 대부분이기 때문이다.
- 논문 첫 페이지에 있는 벤치마크 그래프만을 넣어 두겠다.
- 사용해본 사람이라면 알겠지만, 사실 o1이 수치로는 비교할 수 없는 무언가의 좋은 성능이 있긴 하다.
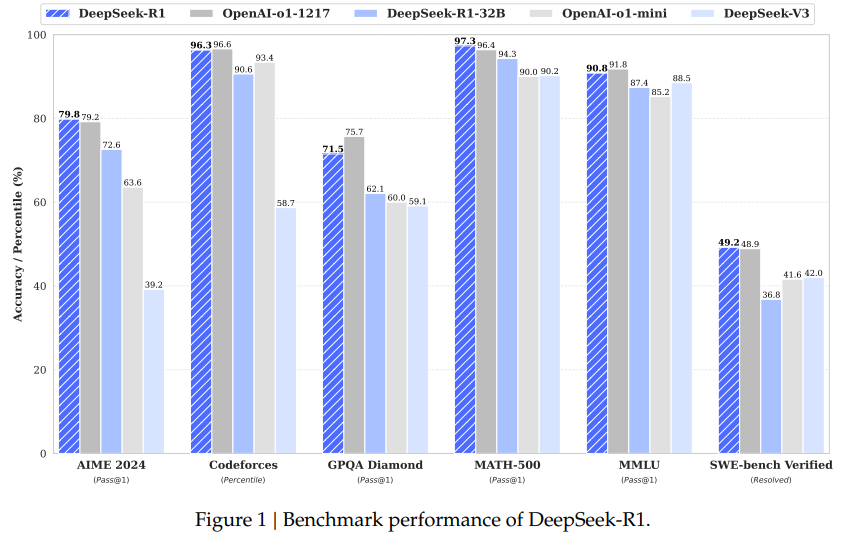
DeepSeek-R1이 시사하는 것
- SFT vs. RL
- DeepSeek-R1-Zero는 SFT 없이 순수 RL만으로도 LLM의 reasoning 능력을 향상시킬 수 있다는 것을 입증했다.
- 곧, SFT가 아닌 RL도 LLM의 자체적인 추론 능력 발달을 이끌어 낼 수 있다는 것이다.
- SFT를 통한 LLM 학습은 매우 많은 양의, 양질의 학습 데이터가 필요하기 때문에, synthetic data에 대한 연구도 한창 진행 중이고, 많은 데이터로 인한 GPU 사용량도 고려해야 하기에 MoE(Mixture of Expert) 연구도 진행되는 등 많은 곁다리? 연구 분야도 생겨나는 중이었다. 물론 DeepSeek도 MoE방식은 쓴 것 같다만..
- 그런데 RL만으로 가성비 있는 방식을 통해 거의 유사한 성능을 냈다면 AI업계에나, 엔비디아에게나 일시적으로는 분명히 충격이 있긴 하다.
- DeepSeek-R1-Zero는 SFT 없이 순수 RL만으로도 LLM의 reasoning 능력을 향상시킬 수 있다는 것을 입증했다.
- 추론 모델의 미래는?
- 이 논문에서 DeepSeek가 주장하는 것과 구현한 것이 100% 사실이라면, 개인적으로는 OpenAI, Google, Anthropic 등과 같은 프론티어 ai 모델 개발 기업을 제외하면 AGI급 모델을 개발하려고 하지는 않을 것 같다. DeepSeek 정도의 가성비있는 방법론으로도 거의 유사한 성능을 낼 수 있다면, 왜 그 많은 돈을 들여서 SOTA급 모델을 개발하려 할까? 적절한 비용으로 적절한 성능의 모델을 개발하는 것이 더 비용 효율적일 것이다.
- 또한, 프론티어 기업들이 이미 저런 방법론들을 사용하고 있지 않으리란 보장이 절대 없다고 보인다.
- 이 논문에서 DeepSeek가 주장하는 것과 구현한 것이 100% 사실이라면, 개인적으로는 OpenAI, Google, Anthropic 등과 같은 프론티어 ai 모델 개발 기업을 제외하면 AGI급 모델을 개발하려고 하지는 않을 것 같다. DeepSeek 정도의 가성비있는 방법론으로도 거의 유사한 성능을 낼 수 있다면, 왜 그 많은 돈을 들여서 SOTA급 모델을 개발하려 할까? 적절한 비용으로 적절한 성능의 모델을 개발하는 것이 더 비용 효율적일 것이다.
- 엉뚱한 소리일 수 있지만, 엔비디아는 한동안은 결국 더 웃게 될 거 같다. 이러한 저렴한 모델 학습 방법론이 유행처럼 번져나가면, (딥러닝에 있어서의) 엔트리급 GPU의 수요는 더 늘어날 것으로 보이고, 기업들 사이에서 GPU를 확보하기 위한 경쟁은 더 치열해질 것 같다.
