[논문 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (SBERT)(2019)
Paper Review
목록 보기
3/15
[논문 링크]
From EMNLP 2019
0. Abstract
- BERT(2018)와 RoBERTa(2019)는 semantic textual similarity(STS)와 같은 sentence-pair regression 작업들에서 SOTA 달성
- 그러나 몇몇 문제 존재:
- 문장의 쌍을 하나의 네트워크에 넣어야 하므로 막대한 연산 오버헤드 발생
- 10,000개 문장 모음에서 가장 유사한 문장 쌍 찾으려면 약 5,000만 번의 추론 연산 필요 → V100 기준 약 65시간
- BERT는 clustering 같은 비지도 학습뿐만 아니라 의미적인 유사도 검색에도 부적합하다는 것 의미
- 본 연구에서는 코사인 유사도를 사용해 문장 임베딩을 생성하기 위해 샴(Siamese) 네트워크과 Triplet 네트워크를 사용하는 BERT의 수정 버전인 Sentence-BERT(SBERT)를 제안
- 이를 통해 가장 유사한 문장 쌍을 찾는데 걸리는 시간이 65시간에서 약 5초로 단축되지만 BERT의 정확도는 유지
- 일반적인 STS 과제에서 SBERT와 SRoBERTa를 평가한 결과, 다른 최신의 문장 임베딩 방법보다 우수한 성능
1. Introduction
- SBERT는 샴 네트워크와 triplet 네트워크를 사용하여 BERT를 수정하였다. 이를 통해 기존 BERT로는 수행하기 어려웠던 다운스트림 task인 대규모 의미 유사성 비교, 클러스터링, 정보 검색 등을 수행할 수 있다.
- BERT는 cross-encoder 방식
- 한 네트워크에 한 쌍이 들어가 두 문장을 [SEP]로 나눠 연산 수행하므로 STS를 수행하려면 너무 많은 가짓수를 학습시켜야 함
- n개 문장을 pair로 학습시키려면 n(n-1)/2 → n=10,000이라면? 49,995,000 번 연산. V100으로 65시간…
- 위 방법처럼 하지 않고 각 단일 문장을 벡터 공간으로 매핑하고 유사도나 거리를 구하는 방법을 사용하기도 함
- 이런 방법은 과거에 제안된 GloVe 방법보다 낮은 성능이 나오기도 함
- 이런 BERT의 특정 task에서의 성능 저하점을 개선하고자 SBERT 제안
2. Related Work
- BERT는 pre-trained transformer 네트워크로, STS 벤치마크에서 SOTA를 달성했다
- 문장 쌍에 대한 입력은 [SEP]로 구분된 두 문장으로 구성
- RoBERTa는 pre-train 과정을 조정하면 성능을 향상시킬 수 있음을 보여줌. XLNet은 BERT보다 나쁜 성능
- 그러나 BERT는 독립적인 단일 문장의 임베딩의 계산을 할 수 없음
- 그래서 문장을 통과시키고 결과의 평균을 구하는 등의 우회 방법 사용
- 문장 임베딩 모델에 대해 그동안 연구된 모델 여러가지 소개
- 오버헤드 크고, 오래걸리는 등 사용하기 힘들다고 함.
- SBERT는 20분 이내에 tuning 가능하고 비슷한 문장 임베딩 방법보다 더 나은 결과를 얻을 수 있다
3. Model
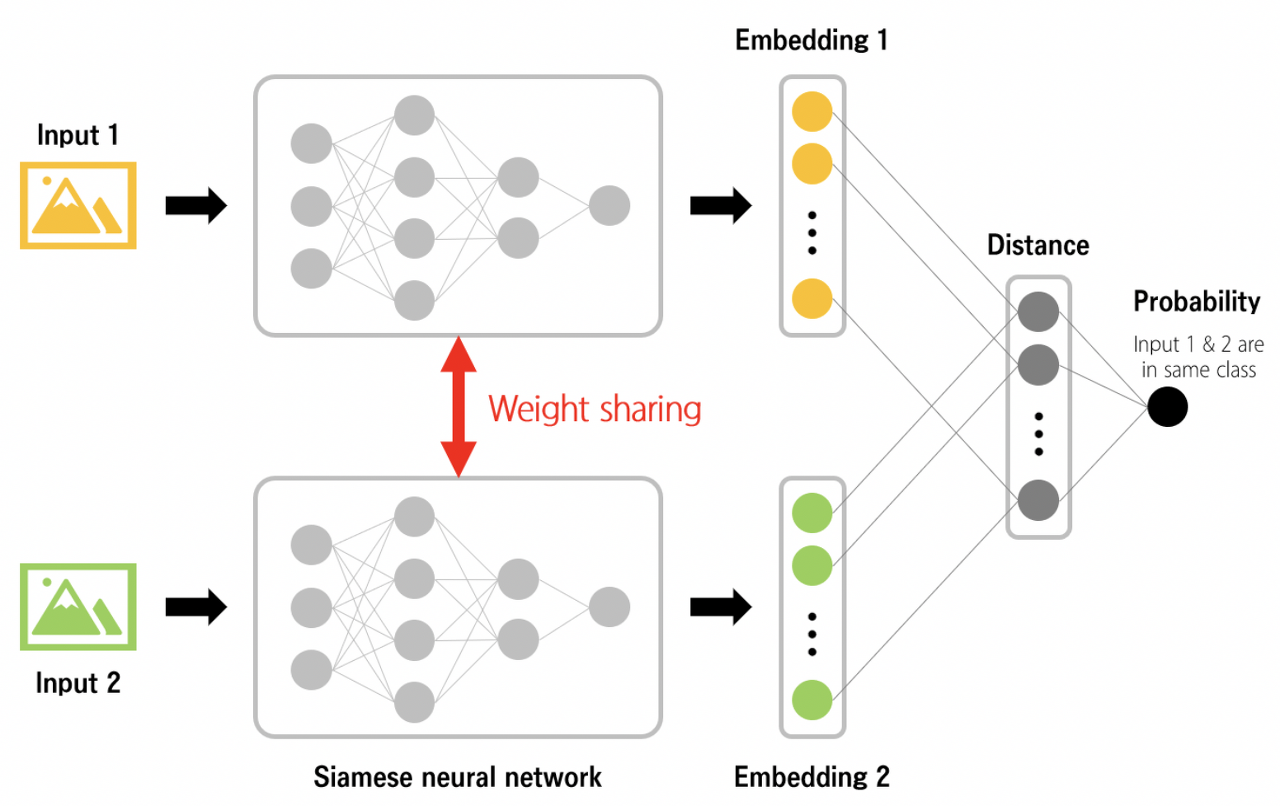
SBERT에서는 레이어의 형태도 같고 가중치도 같은 sub-network를 두 개 이상 갖는 샴(siamese) 네트워크를 사용한다. 입력으로 두 개의 데이터가 들어오면 동일한 가중치를 공유하는 레이어를 각각 통과해 각 임베딩 벡터를 생성해 이 벡터 간 거리를 비교하는 방식으로 학습이 진행된다. 샴 네트워크 사용하는 SBERT는 BERT와 달리 sub network의 가중치가 동일하게 업데이트 되므로 빠르게 두 개 입력을 비교할 수 있다.
- 내부 pooling에는 BERT 출력의 [CLS], MAX 풀링, MEAN 풀링 3개를 사용할 수 있는데, 대부분의 경우에서 Mean 풀링이 성능이 가장 우수하게 나와 Mean 풀링을 사용한다
SBERT 아키텍처 구조는 학습 데이터에 따라 크게 3가지로 나뉜다:
- Classification Objective Function
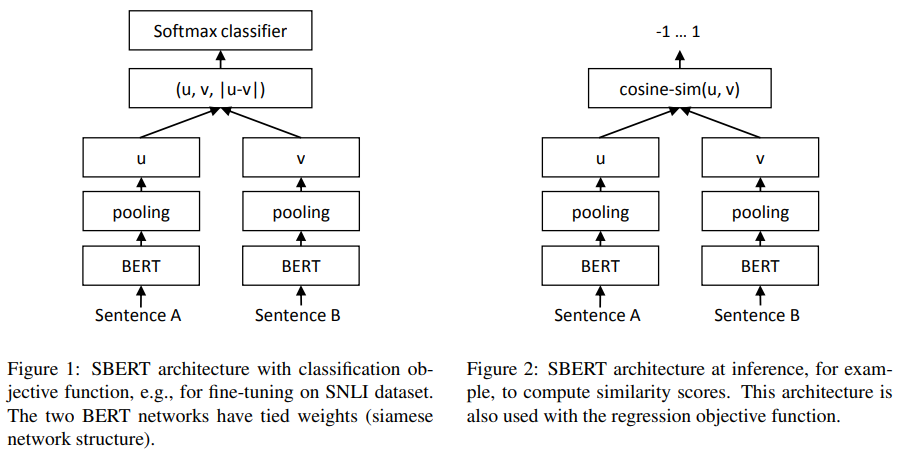
- Figure 1: For Classification
- 문장 임베딩 u, v와 그 둘의 element wise 차이를 concatenate 한 뒤 가중치를 곱한다. 이후 교차 엔트로피 오차(cross-entropy error loss)를 계산
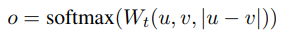
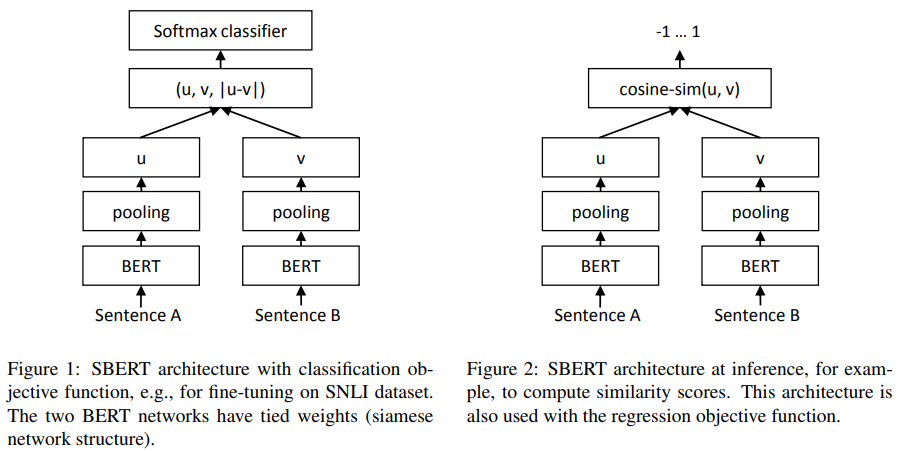
- Regression Objective Function
- Figure 2 : For Regression
- 문장 임베딩 u, v 사이의 코사인 유사도를 계산한 뒤 평균 제곱 오차(mean-squared-error loss)를 계산하여 목적 함수로 사용
- Triplet Objective Function
- 중심 문장 a(anchor), 일치 문장 p(positive), 불일치 문장 n(negative)
- a와 p는 가까워지게 하고, a와 n은 멀게 학습시키는 목적 함수
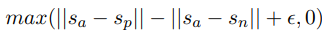
- 논문에서는 ϵ=1 사용
3.1 Training Details
- Train data
- SNLI - classification
- 570,000 sentence pairs
- labels: contradiction, entailment, neutral
- MNLI(MultiNLI) - regression
- 430,000 sentence pairs
- spoken and written text
- SNLI - classification
- batch size = 16
- optimizer = Adam
- learning rate = 2e-5
- a linear learning rate warm-up over 10% of the training data
- pooling strategy = MEAN
4. Evaluation - Semantic Textual Similarity
- 최신 모델에서는 종종 문장 pair 임베딩을 유사도에 매핑하도록 학습하는 경우가 있는데 이건 연산 횟수가 폭등한다.
- 대신 우리는 코사인 유사도로 구했다. 유클리드나 맨해튼도 해봤지만 비슷했다.
4.1 Unsupervised STS
- STS에 대한 모델의 비지도 학습을 측정하지만 관련된 데이터셋으로 모델을 학습시키지는 않고 측정했다.
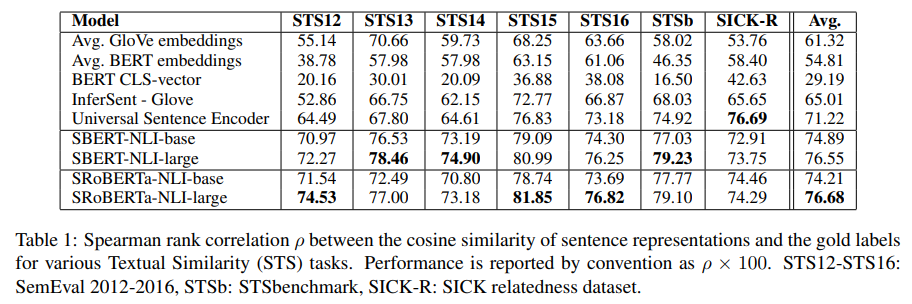
- SBERT, SRoBERTa가 비지도학습에서도 높은 성능을 보임
- Universal Sentence Encoder가 SICK-R에서 더 높긴하지만 Universal은 뉴스 데이터를 더 많이 학습해서 그렇다고 함
- BERT의 [CLS]와 Glove는 성능이 떨어짐
4.2 Supervised STS
- STS 데이터셋으로 학습을 진행하고 성능 비교한 결과이다. 학습은 앞선 세가지 구조 중 regression으로 진행했다.
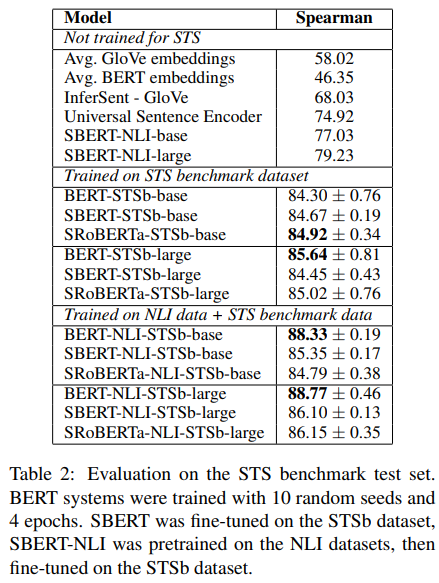
- 표 세번째 섹션에 나온 것과 같이 NLI에 대해 학습하고 STS에 대해 다시 학습하니까 성능 향상 폭이 매우 컸다
- 사실 이 부분은 SBERT나 SRoBERTa보다 BERT를 사용한게 더 성능이 우수한데 논문에선 언급이 없음 → 근데 계산의 속도 차이가 워낙 커서 이 정도 성능 차이를 충분히 감수할 만 하지 않을까 생각
4.3 Argument Facet Similarity
- AFS는 논쟁이 될만한 3가지 주제를 다루는 데이터셋(총기 규제, 동성 결혼, 사형)
- 기존 STS와 다르게 동일한 주장과 동일한 이유를 다루고 있는지도 라벨링의 기준이 됨 → AFS가 더 성능 올리기 어려움
- 1) 10-fold cross validation, 2) 세가지 주제 중 두 주제를 학습에 사용하고, 나머지 한 주제를 평가에 사용하는 방식
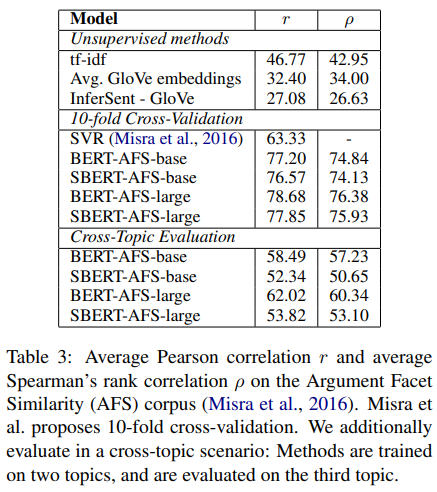
- SBERT는 기존 BERT와 근접한 성능을 보이고 있음
4.4 Wikipedia Sections Distinction
- Wikipedia 문서 내에서 한 문서안이라도 같은 섹션에 있는 문장이면 다른 섹션에 있는 문장보다 더 가까울 것이라 가정하고 만든 데이터셋
- Triplet으로 학습하므로 Anchor(기존 문장), Positive(같은 섹션 문장), Negative(다른 섹션 문장)으로 구성되어 있음
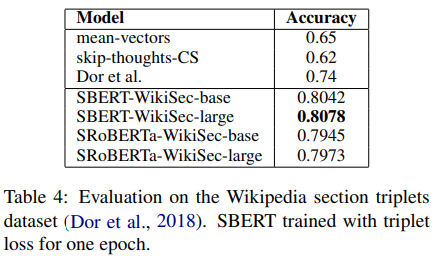
- Accuracy는 Anchor가 어떤 문장에 더 가까운지 구별하는 척도
5. Evaluation - SentEval
- 7개의 classification task를 갖는 SenEval에 대해 성능을 추가로 측정
- MR, CR, SUBJ, MPQA, SST, TREC, MRPC
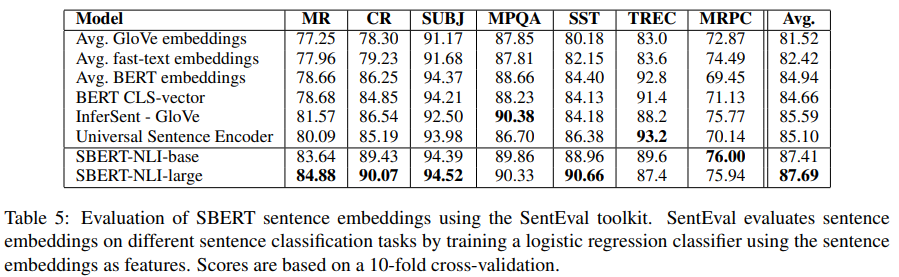
- 7개 중 5개에서 SOTA에 버금가는 성능
- transfer learning이 SBERT의 목적이 아님에도 불구하고 SBERT의 문장 임베딩 성능이 그만큼 뛰어나다는 것을 알 수 있다
6. Ablation Study
- Pooling에서 Max, Mean, BERT의 [CLS] 중 왜 Mean을 썼는가?
- 목적함수 식은 왜 지금같이 이루어 지는가?
- 등에 대한 설명
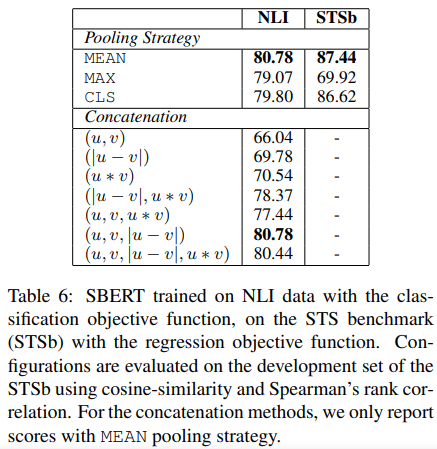
- 성능 평가 해보니 지금 같이 하는게 제일 좋았다.
- 특히 풀링에서 Mean 쓰는 것은 BiLSTM의 풀링에서는 Max를 쓰는게 유리한 것과는 대조적이다
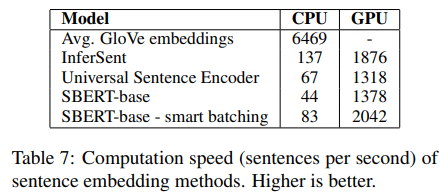
7. Computational Efficiency
- 문장 간의 유사도 계산은 많은 연산이 필요하다
- SBERT는 이를 많이 단축시켰다
- 근데 GPU로 병렬처리해서 연산하면 더 빠르다
8. Conclusion
- 기존 BERT를 사용한 문장의 임베딩 성능은 너무 낮았다.
- 그래서 우리는 샴 네트워크과 triplet 네트워크를 사용한 SBERT를 제안했다.
- 이 모델은 문장 임베딩 성능 개선을 보였고 연산 시간을 단축했음을 보였다.

Anyone can be anything ... with agent!