[논문 리뷰] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2020)
Paper Review
목록 보기
4/15

From ACL 2020
0. Abstract
- Seq-Seq 모델을 pre-train하기 위한 denoising autoencoder인 BART를 제안한다.
- BART는 다음의 방식으로 학습이 이루어지는데, 이는:
- 임의의 노이즈 함수로 텍스트에 변형을 주고,
- 이 노이즈를 원본으로 복원하는 방식이다.
- BART는 양방향의 BERT, 단방향의 GPT 등 수많은 표준 Transformer 기반 NMT(Neural Machine Translation) 구조를 일반화한 모델이다.
- 여러가지 노이즈 기법을 평가했더니, (1) 원본 문장들의 순서를 랜덤하게 섞는 것과, (2) 텍스트 시퀀스(이하 span)가 하나의 MASK 토큰으로 치환되는 새로운 in-filling scheme을 사용하는 것을 모두 사용할 때 가장 좋은 퍼포먼스를 보인다는 것을 발견했다.
- 참고)
- Span: 텍스트의 나열(시퀀스). 문장을 이룰 수도 있지만 꼭 그렇지 않음. 여러 문장에 걸쳐 형성될 수도 있음.
- 참고)
- BART는 Text Generation에 대해 Fine-tuned 됐을 때 효과적이지만 이해력이 요구되는 작업에도 잘 동작한다.
- GLUE, SQuAD 벤치마크에 대해서 RoBERTa 모델과 유사한 학습 환경에서 Abstractive Dialogue, Question Answering, Summarization에서 SOTA 달성 (6 ROUGE 이상 상승)
- 기계 번역을 위한 역번역(Back-translation)에서 Target language에 대한 사전학습만으로도 1.1의 BLEU 상승이 있었다.
- 참고)
- Back-translation: 번역 데이터가 충분하지 않을 경우 유용한 방식
- 1) 원본 언어에서 Target 언어로 번역
- 2) Target 언어에서 원본 언어로 재번역 → Back-translation
- 원본 텍스트와 재번역된 텍스트의 차이를 줄이는데 유용
- Back-translation: 번역 데이터가 충분하지 않을 경우 유용한 방식
- 참고)
- 또한 본 논문에서는 ablation 실험을 통해 BART에서 성능에 가장 큰 영향을 미치는 요인을 측정한다.
- 참고)
- Ablation study/experiment
- 모델에서 특정 요소들을 제거하고 실험을 진행하면서 그 요소가 성능에 어떤 영향을 주는지 확인해보는 것
- Ablation study/experiment
- 참고)
1. Introduction
- Self-supervised 방식은 NLP에서 많은 성공을 거두었다.
- 그러한 성공은 Masked Language Model의 변형들이었으며, 랜덤으로 마스킹된 텍스트를 재구성하도록 훈련된 Denoising Autoencoder들이었다.
- 최근에는 마스킹된 토큰의 분포 개선, 마스킹된 토큰의 예측 순서 개선 등을 통해 성능 향상 이루었다.
- 하지만 이러한 방법들은 End tasks(ex. span prediction, generation …)에 초점을 맞추기 때문에 활용 가능성이 제한적이다.
- 본 논문에서는 양방향과 auto-regressive한 transformer를 결합한 사전학습 모델인 BART를 제안한다.
- BART는 sequence to sequence 모델로 제작된 Denoising autoencoder로, 다양한 End task에 적용가능하다.
- BART의 사전학습은 두단계로 이루어진다:
- 임의의 노이즈 함수로 텍스트에 변형을 가하고,
- seq-to-seq 모델이 텍스트의 원본을 복원하도록 학습된다.
- BART는 표준 Transformer 기반 NMT(신경망 기계 번역) 구조를 사용하는데, 이는 단순함에도 불구하고 양방향 인코더를 사용하는 BERT, Left to Right 단방향 디코더를 사용하는 GPT 등의 최신 사전학습 방식을 일반화한 것이라고 볼 수 있다.
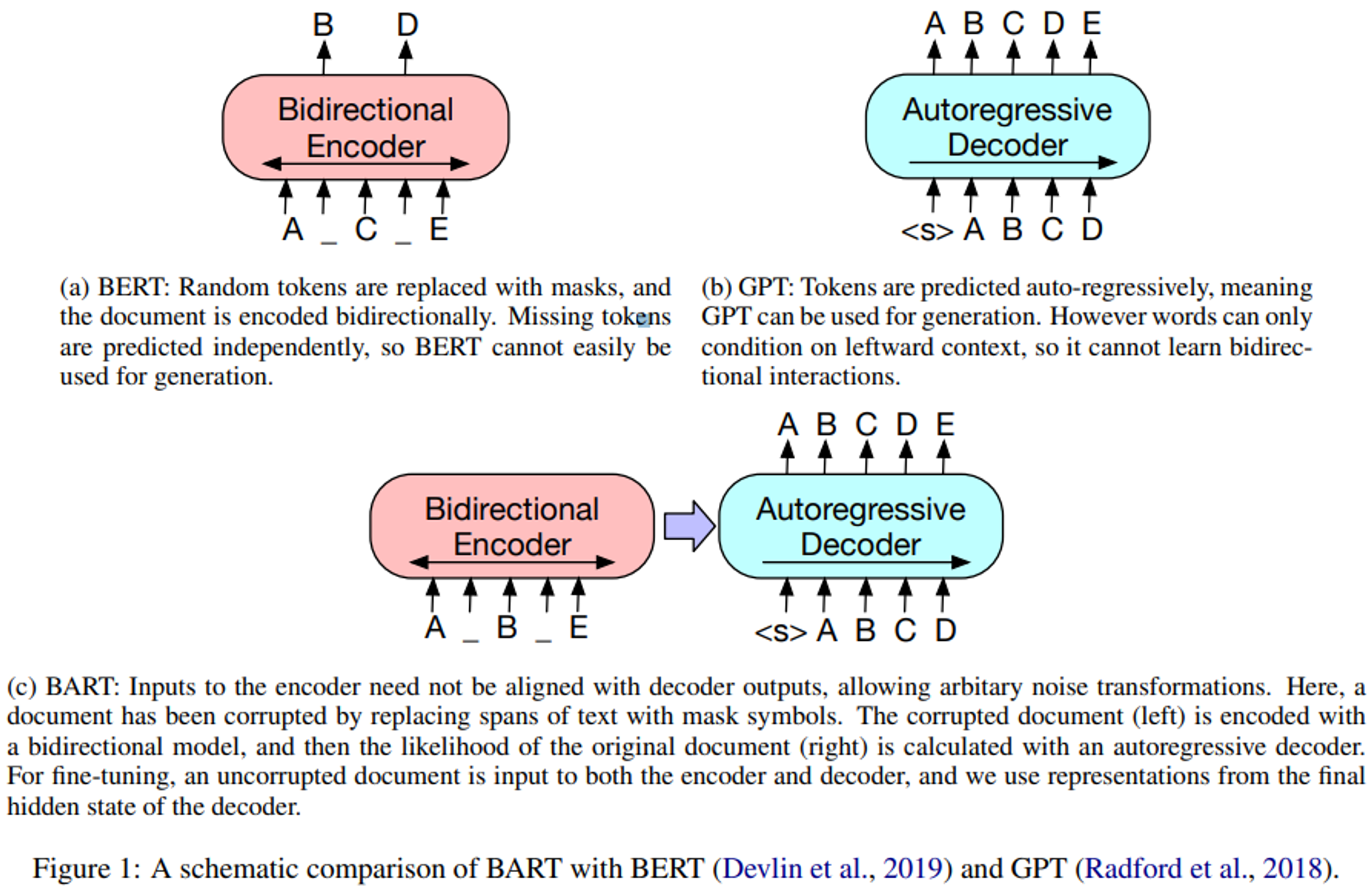
- 이러한 방식의 이점은 Noising의 유연성으로, 원본 텍스트에 길이 변경을 포함하는 임의의 변형을 가할 수 있다는 것이다.
- 여러가지 노이즈 기법을 평가했더니, (1) 원본 문장들의 순서를 랜덤으로 섞는 것과, (2) 임의 길이(0도 포함)의 span이 하나의 MASK 토큰으로 치환되는 새로운 in-filling 방식을 사용하는 것을 모두 사용할 때 가장 좋은 성능을 보인다는 것을 발견했다.
- 이는 문장 전체 길이에 대해 더 많이 추론하고, 입력보다 더 긴 변환을 수행하도록 강제함으로써, 기존 BERT의 masking과 NSP를 일반화한다.
- 또한, BART는 fine-tuning에 대한 새로운 사고 방식을 생각하게 한다.
- 본 논문에서는 machine translation에 대한 새로운 scheme을 제안하는데, 이는 추가적인 transformer layer들 위에 BART를 올리는 것이다.
- 이 layer들은 BART의 순전파를 통해 외국어를 노이즈가 있는 영어로 번역하도록 학습된다. (BART를 target쪽 언어모델로 사용)
- 이는 WMT 루마니아어-영어 벤치마크에서 강력한 역번역 MT 기준에 대한 성능을 1.1 BLUE만큼 향상시킨다.
- Ablation 실험을 통해 BART에서 사용된 기법들의 효과를 이해한다.
- BART는 우리가 고려하는 모든 task에서 일관되고 강력한 성능을 보인다.
2. Model
- BART는 변형된 문서를 원본으로 매핑하는 denoising autoencoder다.
- 이는 변형된 텍스트에 대해 양방향 인코더와 left-to-right autoregressive 디코더로 구성된 sequence-to-sequence 모델로 구현된다.
- 사전학습 과정에서는 원본 문서의 negative log likelihood (NLL)을 최적화한다.
- 참고)
- NLL: 일종의 손실함수로, Cross Entropy와 유사
- 모델이 정답 단어를 예측할 확률의 로그를 취한 것을 음수로 취한 것
- ex) NLL: 단일 클래스 예측, Cross Entropy: 다중 클래스 예측
- 참고)
2.1 Architecture
- BART는 표준 seq-to-seq Transformer 아키텍처를 사용하지만, GPT와 같이 ReLU가 아닌 GeLU 활성화 함수를 사용하고, 파라미터를 N(0, 0.02)로 초기화하여 사용한다.
- Base 모델에는 인코더와 디코더에 각각 6개의 레이어를 사용하며, large 모델에는 12개의 레이어를 각각 사용한다.
- 이 구조는 BERT와 밀접한 관련이 있지만 다음과 같은 차이점들이 있다:
- (1) 디코더의 각 레이어는 (transformer seq-to-seq 모델과 같이) 최종 hidden layer에 대해 추가로 cross-attention을 수행한다.
- (2) BERT는 word-prediction 이전에 추가적인 FFN을 사용하지만, BART는 그렇지 않다.
- 전체적으로, BART는 같은 크기의 BERT보다 10% 더 많은 파라미터를 갖는다.
2.2 Pre-training BART
- BART는 문서를 변형시킨 뒤 reconstruction loss, 즉 디코더의 출력과 원본 문서 간의 cross entropy를 최적화하며 학습된다.
- 특정 noising 방식에 맞추어진 기존의 denoising audoencoder들과는 달리, BART는 모든 종류의 문서 변형에도 대응할 수 있다.
- Extreme한 케이스, 즉 원본의 모든 정보가 날라간 경우라면, BART는 전통적인 언어모델과 동일하게 작동한다. (개인적인 생각: BART는 원래 denoising ‘오토인코더’처럼 동작하는데, 정보가 다 사라졌을 때에는 언어모델링, 즉 텍스트를 생성하는 작업도 수행할 수 있다는 뜻?)
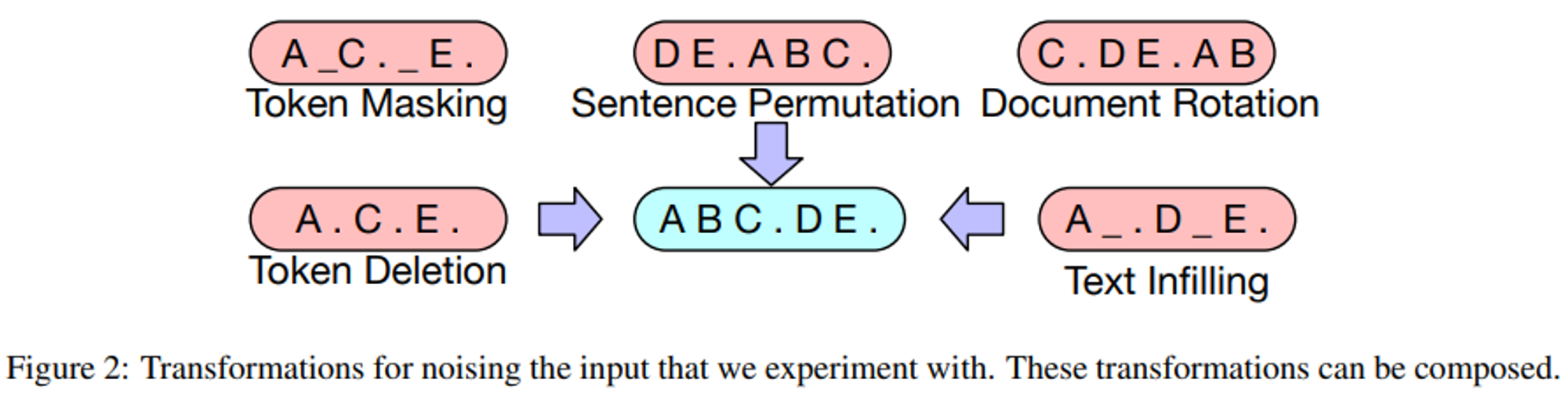
- BART에서 사용한 텍스트 변형 방법은 아래과 같다:
1) Token Masking
- BERT처럼 무작위 토큰이 샘플링되고 [MASK]로 치환된다.
2) Token Deletion
- 무작위 토큰이 입력에서 제거된다.
- Token Masking과 다르게, 모델이 반드시 어떤 위치의 입력이 제거될지 정해야 한다.
3) Text Infilling
- 여러개의 span이 샘플링되며, span 길이는 푸아송 분포(λ = 3)에서 추출된다.
- 각 span은 하나의 [MASK] 토큰으로 치환된다.
- 이는 SpanBERT에서 그 아이디어를 가져왔지만, 이와 다른 점은 SpanBERT는 서로 다른 분포에서 span이 샘플링되고, 이를 span과 동일한 길이의 [MASK] 토큰으로 치환한다는 것.
- Text Infilling은 span에서 누락된 토큰의 수를 예측하도록 모델을 학습한다.
4) Sentence Permutation
- 마침표를 기준으로 문장이 나뉘고, 이러한 문장들이 랜덤한 순서로 섞여있다.
5) Document Rotation
- 토큰이 무작위로 선택되고, 그 토큰을 기준으로 문서가 회전되어 문서가 해당 토큰으로 시작할 수 있도록 한다.
- 이는 모델이 문서의 시작 부분을 찾아낼 수 있도록 훈련시키는 것이다.
3. Fine-tuning BART
- BART의 representation은 다양한 방식의 다운스트림에서 사용가능하다.
3.1 Sequence Classification Tasks
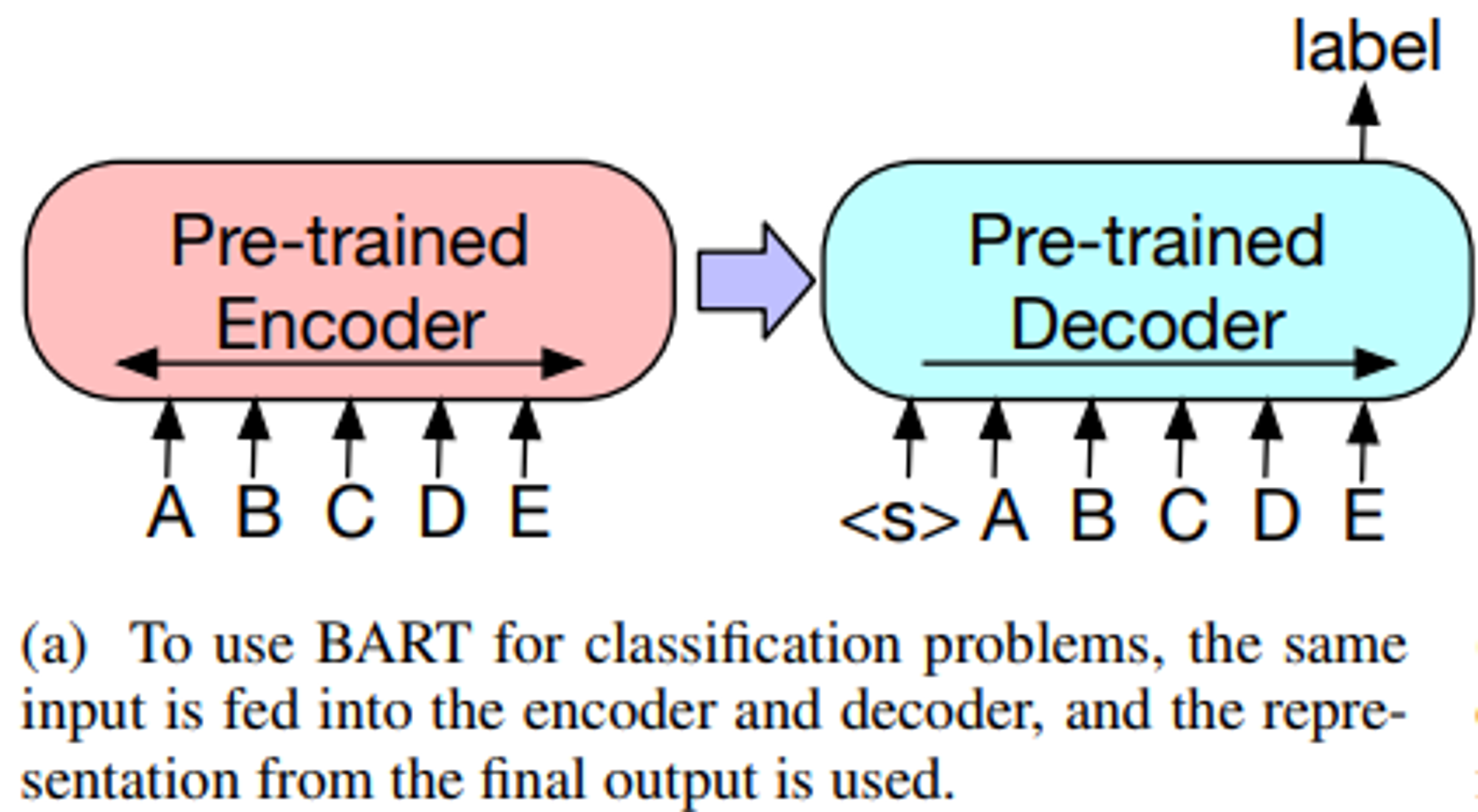
- Sequence classification 작업에서는 완전히 동일한 입력이 인코더와 디코더에 입력되고, 최종 디코더의 최종 은닉층이 새로운 multi-class 선형 분류기에 입력된다.
- 이는 BERT의 CLS 토큰과 관련이 있지만, BART에서는 마지막에 additional token을 추가하여 디코더의 토큰 표현이 전체 입력에서 디코더 상태에 주목할 수 있도록 한다.(Figure 3a)
3.2 Token Classification Tasks
- Token classification 작업에 대해서는, 인코더와 디코더에 전체 문서를 제공한 뒤 디코더의 최종 hidden state를 각 단어의 representation으로 사용한다.
- 이 표현은 토큰을 분류하는데 사용된다.
3.3 Sequence Generation Tasks
- BART는 autoregressive decoder를 갖고 있기 때문에, Abstractive QA나 Summarization과 같은 Sequence Generation 작업에도 바로 파인튜닝될 수 있다.
- 이러한 작업들에서, 정보는 input에서 복사되지만 변형된 형태로 복사되며, 이는 denoising pre-training의 목적과 관련이 있다.
- 인코더의 입력은 input 시퀀스이며 디코더는 autoregressive하게 출력을 생성한다.
3.4 Machine Translation
- 이전 연구에서는 pre-trained 된 인코더들을 결합하여 모델 성능을 개선할 수 있음을 보여주었지만, pre-trained된 디코더를 사용함으로서 얻을 수 있는 이점은 제한적이었다.
- Bitext(양방향 텍스트)로부터 학습된 인코더 파라미터 셋을 추가함으로써 전체의 BART 모델(인코더와 디코더 둘다)을 Machine Translation을 위한 단일 Pre-trained 디코더로 사용할 수 있음을 보여준다.(Figure 3b)
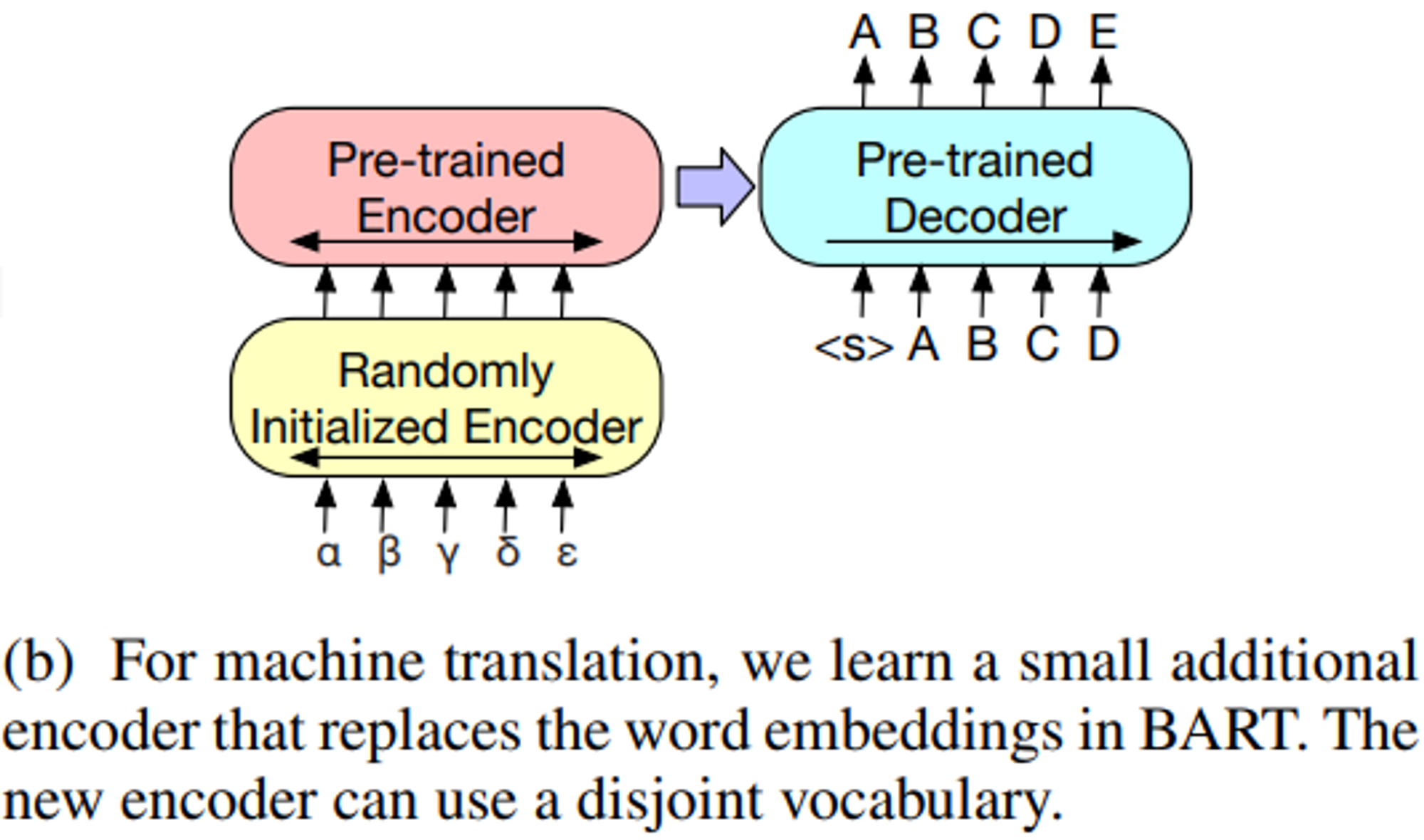
- 자세하게는,
- 기존 BART의 임베딩 레이어를 랜덤하게 초기화된 인코더로 교체한다.
- 이후 모델은 end-to-end로 학습되며, 모델의 새로운 인코더는 타겟 언어의 단어들(foreign words)을 input으로 매핑할 수 있도록 학습된다.
- 위 매핑을 통해 BART는 영어로의 de-noising이 가능하다.
- 교체되어 학습된 새로운 인코더는 기존의 BART과는 다른 별도의 vocab을 사용할 수 있게 된다.
- Source 인코더(원본 언어를 처리하는 인코더라서 source가 붙은 듯)는 2단계에 걸쳐서 학습되는데, 두 단계 모두 output에서의 cross-entropy loss를 역전파한다.
- 첫번째 단계에서는, BART의 대부분의 파라미터를 고정(freeze)하고, 랜덤하게 초기화된 source 인코더와 BART의 positional embeddings, 인코더 첫번째 레이어의 self-attention input projection matrix 만을 업데이트 한다.
- 두번째 단계에서는, 모든 파라미터를 작은 iteration으로 학습한다.
4. Comparing Pre-training Objectives
- BART는 pre-training 하는 과정에서 previous work보다 휠씬 더 넓은 범위의 노이징 방식을 제공한다.
- 이 논문에서는 base model에 대한 비교를 수행한다.
- 6개의 인코더, 6개의 디코더, hidden size 768 (인코더와 디코더에서의 각 출력 차원이 768차원이라는 의미인 듯)
- 해당 base 모델의 성능은 5장에서 평가된다.
4.1 Comparison Objectives
- Pre-training의 많은 목적이 제안되었지만, 부분적으로는 훈련 데이터, 리소스, 모델 간의 아키텍처 차이, 파인튜닝 절차의 차이 등으로 인해 공정한 비교를 수행하기 어려웠다.
- 우리는 판별(Discriminative)과 생성(Generation) task들을 위해 최근 제안된 강력한 pre-training 접근법을 다시 구현한다.
- 이는 pre-training의 목적과는 관련없는 차이들을 통제하는 것을 목표로 한다.
- 그러나 성능을 약간 향상시키기 위해 학습률과 계층 정규화의 사용률을 약간 수정한다.(각 pre-training 목적마다 다르게)
- 참고로, 이렇게 구현된 방식을, BERT와 비교한다.
- BERT도, BART도, 책과 Wikipedia 데이터에 대해 1M steps(100만 스텝)학습됐다.
- (같은 데이터로 동일한 스텝만큼 사전 학습 시켰으니까 어떤 사전 학습 방식이 좋은지, 어떤 모델이 좋은지 비교 가능 할 것!)
1) Language Model
- GPT와 비슷하게, left-to-right Transformer 언어 모델을 학습한다.
- 해당 모델은 Cross-Attention이 없는 BART 디코더와 동일하다.
2) Permuted Language Model
- XLNet을 기반으로, 1/6의 토큰을 샘플링하여 해당 토큰들을 자기회귀적(autoregressively)으로, 그리고 랜덤하게 생성한다.
- 다른 모델과의 일관성을 위해 XLNet의 다른 특징들(segment across attention, relative positional embeddings)은 구현하지 않았다.
3) Masked Language Model
- BERT를 따라서, 15%의 토큰을 [MASK]로 치환하고, 모델이 이를 독립적으로 예측하도록 훈련한다.
4) Multitask Masked Language Model
- UniLM과 마찬가지로, MLM에 self-attention mask들을 추가하여 학습시킨다.
- Self-attention mask들은 아래와 같은 비율로 랜덤하게 선택된다:
- 1/6: left-to-right
- 1/6: right-to-left
- 1/3: unmasked(마스크가 추가되지 않음)
- 1/3: 첫 절반 토큰들은 unmasked, 나머지 절반 토큰들은 left-to-right mask
- Self-attention mask들은 아래와 같은 비율로 랜덤하게 선택된다:
5) Masked Seq-to-Seq
-
MASS에서 영감을 받아, 토큰의 50%를 포함하는 span을 마스킹하고, 이 span을 예측하기 위해 seq-to-seq 모델을 학습한다.
-
Permuted LM, Masked LM, Multitask MLM에 대해서는, 시퀀스의 출력에 대한 가능성을 효율적으로 계산하기 위해 two-tream attention을 사용했다.
- Diagonal(대각선) self-attention mask를 출력 부분에 사용하여 왼쪽에서 오른쪽으로 단어들을 예측한다.
-
우리는 (1) task들을 표준적인 시퀀스-투-시퀀스 문제로 처리하는 방식으로 처리하거나, (2) 원본을 디코더 target 시퀀스의 prefix로 추가하는 방식, 두가지로 실험했다.
- (1) 첫번째 방식은 전통적인 방식으로, 인코더의 source과 디코더에 target을 별도로 다룬다. 인코더는 입력 시퀀스를 처리하고, 디코더는 출력 시퀀스를 처리한다.
- (2) 두번째 방식에서는, source 문장을 디코더의 target 시퀀스 앞에 접두사(prefix)로 추가하고, 모델의 loss는 타겟 시퀀스에만 적용된다.
- (source와 target을 연속된 시퀀스로 처리하니까 텍스트 관계 학습 면에서는 유리하고, 디코더 위주의 모델에서는 이러한 방식이 좋을 듯?)
-
BART는 (1)번 방식이 더 나은 성능을 보였고, (2)번 방식은 다른 모델들이 더 나은 성능을 보였다.
-
모델을 가장 직접적으로 비교하기 위해, Perplexity 수치를 비교한다.
- 참고) Perplexity(PPL)
: a metric that quantifies how uncertain a model is about the predictions it make
→ 선택 가능한 경우의 수를 수치화 (분기 계수, Branching Factor) - 특정 시점에서 평균적으로 몇 개에 선택지를 갖고 고민했는가?
- 더 낮은 PPL을 갖는 모델이 같은 테스트 데이터에 대해 더 일치할 것임
- 참고) Perplexity(PPL)
4.2 Tasks
1) SQuAD
- SQuAD는 Wikipedia 문단에 대한 Extractive QA 작업으로, 결과는 주어진 문서에서 추출된 text span이다.
- BERT와 비슷하게, question과 context(문서의 일부분)를 인코더 입력으로 사용하고, 추가적으로 BART는 이를 다시 디코더에도 전달한다.
- (BERT는 인코더만 있으니까…)
- (디코더에도 question과 context를 전달함으로써 generation 자체가 더 수월하게 진행되지 않을까 하는 생각)
2) MNLI
- MNLI는 한 문장이 다른 문장을 의미적으로 포함하는 여부를 예측하는 양방향 텍스트 분류 작업이다.
- 파인튜닝된 모델은 두개의 문장을 연결한 후(EOS토큰을 추가해서) 인코더와 디코더에 모두 통과시킨다.
- BERT와 다르게, BART의 EOS 토큰은 문장의 관계를 분류하는데에 사용된다.
3) ELI5
- ELI5는 긴 형식의 Abstractive QA 데이터셋이다.
- 모델은 question과 documents의 concatenation에 따라 answer를 생성한다.
4) XSum
- XSum은 뉴스 요약 데이터셋으로, Abstractive summaries를 포함한다.
5) ConvAI2
- ConvAI2는 대화 응답 생성 작업을 수행하며, context와 persona를 필요로 한다.
6) CNN/DM
- CNN/DM은 뉴스 요약 데이터셋이다.
- 이곳에서의 요약문은 일반적으로 source 문장과 밀접한 관련이 있다.
4.3 Results
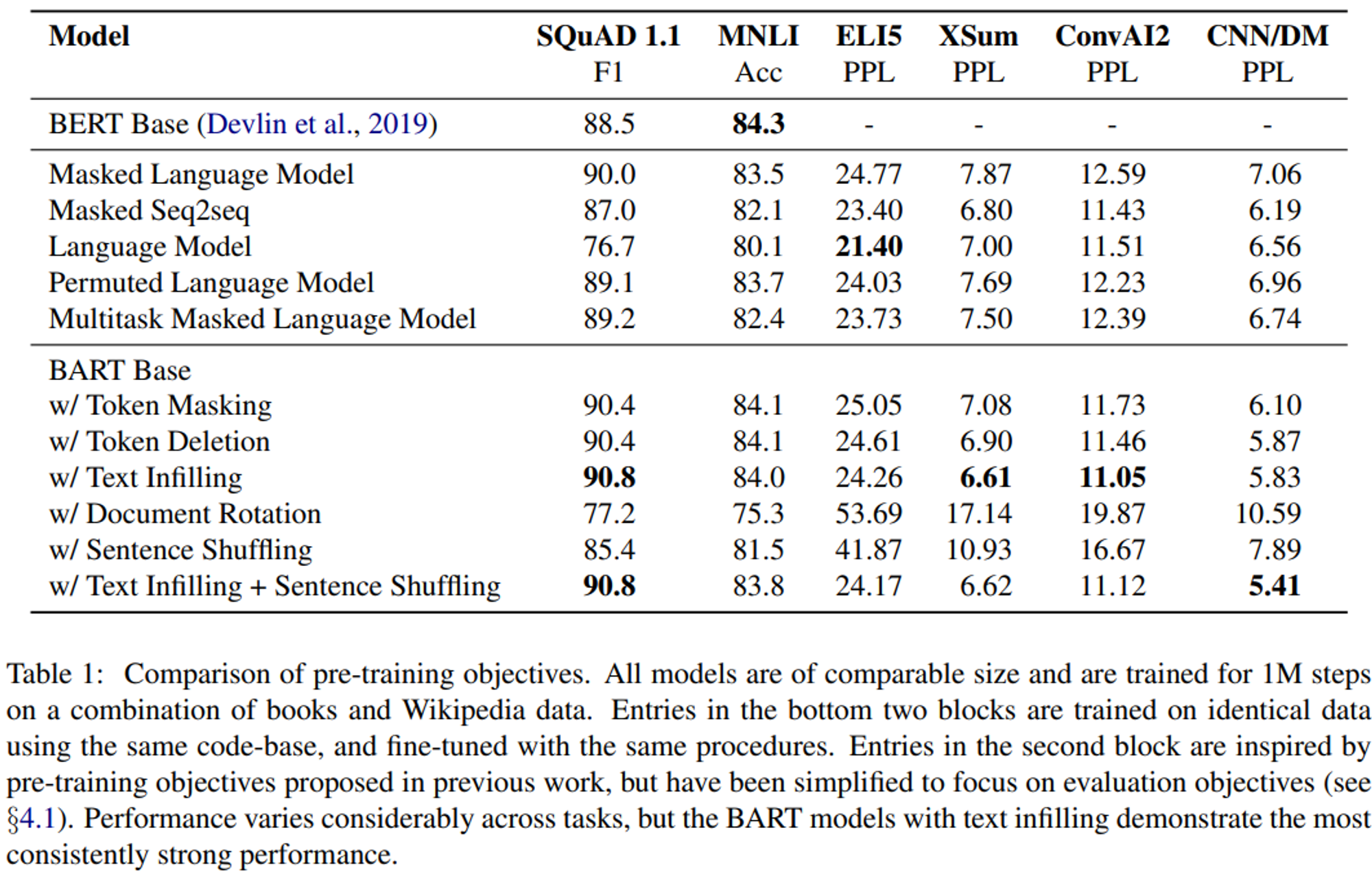
- 결과는 Table1 과 같으며, 다음과 같은 점들이 명확하게 드러났다.
1) Performance of pre-training methods varies significantly across tasks
= Pre-training 방법의 성능은 task에 따라서 크게 달라진다
- 단순한 Launguage Model은 ELI5에서 가장 높은 성능을 달성하지만, SQuAD에서 가장 안 좋은 성능을 보인다.
2) Token masking is crucial
= 토큰 마스킹은 매우 중요하다
- 문서를 회전(rotating)시키거나 문장을 순열 변경(permuting)하는 것 단독으로 사용하면 성능이 떨어진다.
- 참고)
- 회전(Rotating): 문서나 단락 안에서 내용을 ‘회전’, 즉 문장이나 단락의 순서를 바꾸는 것. 문장이나 단락의 내부 구조는 유지된다.
- 순열 변경(Permuting): 문장이나 토큰 내부의 순서를 변경하는 것. Ex) 문장 내부의 단어들의 순서를 무작위로 재배열하는 것.
- 참고)
- 성공적인 방법은 토큰 삭제 or 토큰 마스킹 or self-attention masks를 사용하는 것이다.
- Generation tasks에서는 토큰 삭제가 토큰 마스킹보다 성능이 뛰어난 것으로 나타났다.
3) Left-to-right pre-training improves generation
= Left-to-right pre-training은 생성 작업의 성능을 향상시킨다
- MLM과 Permuted LM은 Generation에서 다른 모델들보다 성능이 떨어진다.
- 또한 그 두 모델들은 pre-train 중에 left-to-right 자기회귀 언어모델링을 포함하지 않은 유이한 모델이다.
4) Bidirectional encoders are crucial for SQuAD
= SQuAD 작업에는 양방향 인코더가 매우 중요하다
- 분류 작업에서는 future context가 중요한 역할을 하기 때문에, left-to-right 디코딩만 수행하는 것은 SQuAD에서 낮은 성능을 보인다.
- 그러나 BART는 양방향 레이어 수의 절반만으로도 비슷한 성능을 달성한다.
- (대충 BART는 효율적인 양방향 처리를 할 수 있다는 자랑)
5) The pre-training objective is not the only important factor
= Pre-training의 목적 만이 중요한 factor는 아니다
- BART의 Permuted LM의 성능은 XLNet보다 떨어진다.
- 이는 XLNet의 특징인 relative-position embeddings이나 segment-level recurrence을 구현하지 않았기 때문일 수 있다.
6) Pure language models perform best on ELI5
= ELI5에서는 순수 Language model이 가장 높은 성능을 보인다
- ELI5는 다른 task보다 휠씬 복잡하며, 다른 모델이 BART보다 성능이 높은 유일한 Generation task이다.
- Pure LM이 가장 성능이 높으며, 이는 output이 input에 의해서 느슨하게 제한되는 경우 BART의 효율성이 떨어지는 것을 의미한다.
- (즉, 입력과 출력 사이의 관계가 덜 명확할 수록 BART는 효과적이지 않을 것이다!)
- (찾아보니 ELI5는 긴 길이의 abstractive 답변, 창의적 답변 생성 등이 필요하다고 함)
7) BART achieves the most consistently strong performance
= BART는 가장 일관되면서 강력한 성능을 달성한다
- ELI5를 제외하면 BART는 text-infilling을 사용하면서 모든 task에서 잘 동작한다.
5. Large-scale Pre-training Experiments
- 최근 연구에 따르면, pre-training을 대규모 배치 크기와 corpus로 확장하면 다운스트림 성능이 크게 향상될 수 있는 것으로 나타났다.
- 이러한 상황에서 BART가 얼마나 잘 동작하는지 테스트하기 위해 RoBERTa와 동일한 scale로 BART를 훈련시켰다.
5.1 Experimental Setup
- Large 모델에는 인코더와 디코더에 각 12개 레이어가 있고 hidden size는 1024이다.
- RoBERTa와 같이 배치 크기는 8000, step은 500,000이다.
- Documents는 GPT-2와 같이 BPE(byte-pair encoding)으로 토큰화된다.
- 섹션 4. 의 결과를 바탕으로, Text Infilling과 Sentence Permutation의 조합을 사용한다.
- 모든 문서에 대해 토큰의 30%는 마스킹하고, 모든 문장을 permute한다.
- Sentence Permutation은 CNN/DM summarization에서만 큰 이득을 보이지만, large pre-training 모델이 이 작업에서 더 잘 학습할 수 있다는 가설을 세웠다.
- 학습 데이터로는 RoBERTa와 동일하게 뉴스, 책, stories, web text로 구성된 160GB의 데이터를 사용한다.
5.2 Discriminative Tasks
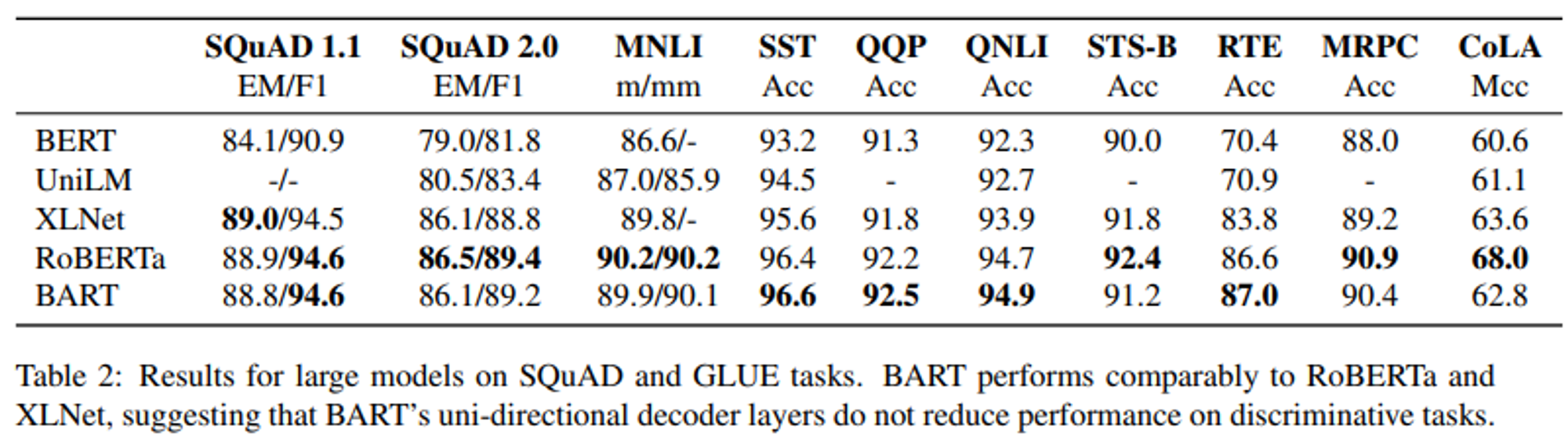
- Table 2는 SQuAD와 GLUE 벤치마크에 대해 BART와 다른 모델들의 성능을 비교한 표이다.
- 직접적으로 비교 가능한 기준은 동일한 리소스로 훈련되었지만 다른 objective를 가진 RoBERTa이다.
- BART는 대부분의 task에서 약간의 차이만 있을 뿐 비슷한 성능을 보인다.
- Generation task를 위한 BART의 개선이 Discriminative tasks에서의 성능도 희생시키지 않았음을 보여준다.
5.3 Generation Tasks
- BART는 표준적인 sequence-to-sequence 모델로 파인튜닝된다.
- 파인튜닝 동안 Label smoothed cross entropy loss를 사용하며, smoothing parameter는 0.1로 설정한다.
- Beam size는 5로 설정하며 beam search 과정에서 중복된 trigrams를 제거한다.
- Validation set에서 min-len, max-len, length penalty 를 설정하여 모델을 조정했다.
1) Summarization
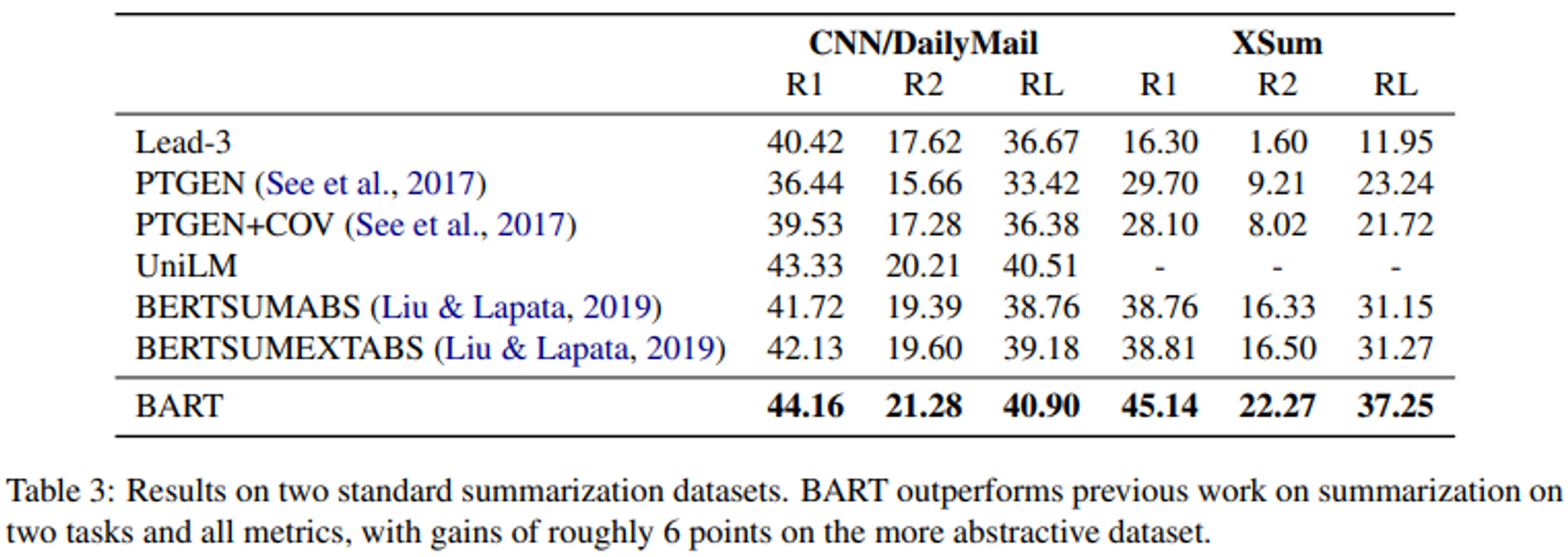
- 서로 다른 특성을 가진 CNN/DailyMail , XSum 두가지 데이터셋에 대한 결과를 제시한다.
- CNN/DM의 요약은 원본과 유사한 경향이 있다. Extractive 모델은 이 데이터셋에서 잘 동작하지만, 그럼에도 불구하고 BART는 기존 모든 작업보다 성능이 뛰어나다.
- XSum은 매우 abstracive하며, extractive 모델은 성능이 떨어진다.
- BART는 모든 ROUGE metric에서 6.0 정도 성능이 높으며, 번역의 질적으로도 품질이 뛰어나다(6장에서 다룸).
2) Dialogue
=대화 응답 생성
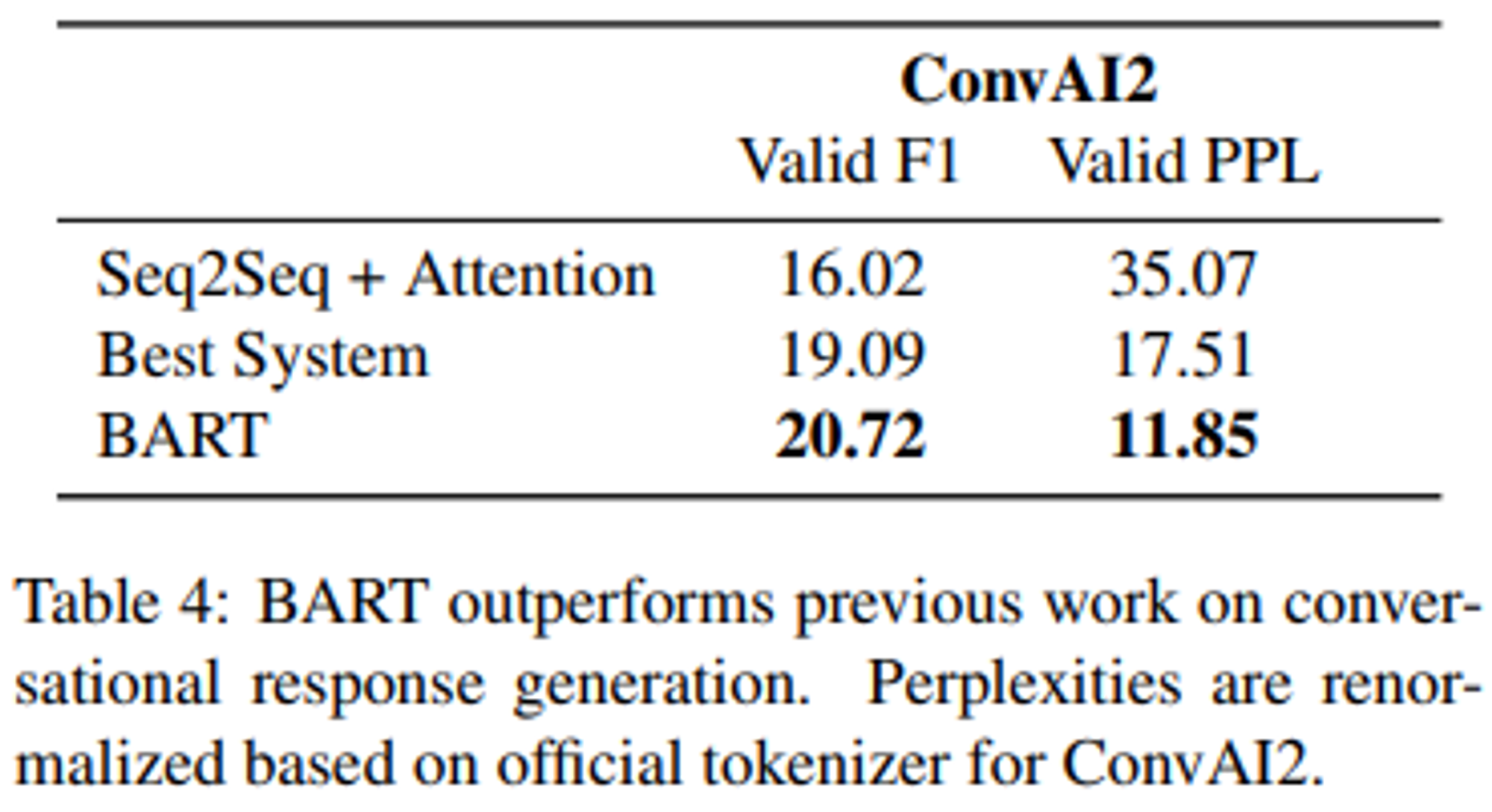
- ConvAI2에 기반하여 대화 응답 생성 작업을 평가했다.
- ConvAI2는 대화 에이전트가 반드시 persona와 이전 context를 고려하여 응답을 생성해야 하는 대화 응답 생성 작업이다.
- (따라서 단순히 이전 메세지에 반응하기만 하는 것이 아니라 persona의 특성도 고려해야 하고, 이전 context도 고려해야 함)
- BART는 이 작업에서 이전 모델들에 비해 두 개의 자동화된 metrics(Valid F1, Valid PPL)에 대해 더 높은 성능을 보였다.
- 참고) Valid ~~: Validation 데이터 셋에 대해 평가된 성능
3) Abstractive QA
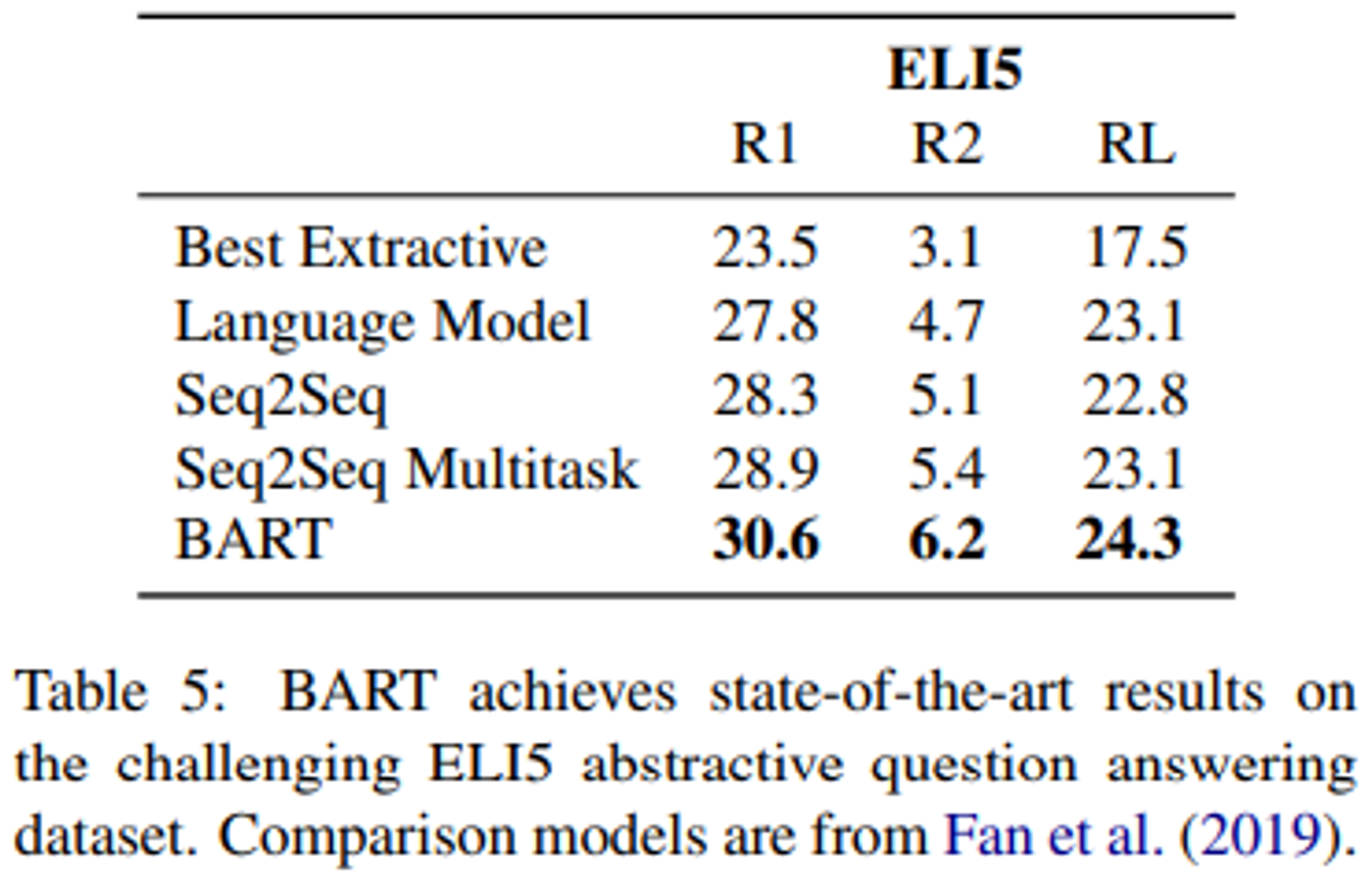
- BART는 ELI5 작업에서 1.2 ROUGE-L을 통해 이전 작업들보다는 높은 성능을 달성했지만, 질문에 따라서 답변이 약하게 지정되는 문제가 있어서 ELI5는 여전히 어려운 문제로 남아있다.
5.4 Translation

- WMT16 루마니아어-영어 번역 성능을 평가한다.
- 3.4에서 소개한 접근 방식에 따라 Transformer 인코더를 사용하여 루마니아어를 BART가 노이즈 제거를 통해 영어로 표현할 수 있는 representation으로 매핑했다.
- 결과는 Table 6과 같으며, baseline은 Transformer의 large setting이다.
- Beam size = 5, length penalty α = 1
- 역번역 데이터 없이는 BART의 접근 방식이 덜 효과적이며 과적합 경향이 있다.
- 향후 연구에서는 추가적인 정규화 기법이 연구되어야 한다.
6. Qualitative Analysis
- BART의 수치적인 성능을 넘어선 BART의 성능을 이해하기 위해 BART가 Generate하는 문장들을 분석한다.

- Table 7은 BART가 생성은 summary를 보여준다.
- BART의 output은 input에서 그대로 복사된 문구가 거의 없어 매우 추상적인 요약이라고 할 수 있다.
- 또한 output은 사실적이고 정확하며 input에 대한 background 지식(이름을 올바르게 완성하거나, 특정 기업이 어느 지역에서 운영된다거나 하는 등)을 잘 반영한다.
- 그러나 첫번째 예시에서 해당 연구가 Science지에서 출판되었다는 근거는 없다.
- 이러한 예시들은 BART Pre-training이 자연어와 generation에 대해 학습했음을 보여준다.
7. Related Work
- GPT, ELMo, BERT, UniLM, MASS, XLNet 등…
- GPT: GPT는 leftward한 정보(과거 정보)만 다루므로 일부 task에서 문제가 될 수 있다.
- ELMo: ELMo는 left-only 표현과 right-only 표현을 연결하지만, 이는 사전 훈련 단계에서 상호작용하지 않는다.
- BERT: MLM을 도입해서 양방향 상호작용을 도입했지만, autoregressive하지 않기 때문에 생성 task에는 적합하지 않다.
- UniLM: BERT를 다양한 마스킹 조합으로 파인튜닝하여 판별과 생성 task에서 모두 사용가능하지만, UniLM은 조건부 독립적이지만 BART는 autoregressive하다.
- MASS: 연속된 토큰의 범위(span)를 마스킹한 입력 시퀀스를 누락된 토큰으로 구성된 시퀀스에 매핑한다.(BART와 가장 비슷하다고 볼 수 있음) 그러나 인코더와 디코더에 제공되는 토큰이 다르기 때문에 판별 task에서는 성능이 비교적 낮다.
- XLNet: BERT를 확장하여 마스킹된 토큰을 순열 순서로 autoregressive하게 예측한다. 그 예측은 왼쪽이나 오른쪽 맥락을 모두 조건으로 할 수 있지만, BART는 생성 동안의 설정과 같이 left-to-right으로 동작한다.
8. Conclusion
- 우리는 손상된 문서를 원본으로 매핑하는 학습하는 pre-training 방식인 BART를 제안했다.
- BART는 Discriminative 작업들에서 RoBERTa와 유사한 성능을 달성했다.
- BART는 다양한 Generation 작업들에서 SOTA를 달성했다.
- 향후 작업: 특정한 end task들에 맞는 pre-training 방법을 개발하기 위해 문서를 손상시키는 새로운 방식을 찾아야 한다.

Anyone can be anything ... with agent!