
RAG
- FAIR이 처음 사용, 제안한 명칭 (NeurIPS 2020, https://arxiv.org/pdf/2005.11401)
- Pre-trained된 LM과 Retrieval component를 결합하여 광범위한 지식이 필요한 text generation의 성능을 개선하는 프레임워크
- Parametric memory (pre-trained seq2seq model (BART…)) + Non-parametric memory (dense vector index of external documents (Wiki …) accessed by neural retriever)
- 간단하게, 외부 DB 지식을 통합(검색)하여 LM의 생성 능력을 향상시키는 기술
Why RAG?
- LLM은 비약적인 성능 향상 이룸. But, 긴 길이의 텍스트 처리 한계 (Lost in the middle problem)
- RAG는 문서 모든 단락에 index를 생성해 쿼리와 관련성 높은 index를 LLM에게 전달
- LLM의 정보 과부하 방지하고 quality 향상
Neural Retrieval
- 신경망을 사용하여 쿼리를 관련된 문서와 연결하는 IR 모델
- 쿼리와 문서를 dense vector representation으로 인코딩하고 유사성 계산
- 이를 통해 의미적 관련성 포착 가능
- 기존 키워드 기반 IR에서 텍스트의 근본적 의미와 관계를 이해하는 시스템으로의 변화를 의미
- 일반적인 동작 단계:
- 벡터 인코딩
a. 신경망 기반 인코더에 의해 쿼리와 문서는 고차원 공간에서 벡터로 변환
b. 단어와 구 간 패턴, 관계 학습 - 시맨틱 매칭
a. 유사성은 코사인 유사도 등으로 계산
b. 단순 키워드 중복이 아닌 의미적 관련성 높은 문서 결정
- 벡터 인코딩
Neural Retrieval’s Advantages
- 단어가 사용된 문맥 이해 가능해 정확한 검색 가능
- 길고 복잡한 쿼리 처리 가능
- 다양한 언어 쿼리 처리 가능
Neural Retrieval’s Challenges
- 훈련과 추론 모두에 상당한 컴퓨팅 파워가 요구된다(특히 대규모 문서 인코딩)
- Neural Retrieval의 성능은 train data에 따라 크게 달라지며, data의 bias를 물려받을 수 있다
- 동적으로 변화하는 문서의 representation을 최신 상태로 유지하는 것은 쉽지 않다
RAG Pipeline
- RAG를 통해 LLM은 외부 지식에 접근하여 가중치에 포함되지 않은 정보를 활용
- Retriever는 semantic retrieval의 필요성에 따라 다음 중 하나가 될 수 있음
- Vector database: Dense vector는 BERT 등 사용, Sparse vector는 TF-IDF 등 사용. 이후 빈도 또는 유사성 기반으로 검색 수행
- Graph database: 텍스트에서 추출된 엔티티 관계로 지식 베이스 구축. 정확하지만 쿼리 매칭 필요할 수 있으며, 일부 task에서는 제한적일 수 있음
- Regular SQL database: 구조화된 데이터 저장과 검색이 가능하지만 의미론적 유연성 부족
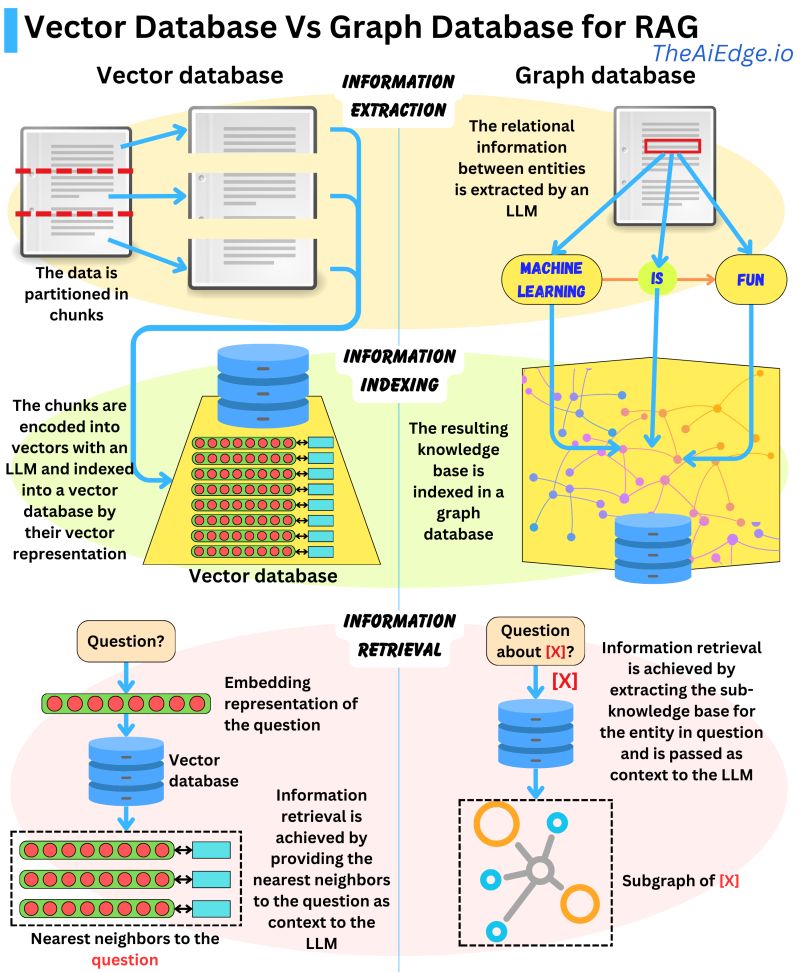
- Damien Benveniste에 의하면, Vector database보다 Graph Database가 RAG에서 선호
- Vector database는 인코딩된 벡터로 데이터를 분할하고 인덱싱하므로 의미적으로 유사한 벡터 검색이 가능하지만, 관련없는 데이터를 가져올 수 있다.
- 반면 Graph database는 텍스트에서 추출된 엔티티 관계로부터 지식 베이스를 구축하여 검색을 간결하게 만듦.
Process of RAG
- (Vector) Database Creation: 내부 데이터셋을 벡터, 혹은 지정된 형태로 변환한 뒤 데이터베이스에 저장한다.
- User Input: 사용자가 쿼리를 제공한다.
- Information Retrieval: Retrieval 매커니즘은 vector database를 스캔하여 쿼리와 의미론적으로 유사한 세그먼트를 식별한다. 이 세그먼트는 LLM에 제공돼 답변을 생성하는 context를 강화한다.
- Combining Data: Database에서 선택한 data 세그먼트가 쿼리와 결합하여 확장된 prompt가 생성된다.
- Generating Text: 확장된 prompt는 LLM에 전달되어 context-aware response를 생성한다.
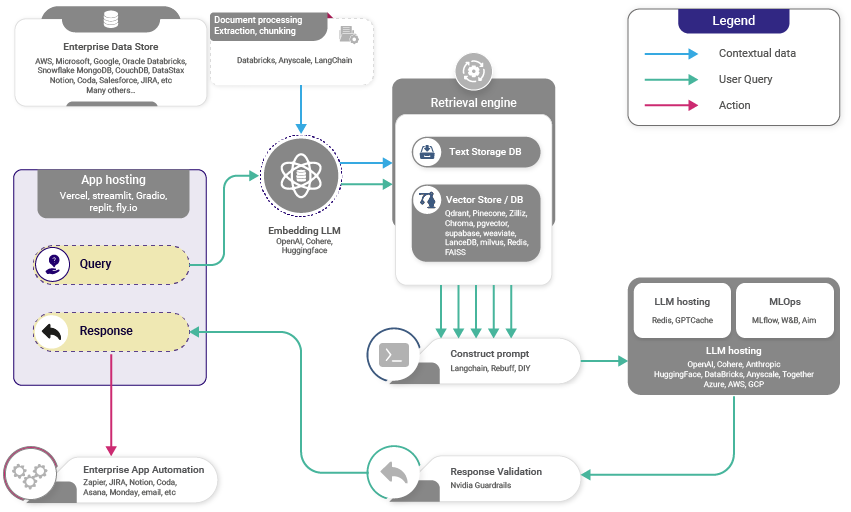
High-level working of RAG
Benefits of RAG
- RAG를 사용하면 LLM은 자신의 가중치에 포함되지 않은 정보를 외부 지식에 접근함으로써 활용 가능하다.
- RAG는 재학습이 필요없어 시간& 계산 리소스 절약 가능하다.
- 단점: 외부 지식의 포괄성과 정확성에 따라 RAG의 성능이 달라진다.
- RAG는 라벨 데이터가 제한적인 경우 효과적이며, 특정 정보에 실시간 접근이 필요한 application에 이상적이다.
- 인터넷에는 방대한 양의 텍스트가 있지만, 이 텍스트들이 구체적인 질문에 직접 답변하는 방식으로 이루어져 있지 않다.
- RAG는 제품 매뉴얼과 같은 외부 리소스에서 질문과 관련된 정보를 검색한 뒤, 이를 사용해 명확하고 간결한 답변을 생성한다.
- → RAG는 많은 정보가 사용 가능하지만 라벨이 지정되지 않은 어플리케이션에 잘 맞는다.
RAG vs. Fine-Tuning
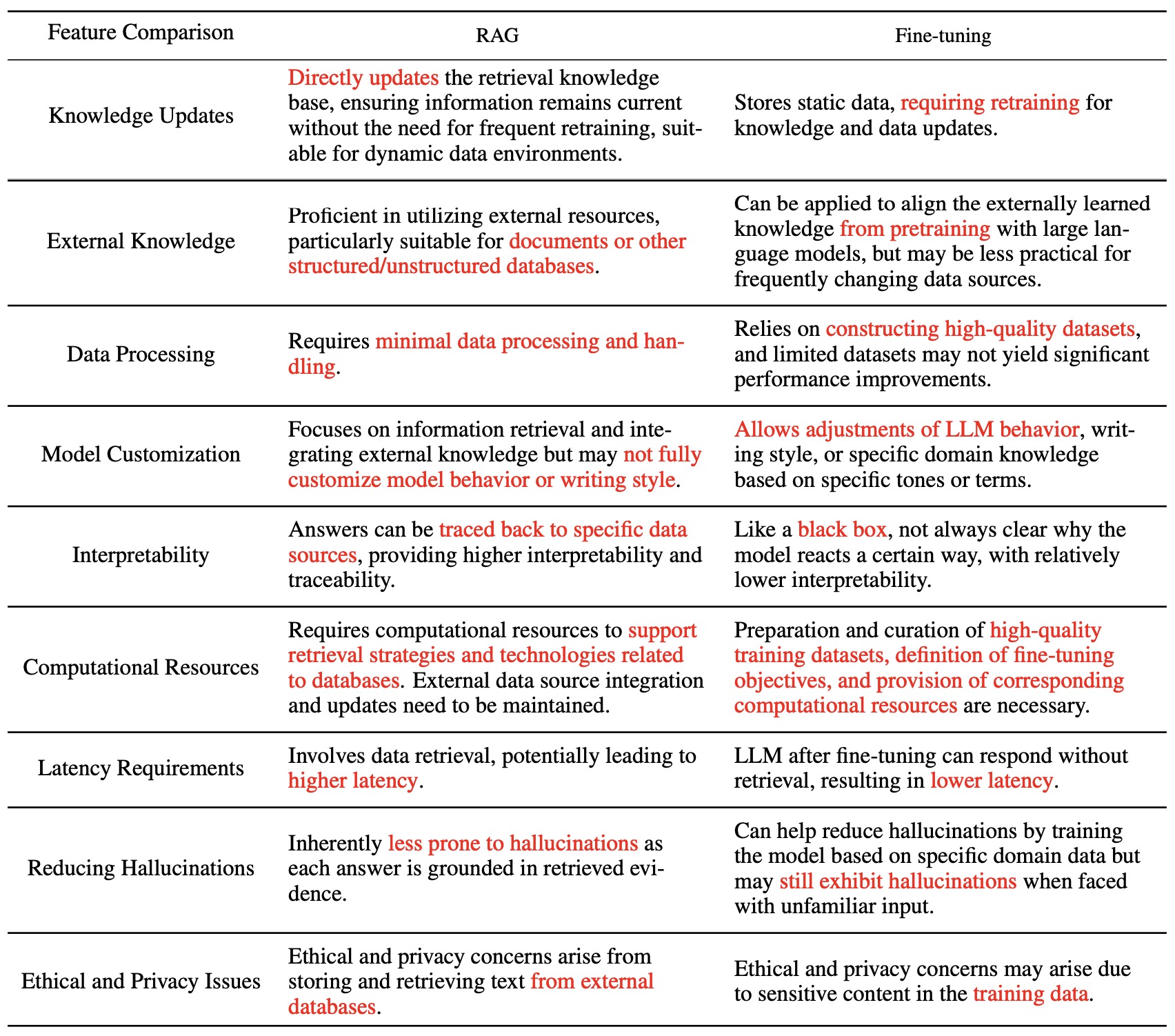
표 요약
- RAG는 LLM에게 사실적이고 적절한 정보에 대한 접근을 제공한다. 이는 LLM이 관련 데이터베이스에서 정확하고 검증된 사실을 직접 가져올 수 있게 한다. Fine tuning은 이를 일부 해결할 수 있지만, RAG는 최신 정보를 제공하며 fine tuning과 관련된 상당한 비용 없이 특정 정보를 제공하는 데 뛰어나다. 또한 RAG는 최신 데이터에 동적으로 접근하고 검색함으로써 모델이 현재 상태를 유지하고 관련성을 유지하도록 한다. 또한 RAG의 방식은 더욱 유연하고 확장 가능하여 쉽게 업데이트 가능하다.
- Fine tuning은 LLM의 스타일, 어조, 어휘 등을 조정하여 사용자의 언어적 방향성을 원하는 도메인에 맞게 조정된다. RAG는 이러한 수준의 커스텀을 제공하지 않는다.
- RAG에 먼저 집중하라. RAG 어플리케이션을 먼저 성공적으로 구축하면 그 뒤에 fine tuning을 추가할 수 있다.
Ensemble of RAG
- RAG의 앙상블을 통해 모델이 맥락적으로 정확한 텍스트를 생성하는 능력을 향상시킬 수 있다.
- Knowledge sources: RAG는 특정 도메인에서의 지식을 보완하기 위해 외부 지식 저장소에서 정보를 검색한다. 이는 Wikipedia, book, news 등에서의 paragraphs, tables, images가 포함될 수 있다.
- Combining sources: 추론 시점에 여러 retriever가 다양한 corpus에서 관련 내용을 가져오면, 이들은 candidates pool로 연결된다.
- Ranking: Candidates pool에 있는 후보들의 순위를 매긴다.
- Selection: 순위가 높은 후보들이 LM의 generation을 위해 선택된다.
- Ensembling: 다른 코퍼스에 특화된 RAG 모델들이 앙상블될 수 있다. 그 출력들은 합쳐져서 순위가 매겨지고 투표된다.
- 다양한 source를 통해 RAG를 보강할 수 있으며, pooling과 ensemble을 통해 이루어진다.
- 각 retriever의 다른 출력을 합쳐서 응답을 생성하기 전 순위를 매기는 것을 염두에 두어야 한다.
Building a RAG Pipeline
- Ingestion → Retrival → Synthesis/Response Generation
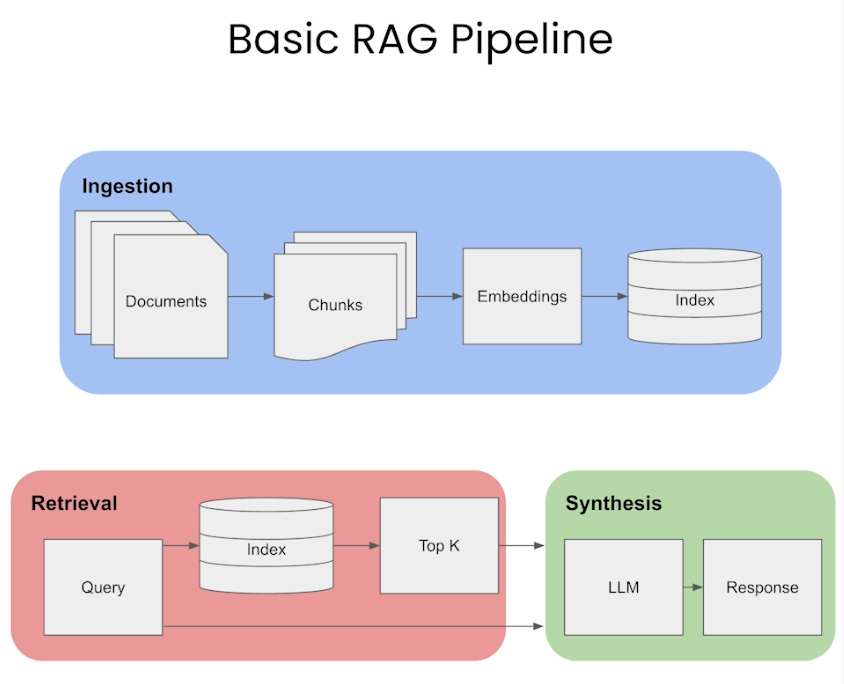
Ingestion
Chunking
- Chunking: prompt나 검색할 문서를 더 작고 관리하기 쉬운 segment 또는 chunk로 나누는 과정
- Chunk는 특정 문자, 문장 또는 단락 수 같은 fixed size로 정의될 수 있음
- RAG에서는 chunk가 검색을 위해 임베딩 벡터로 인코딩.
- 더 작고 정확한 chunk는 쿼리와 컨텐츠 간의 세밀한 일치를 이끌어내어 검색된 정보와의 정확성과 관련성을 향상시킨다.
- 큰 chunk는 관련없는 정보를 포함할 수 있으며, 이는 노이즈가 포함되고 검색 정확도를 낮출 수 있다. chunk 크기를 조절함으로써 RAG는 포괄성과 정밀성 사이의 균형을 유지한다.
- Chunk 크기를 정하는 방법 몇 가지:
- Fixed-size chunking: chunk에 포함될 토큰 수를 결정하고, chunk 사이에 overlap 허용 여부를 결정한다. chunk 간의 overlap은 semantic context loss를 최소화한다. 이 방법은 계산 비용이 적고 구현이 간단하다.
- Context-aware chunking: Context-aware chunking은 텍스트 구조를 활용하여 유의미하고 맥락적으로 관련된 chunk를 생성한다.
- Sentence Splitting
- Naive Splitting: 마침표와 개행을 이용하여 문장을 분할하는 기본적인 방법. 빠르지만 복잡한 문장은 간과할 수 있다.
- NLTK (Natural Language Toolkit): 파이썬 라이브러리, 텍스트를 문장으로 효과적으로 분할하는 sentence tokenizer가 포함되어 있다.
- spaCy: NLP 작업을 위한 고급 파이썬 라이브러리, 효율적인 문장 분할 제공.
- Recursive Chunking: 다양한 구분자를 사용해 계층적으로 텍스트 분할하는 반복적 방법. 재귀적으로 다른 기준을 적용하여 비슷한 크기나 구조의 chunk를 생성
- Specialized Chunking: Markdown이나 LaTeX 같은 formatted content는 원래 구조를 유지하면서 chunking을 수행한다.
- Markdown Chunking: Markdown 구문을 인식하고 구조에 따라 콘텐츠를 나눔
- LaTeX Chunking: LaTeX 명령어와 환경을 구문 분석하여 콘텐츠를 chunking하면서 논리적 구성을 보존
- Sentence Splitting
- 일반적으로, text chunk가 주변 맥락 없이도 인간에게 유의미하다면, LM에게도 유의미할 것이다. 따라서 corpus의 문서에 대한 optimal chunk size를 찾는 것이 검색 결과의 정확성과 관련성을 보장하는데 중요하다.
Embeddings
- Prompt와 문서를 임베딩한다는 것은 쿼리와 지식 기반 문서를 효과적으로 비교할 수 있는 형식으로 변환하는 것을 포함하며, RAG 능력에 매우 중요하다
- 임베딩 방식에서 Dense embedding과 Sparse embedding을 사용할 지의 문제가 있다.
- Sparse Embedding: TF-IDF 등의 sparse embedding은 prompt와 문서 간의 어휘적 일치를 찾는데 좋아 키워드 관련성이 중요한 application에 적합하다. 계산 비용이 낮지만 텍스트의 깊은 의미를 포착하지 못할 수 있다.
- Semantic Embedding: BERT나 SentenceBERT같은 semantic embedding은 그 자체로 자연스럽게 RAG에 적합하다.
- BERT: 쿼리와 문서의 문맥적 뉘앙스를 포착하는 데 적합하다. Sparse embedding에 비해 계산 리소스가 더 필요하지만, 의미론적으로 더 풍부한 임베딩을 생성한다.
- SentenceBERT: 문장 수준에서 의미와 문맥이 중요한 경우에 이상적이다. BERT의 깊은 문맥 이해와, 유의미한 sentence representation 사이에서 균형을 맞춘다. RAG에 보통 선호되는 방법이다.
Sentence Embeddings: the What and Why
- Background: Differences Compared to Token-Level Models Like BERT
- Sentence Transformers는 전통적인 BERT 모델을 수정한 것으로, 전체 문장을 생성하는데 특화되어 있다. 학습 과정에서의 차이점은 아래와 같다
- Objective: BERT는 문장에서의 masked words와 다음 문장을 예측하도록 학습된다. 반면 Sentence Transformers는 전체 문장의 의미를 이해하도록 훈련된다. 유사한 의미를 가진 문장들이 임베딩 공간에서 가깝게 생성된다.
- Level of Embedding: BERT는 토큰(word or subword) 단위의 임베딩을 제공하지만, Sentence Transformers는 전체 문장에 대한 단일 임베딩을 제공한다.
- Training Data and Tasks: BERT는 문맥 속 단어 이해에 중점을 둔 작업으로 대규모 text corpus에서 학습이 이루어지지만, Sentence Transformers는 문장 쌍을 포함하는 데이터셋에서 자주 훈련된다. 이는 유사성과 관련성에 중점을 두어 모델이 전체 문장의 의미를 이해하고 비교하는 방법을 학습싴킨다.
- Siamese and Triplet Network Structures: Sentence Transformers는 종종 샴 네트워크나 triplet 네트워크 구조를 사용한다. 이 네트워크들은 pair나 triplet으로 구성된 문장들을 처리하고, 유사한 문장들이 유사한 임베딩을 가지고 다른 문장들은 다른 임베딩을 가지도록 모델을 조정하는 작업을 수행한다. 이는 BERT의 학습과는 다르며, 별개의 문장들을 직접적으로 비교하는 것을 본질적으로 포함하지 않는다.
- Fine-tuning for Specific Tasks: Sentence Transformers는 BERT보다 문장 수준의 이해에 더 중점을 두고 있어 semantic similarity, IR과 같은 특정 작업에 자주 fine-tuning된다. BERT는 QA, sentimental analysis 등 더 넓은 범위의 NLP 작업에 미세 조정될 수 있다.
- Applicability: BERT와 유사 모델들은 토큰 level의 이해가 필요한 작업(named entity 인식, QA 등)에 더 다양하게 사용될 수 있는 반면, Sentence Transformers는 문장 수준의 이해에 의존하는 작업(semantic search, sentence similarity)에 더 적합하다.
- Efficiency in Generating Sentence Embeddings or Similarity Tasks: BERT에서 문장 임베딩을 생성하는 것은 일반적으로 문장 시작 토큰인 [CLS]를 사용하는 것을 포함한다. 그러나 이는 문장 level의 작업에 항상 최적은 아니다. Sentence Transformers는 유의미하고 유용한 문장 임베딩을 생성하도록 최적화되어 있어 더 효율적이다. 문장마다 단일 벡터를 생성하므로 문장 간 유사도 점수를 계산할 때 계산 비용이 낮다.
- Sentence Transformers는 전통적인 BERT 모델을 수정한 것으로, 전체 문장을 생성하는데 특화되어 있다. 학습 과정에서의 차이점은 아래와 같다
- Related: Training Process for Sentence Transformers vs. Token-Level Embedding Models
- Sentence Transformer는 sentence level에서 임베딩을 생성하도록 훈련되며, 이는 BERT와 같은 token level 임베딩 모델의 접근 방식과는 확연히 다르다.
- Model Architecture: Sentence transformer는 BERT나 다른 transformer 구조와 비슷한 base model로 시작한다. 하지만 개별 토큰이 아닌 각 input sentence 전체에 대해서 임베딩 벡터를 출력하는데 초점을 맞춘다.
- Training Data: Sentence transformer는 문장 간의 관계(유사성, paraphrasing 등)가 정해진 문장 쌍이나 그룹을 포함한 다양한 데이터셋으로 학습된다.
- Training Objectives: BERT는 token level에서의 문맥 이해를 중점으로 하여 masked language modeling(다음 단어 예측)과 next sentence prediction과 같은 objectives로 pre-trained 된다. 반면 sentence transformer는 sentence level의 문맥과 관계성을 이해하기 위해 특화되어 학습된다. 이들의 objective는 의미론적으로 유사한 문장들의 임베딩 거리를 최소화하고, 의미가 다른 문장들의 임베딩 거리를 최대화하는 것이다. 이는 triplet loss, cosine similarity loss 등의 contrastive loss function을 통해 수행된다.
- Output Representation: BERT에서의 sentence level representation은 일반적으로 [CLS]와 같은 special token의 임베딩 또는 token embedding을 pooling하여 도출된다. Sentence transformer는 directly하게 유의미한 sentence level representation을 출력하도록 설계되었다.
- Fine tuning for Downstream Tasks: Sentence transformer는 semantic text similarity와 같은 특정 작업에서 fine tuning 될 수 있으며, 모델은 전체 문장의 미묘한 의미를 포착하는 임베딩을 생성하는 방법을 학습한다.
- Applying Sentence Transformers for RAG
- Sentence transformer가 RAG를 위한 임베딩 생성 모델로써 왜 최선의 선택인가
- Improved Document Retrieval: Sentence transformer는 문장의 의미론적 의미를 포착하는 임베딩을 생성하도록 훈련된다. RAG setting에서 이러한 임베딩은 DB의 가장 관련있는 문서와 쿼리를 일치시키는 데 사용할 수 있다. 이는 생성된 응답의 quality가 검색된 정보의 관련성에 의존하기 때문에 중요하다.
- Efficient Semantic Search: 전통적인 키워드 기반 검색 방법은 쿼리의 맥락이나 의미론적 뉘앙스를 이해하는 데 어려울 수 있다. 의미론적으로 유의미한 임베딩을 생성하는 Sentence transformer는 키워드의 일치를 넘어서 더 미묘한 검색을 가능하게 한다. 이는 RAG의 검색 구성 요소가 정확한 키워드를 포함하지 않더라도 쿼리와 의미론적으로 관련된 문서를 찾을 수 있음을 의미한다.
- Contextual Understanding for Better Responses: Sentence transformer를 사용하면 RAG 모델은 쿼리와 source 문서의 맥락과 뉘앙스를 더 잘 이해할 수 있다. 이는 모델이 더 관련성 있고 잘 이해된 정보로 작업을 수행할 수 있기 때문에 정확하고 맥락적으로 적합한 응답을 생성할 수 있다.
- Scalability in Information Retrieval: Sentence transformer는 모든 문서에 대한 임베딩을 사전에 계산함으로써 대규모 문서 DB를 효율적으로 처리한다. 이는 모델이 런타임에서 쿼리의 임베딩만을 계산한 다음 가장 가까운 문서 임베딩을 빠르게 찾을 수 있게 해서 retrieval process를 더 빠르고 확장 가능하게 한다.
- Enhancing the Generation Process: RAG setting에서 generation component는 retrieval component의 ‘관련성이 높고 의미론적으로 rich한 정보를 제공할 수 있는 능력’으로부터 이득을 얻는다. 이를 통해 LM은 모델 자체가 학습된 정보보다 더 넓은 범위의 정보를 바탕으로 맥락적으로 정확한 답변을 생성할 수 있다.
- Sentence transformer는 효과적인 semantic search과 retrieval of information을 가능하게 함으로써 RAG 모델과 LLM의 검색 능력을 향상시킨다. 이는 QA, 챗봇, 정보 추출 등 대량의 텍스트 데이터를 이해하고 이를 기반으로 response를 생성해야 하는 작업에서 성능을 향상시킨다.
Retrieval
- Retrieval의 유형에는 3가지가 있다. Standard / Sentence window / Auto-merging
Standard/Naive Approach
- Standard pipeline은 indexing/embedding과 output synthesis에 모두 동일한 text chunk를 사용한다.
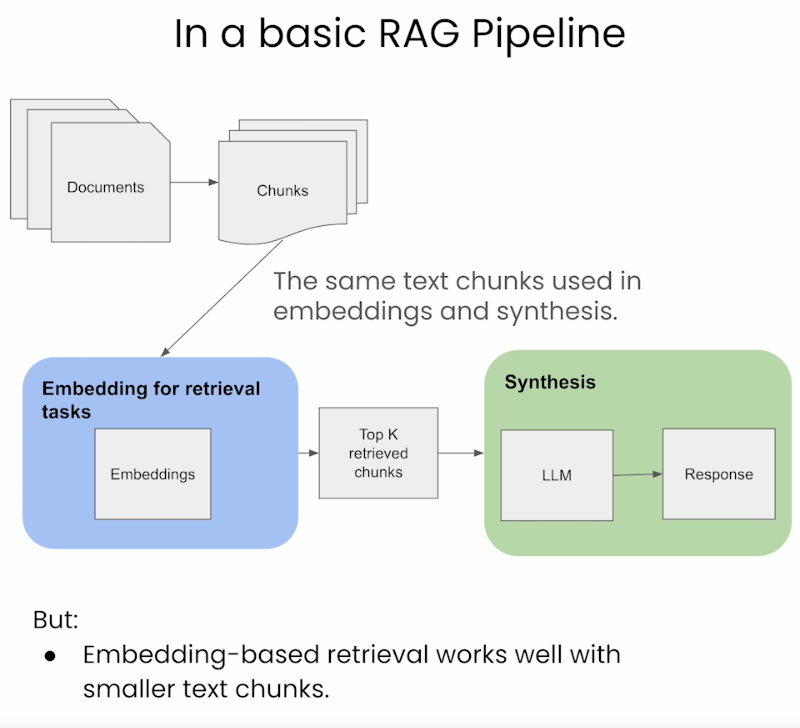
Advantages
- Simplicity and Efficiency: 이 방법은 간단하고 효율적으로, 임베딩과 합성 모두에 동일한 text chunk를 사용하여 검색 과정을 단순화한다.
- Uniformity in Data Handling: 검색과 합성 단계에서 사용되는 데이터의 일관성이 유지된다.
Disadvantages
- Limited Contextual Understanding: LLM은 더 나은 response를 생성하기 위해 더 큰 window가 필요할 수 있는데, standard 방식은 이를 제공하지 못할 수 있다.
- Potential for Suboptimal Responses: 제한된 context를 갖고 있기 때문에, LLM은 가장 관련성 있고 정확한 response를 생성할 수 있는 충분한 정보를 갖고 있지 않을 수 있다.
Sentence-Window Retrieval / Small-to-Large Chunking
- Sentence-window 접근법은 문서를 더 작은 단위로 쪼갠다(문장이나 문장의 그룹으로).
- Retrieval 을 위한 임베딩(벡터 DB에 저장된 더 작은 chunk)을 분리하지만, 합성을 위해 검색된 chunk 주변 context에 다시 추가된다.
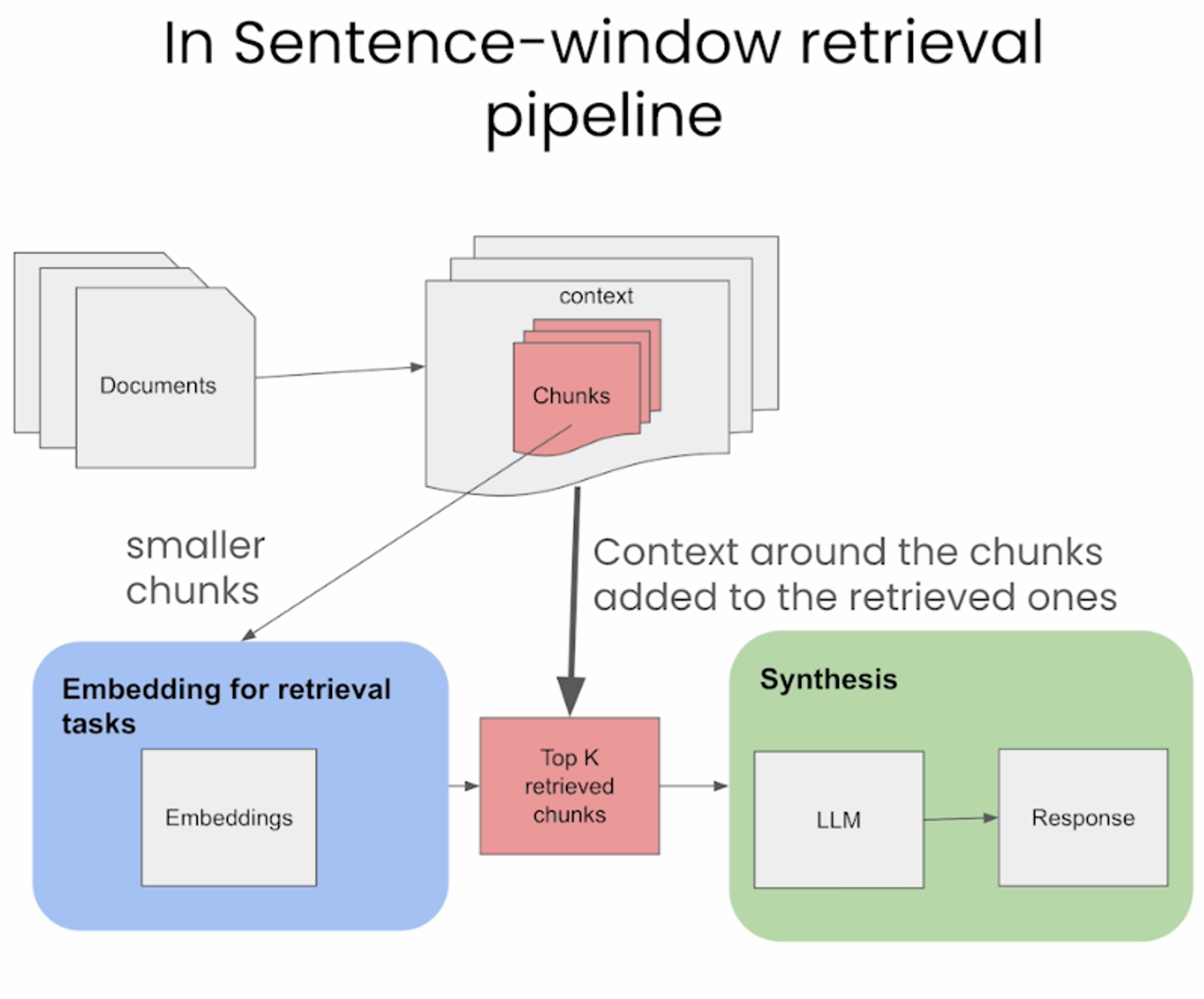
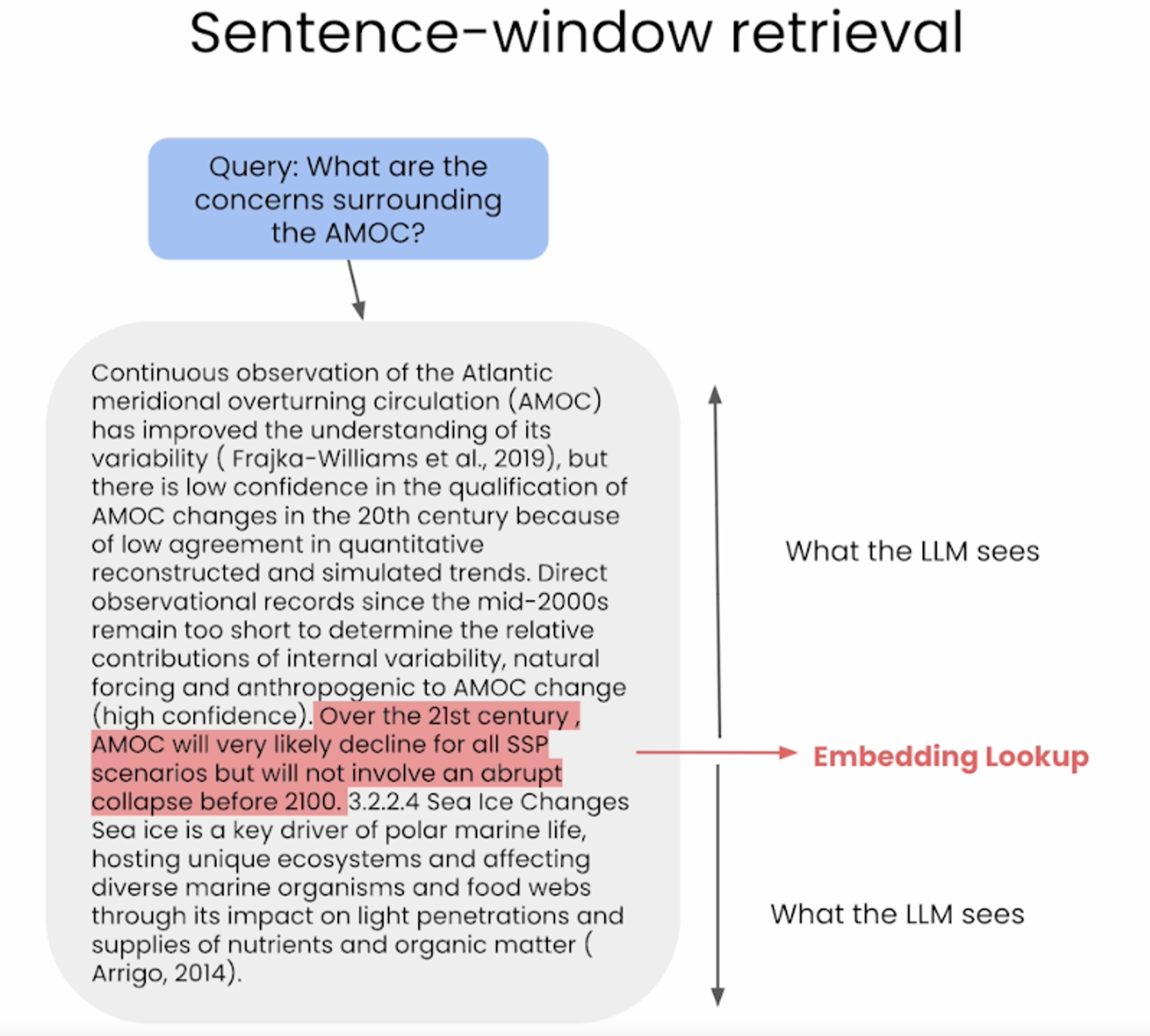
- Retrieval 동안 유사도 검색을 통해 쿼리와 가장 유사한 문장을 검색하고, 문장을 주변 문맥으로 대체한다.
Advantages
- Enhanced Specificity in Retrieval: 문서를 더 작은 단위로 나눔으로써, 쿼리와 직접적으로 관련된 세그먼트를 더 정확하게 검색할 수 있다.
- Context-Rich Synthesis: 검색된 청크 주위에 context를 다시 도입하여, response를 작성할 때 더 넓은 understanding을 제공한다.
- Balanced Approach: focused한 검색과, 풍부한 context 사이에서 균형을 이루어 response의 퀄리티를 높일 수 있다.
Disadvantages
- Increased Complexity: retrieval과 통합 과정을 별도로 관리해야 하므로 pipeline의 complexity가 증가한다.
- Potential Contextual Gaps: 추가된 주변 정보가 포괄적인 정보가 아니라면 context를 놓칠 수 있다.
Auto-merging Retriever / Hierarchical Retriever
-
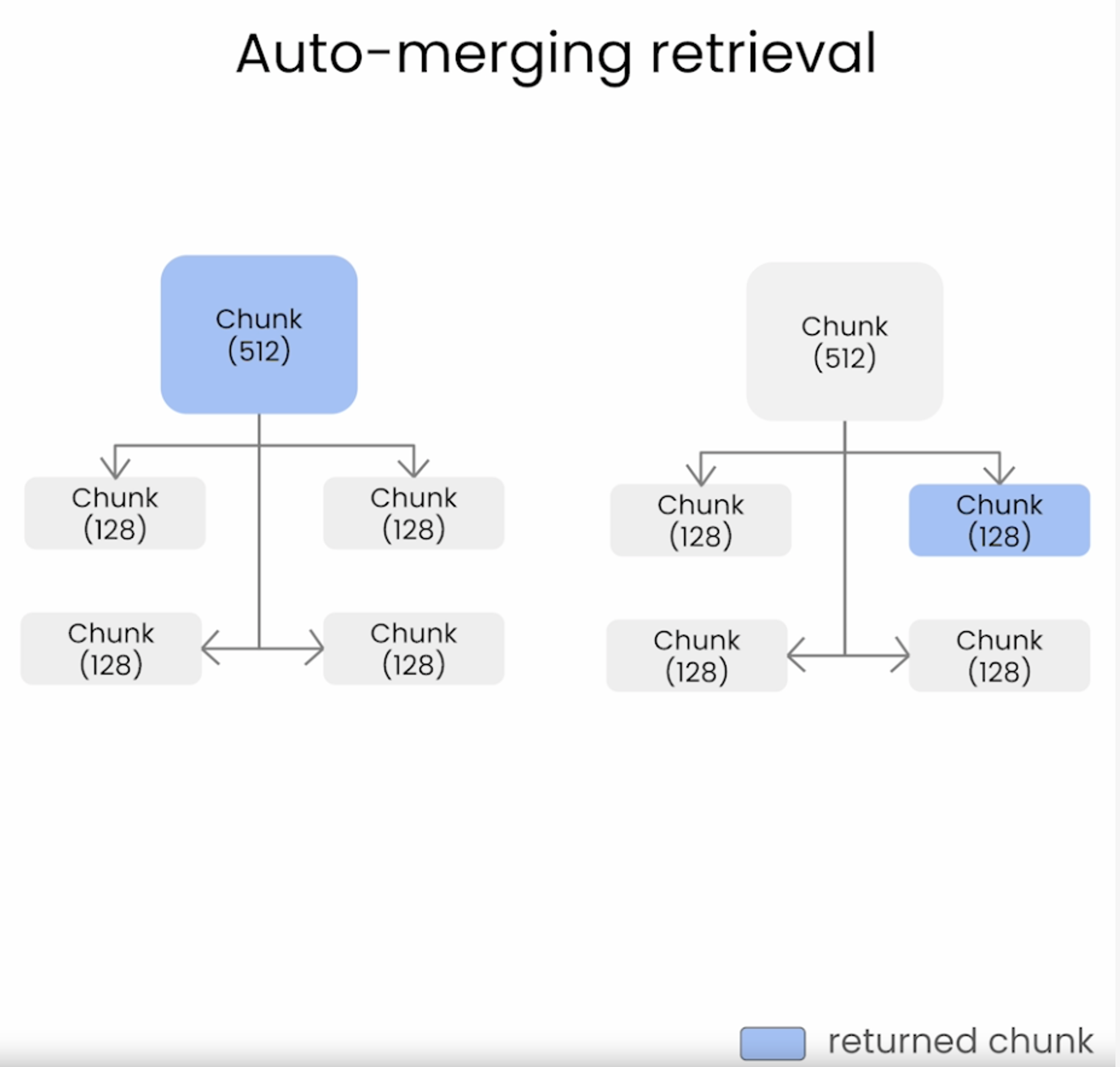
이전에 설명한 naive한 retrieval 방식은 chunk size가 작을수록 fragmented된 chunk들을 처리하는 데 어려움을 겪는다. (아래 그림 참고)
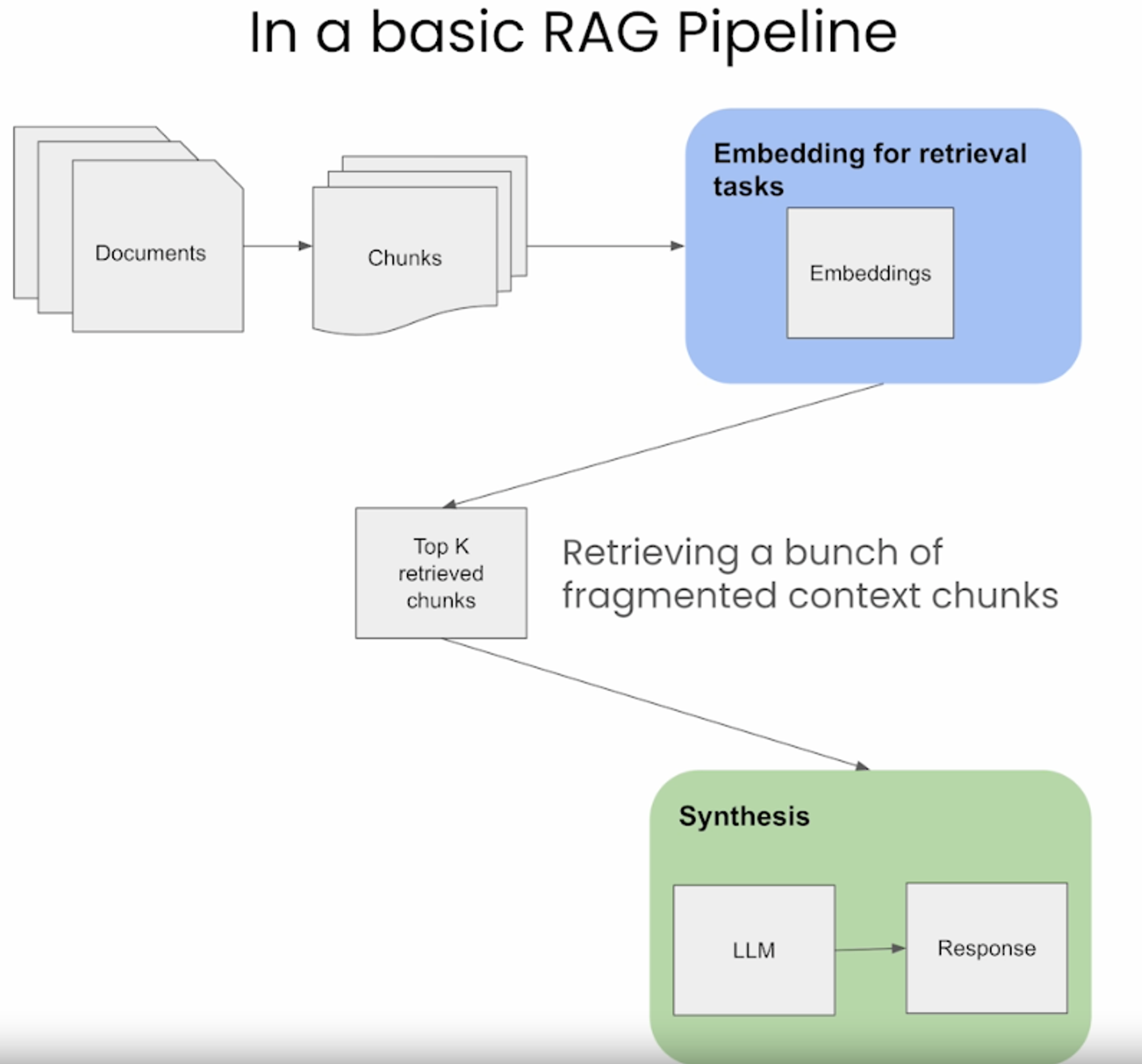
-
Auto-merging retrieval은 아래 그림과 같이 naive 방법에서 발생할 수 있는 fragmented chunk를 검색하지 않도록 한다.
-
Auto-merging retrieval은 여러 source나 text segment에서 정보를 결합해 쿼리에 대해 맥락적으로 유의미한 response를 생성하는 것을 목표로 한다. 이 방식은 source가 여러 개일 때 특히 유용하다.
-
Auto-merging retrieval은 작은 chunk를 더 큰 상위 chunk로 합칠 수 있게 하며, 다음과 같은 단계로 이루어진다.
- 상위 chunk에 연결된 작은 chunk의 계층 구조를 정의한다.
- 상위 chunk에 연결된 작은 chunk set이 일정 threshold(ex: 코사인 유사도)를 넘는다면, 작은 chunk를 더 큰 상위 chunk에 병합한다.
-
최종적으로는 상위 chunk를 검색하게 된다.
Advantages
- Comprehensive Contextual Responses: 여러 source에서 정보를 가져오므로 더 포괄적이고 맥락적으로 관련있는 응답을 생성할 수 있다.
- Reduced Fragmentation: naive approach와 작은 chunk 크기에서 특히 자주 발생하는 fragmented information retrieval 문제를 어느 정도 해결한다.
- Dynamic Content Integration: 작은 chunk를 큰 chunk로 동적으로 결합하는 것은 LLM에게 제공되는 정보의 richness를 향상시킨다.
Disadvantages
- Complexity in Hierarchy and Threshold Management: hierachy를 정의하는 것과 적절한 임계값을 설정하는 것은 복잡하며, 이러한 과정은 매우 중요하다.
- Risk of Over-generalization: 너무 많은 정보나 관련없는 정보를 병합하는 것은 response가 지나치게 광범위해지거나 주제에서 벗어나게 될 가능성이 있다.
- Computational Intensity: chunk의 hierachy를 관리하는 추가적인 단계로 인해 많은 컴퓨팅 자원이 필요할 수 있다.
Figuring Out the Ideal Chunk Size
- RAG 시스템을 구현할 때에는 고려해야 할 retrieval 파라미터와 전략이 매우 많다(chunk 크기, 벡터 vs 키워드 vs 하이브리드 검색 방식 등). 이 중 chunk size를 살펴본다.
- RAG 시스템을 구축하는 과정에서 retrieval 컴포넌트가 처리할 문서의 이상적인 chunk 크기를 결정하는 것이 중요하며, 그 이상적 크기는 여러 요인에 따라 달라진다.
- Data Characteristics: 텍스트 문서의 경우, 단락의 평균 길이나 섹션의 평균 길이를 고려해야 한다. 문서가 구분된 섹션으로 잘 구조화되어 있다면, 그런 자연스러운 구분이 chunk size로서의 좋은 기준이 될 수 있다.
- Retriever Constraints: 선택한 retriever 모델(BM25, TF-IDF, 신경망 기반 retriever like DPR)이 입력 길이에 제한이 있을 수 있다. chunk가 이러한 제약에 맞추어 구성되어야 한다.
- Memory and Computational Resources: chunk 크기가 커지면 연산량이 늘어나므로 효율적인 처리를 위해 가용 자원에 맞추어 chunk 크기를 조절해야 한다.
- Task Requirements: task의 성격(ex: QA, summarization 등)에 따라 이상적인 chunk의 size가 달라질 수 있다. Detailed task에서는 specific detail을 포착하기 위해 작은 chunk size가 유리할 수 있으며, broad한 task에서는 비교적 큰 chunk size가 유리할 수 있다.
- Experimentation: 이상적인 chunk size를 결정하는 가장 좋은 방법은 실험을 통해서 정하는 것이다. 다양한 실험에서의 성능 평가를 통해 세밀함과 맥락 사이의 균형을 찾아야 한다.
- Overlap Consideration: chunk 간의 overlap이 있는 것이 경계 구간에서 중요한 정보를 놓치지 않도록 하는 데 유리하다. task나 데이터 특성에 따라 적절한 overlap 크기를 정해야 한다.
Retriever Ensembling and Reranking
- Thought: 여러 chunk 크기를 동시에 시도해보고, re-ranker(재정렬기)가 결과를 가지치기(prune)할 수 있다면 어떨까?
- 이는 두 목적을 달성할 수 있다:
- Re-ranker의 성능이 적당한 수준이라면, 다양한 chunk 크기로부터 도출된 결과를 모아서 더 나은 검색 결과를 얻을 수 있다(비록 비용은 더 많이 들지만).
- Re-ranker에 대해 서로 다른 retrieval 전략을 서로 비교하는 벤치마크를 제공할 수 있다.
- 프로세스는 다음과 같다:
- 하나의 문서를 여러 방법으로 chunk 한다. 예를 들어 128, 256, 512, 1024를 chunk size로 한다.
- Retrieval 중에, retriever에서 유사한 chunk를 가져오고, 이를 앙상블하여 retrieval을 수행한다.
- Re-ranker을 사용하여 순위를 매기고 prune한다.
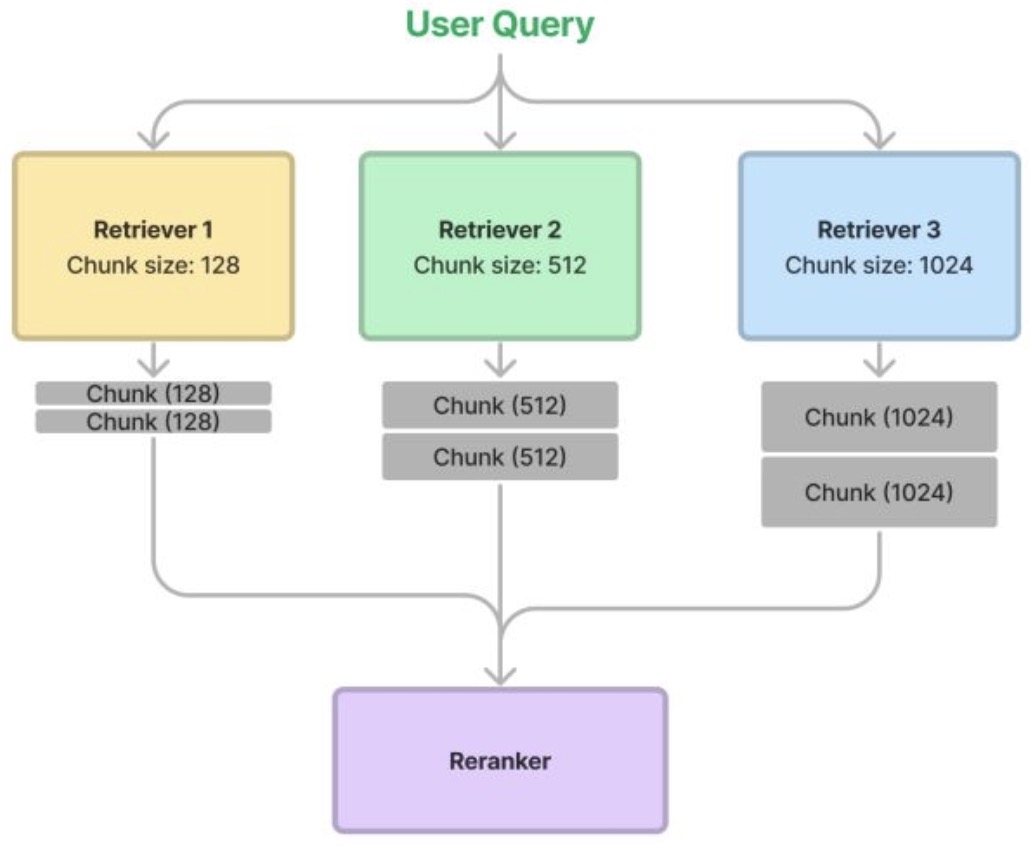
- Ensemble 접근법의 faithfulness 지표가 약간 상승하여 검색된 결과가 약간 더 유사성이 있는 것으로 나타났다. 그러나 pairwise comparisons에서는 equal preference로 나타나, 앙상블 방식이 더 나은지 여부는 여전히 의문이다.
Re-ranking
- RAG에서 re-ranking은 검색된 문서들이나 정보 조각들을 쿼리나 작업과의 관련성에 따라 평가하고 정렬하는 과정을 의미한다.
- RAG에서는 여러 유형의 re-ranking 기법이 사용된다:
- Lexical Re-Ranking: 쿼리와 검색된 문서 간의 어휘적 유사성에 기반해 재정렬하는 방식으로, BM25, TF-IDF 벡터, 코사인 유사도 같은 방법이 일반적으로 사용된다.
- Semantic Re-Ranking: semantic한 이해를 통해 문서의 관련성을 판단하는 방식이다. BERT와 같은 신경망 모델이나 다른 transformer 기반 모델을 사용해 단순 단어 기반이 아닌 맥락과 의미를 이해하는데 중점을 둔다.
- Learning-to-Rank (LTR) Methods: 문서의 ranking을 위한 모델을 훈련하는 방법으로, 쿼리와 문서 모두에서 추출한 feature를 바탕으로 문서의 rank를 매긴다. 이 feature에는 어휘적, 의미적 등등의 특징이 있을 수 있다. LTR 방법에는 point-wise, pair-wise, list-wise가 포함된다.
- Hybrid Methods: Lexical과 Semantic 접근법을 결합하거나, user feedback이나 도메인 specific features같은 것을 추가하여 성능을 개선한다.
- Re-ranking 단계에서는 후보 집합이 수십 개로 제한되므로 주로 신경망 기반 LTR 기법이 사용된다. Re-ranking에 일반적으로 사용되는 신경망 모델을 다음이 있다:
- Multi-Stage Document Ranking with BERT (monoBert and duoBERT)
- Pretrained Transformers for Text Ranking BERT and Beyond
- ListT5
- ListBERT
Response Generation / Synthesis
- RAG pipeline의 마지막 단계는 사용자에게 response를 생성하는 것이다. 이 단계에서는 모델이 검색된 정보와 사전 학습된 지식을 통합하여 일관되고 맥락적으로 관련성 있는 응답을 생성한다.
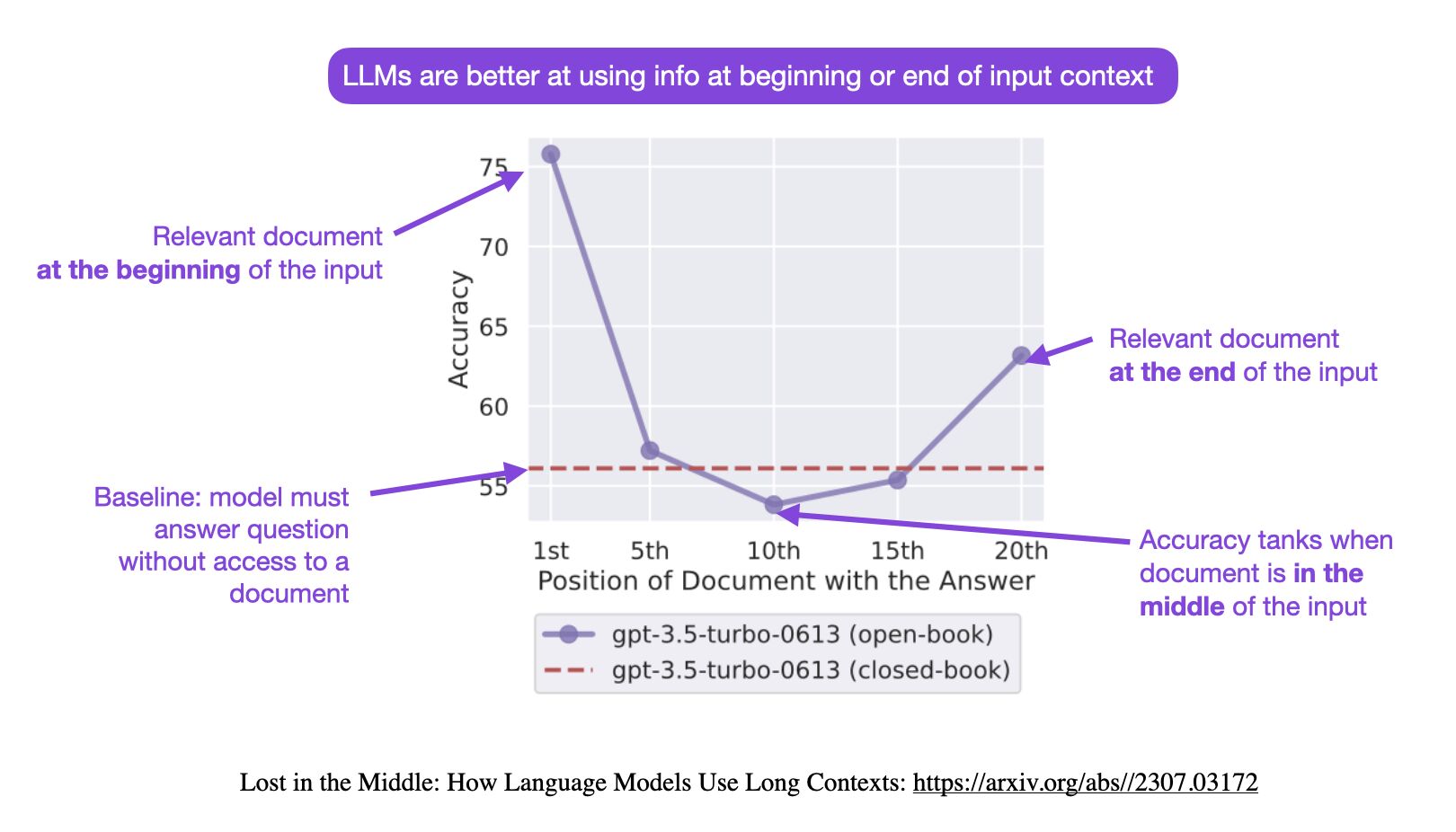
- LLM이 정보에 근거한 response를 생성할 수 있도록 retrieved된 top-k chunks를 사용해 확장된 프롬포트를 작성할 때, 입력 시퀀스의 시작이나 끝에 중요한 정보를 전략적으로 배치하는 것이 RAG 시스템의 효율성을 높이고 성능을 높일 수 있다.
[Paper] Lost in the Middle: How Language Models Use Long Contexts
- 최근의 LM은 긴 context를 입력으로 사용할 수 있지만, 이 긴 문맥을 얼마나 잘 사용하는지에 대해서는 상대적으로 알려진 바가 적다.
- 해당 논문은 LM이 입력된 context 내에서 관련 정보를 식별하는 두 가지 task에서의 성능을 분석한다. (Multi-document QA, key-value retrieval)
- Open-source 모델 (MPT-30B-Instruct, LongChat-13B)과 Closed-source 모델 (OpenAI’s GPT-3.5-Turbo and Anthropic’s Claude 1.3)로 실험을 진행했다.
- Context 속에 여러 개의 검색된 문서와 하나의 정답을 포함시키고, 그 위치를 섞어 multi-document QA를 수행했다. 또한, 더 긴 context가 성능에 미치는 영향을 분석하기 위해 key-value pair retrieval을 수행했다.
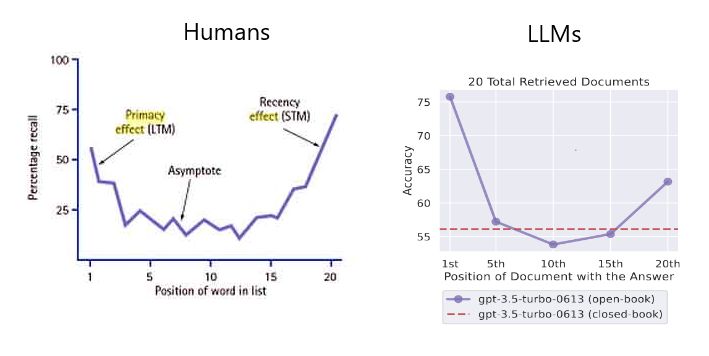
- 연구진은 관련 정보가 input context의 시작이나 끝에 있을 때 성능이 가장 높고, 모델이 긴 context의 중간에 있는 관련 정보에 접근해야 할 때 성능이 크게 낮아진다는 사실을 발견했다.
- 연구의 주요 결과는 다음과 같다:
- 관련 정보가 context의 시작에 있을 때 성능이 가장 좋다.
- context의 길이가 길어질수록 성능이 저하된다.
- 너무 많은 문서가 retreived되면 성능이 저하된다.
- Ranking 단계를 통해 retrieval과 프롬포트 생성 단계를 개선하면 성능이 20%까지 향상될 수 있다.
- 프롬프트가 original context에 잘 맞추어져 있다면, 확장된 context 모델들 (GPT-3.5-Turbo vs. GPT-3.5-Turbo (16K))이 더 나은 성능을 보여주지는 않는다.
- RAG는 외부 DB에서 정보를 검색하며, 이 DB는 일반적으로 chunk로 나뉘어진 긴 텍스트를 포함한다. chunk로 나누더라도 context window는 매우 빠르게 커지며, 적어도 ‘일반적인’ 질문보다 휠씬 더 커진다. 또한 input context가 길어질수록 성능은 상당히 감소하며, 이는 긴 context를 명시적으로 처리하는 모델도 마찬가지다.
- LLM 아키텍처에서 문서 중간에 있는 텍스트의 검색 성능이 더 나빠야하는 귀납적 편향은 없다. 이는 훈련 데이터와 인간이 글을 작성하는 방식 때문이라고 생각한다. 가장 중요한 정보는 보통 시작이나 끝에 위치해 있다. LLM이 훈련 중에 attention weight를 parameterize하는 방식도 이와 관련이 있을 것이다.(source)
- 인간이 직면하는 두 가지 대표적인 인지 편향(primacy & recency bias)을 통해 모델링할 수 있다.
- 결론적으로, 추천 시스템에서와 같이 retrieval과 ranking을 결합하면 QA에서의 RAG의 최고성능을 얻을 수 있다.
- 아래 이미지는 ‘LLM은 input context의 처음이나 끝 정보를 사용하는데 탁월하다’라는 idea를 나타낸다.
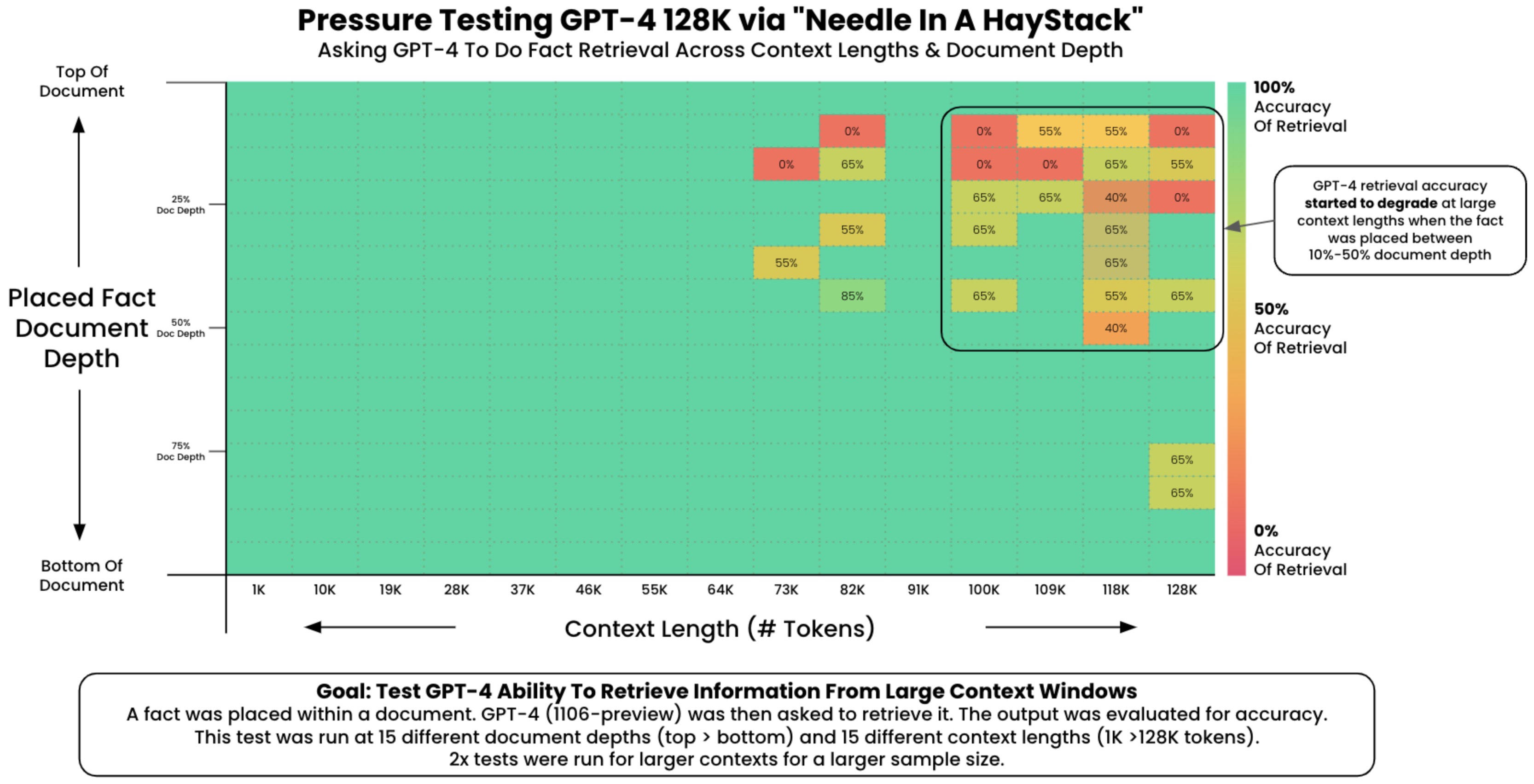
The “Needle in a Haystack” Test
- 긴 context를 가진 LLM의 context 내의 retrieval ability를 이해하기 위해, ‘needle in a haystack(건초더미 속 바늘)’ analysis를 수행할 수 있다. 이는 특정한 목표 정보(바늘)를 더 크고 복잡한 텍스트 본문(건초더미) 안에 임베딩하는 것을 포함한다. 이러한 분석의 목적은 방대한 양의 다른 데이터 속에서 특정한 정보를 식별하고 활용할 수 있는 LLM의 능력을 테스트 하는 데 있다.
- 이 실험은 LLM 성능의 여러 측면을 평가하도록 구조화될 수 있다. 예를 들어, ‘바늘’의 위치를 텍스트의 초반, 중간, 후반으로 다양하게 배치하여 정보의 위치에 따라 모델의 retrieval 성능이 어떻게 변하는지 확인할 수 있다. 또한 주변 ‘건초더미’의 복잡성을 조정하여, 다양한 contextual 난이도 하에서 LLM의 성능을 테스트할 수 있다.
- 아래 그림들은 GPT-4 128K 모델과 Claude-2.1 200K가 다양한 context 길이에 따라 수행한 성능을 나타낸다.

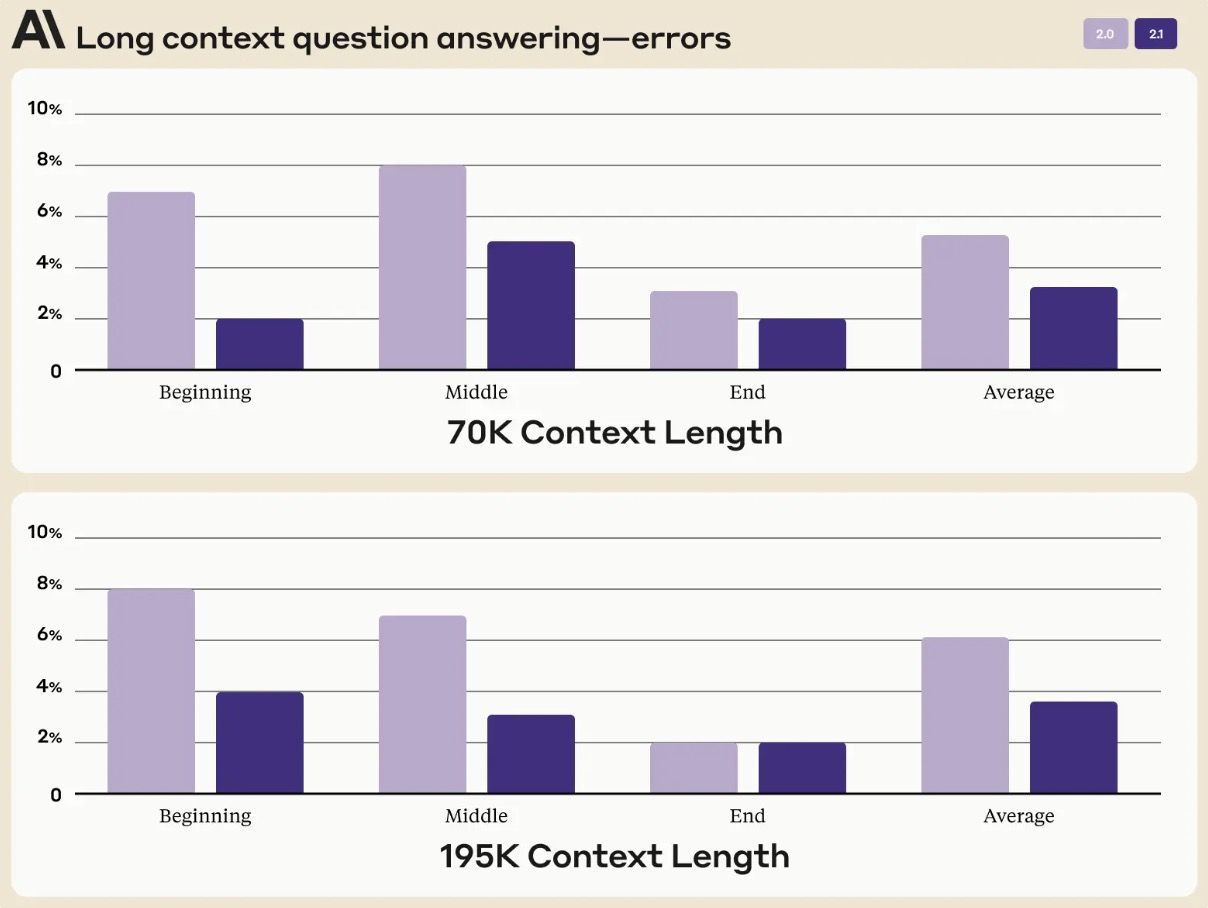
- 아래 figure는 Claude 2.1의 long context QA 오류를 context 길이 별로 나타낸 것이다. 평균적으로 Claude 2.1은 Claude 2와 비교하여 오답이 30% 감소한 것으로 나타났다.
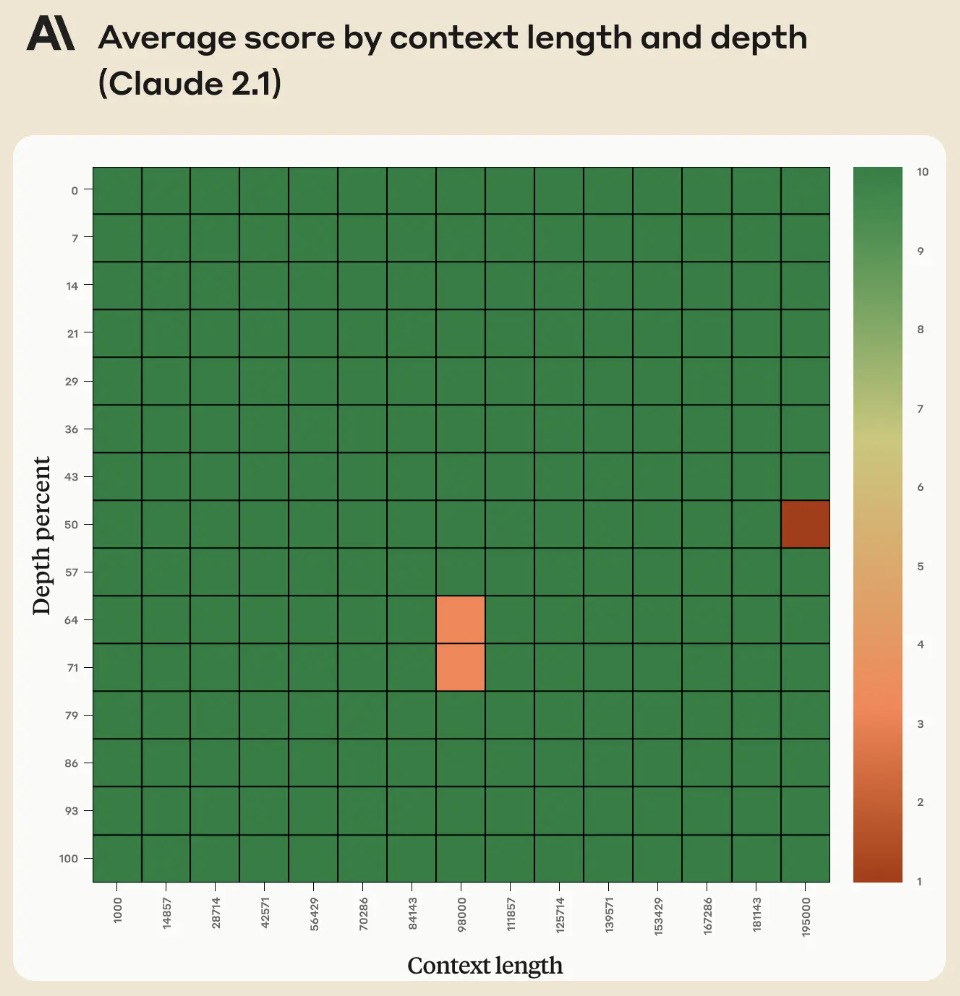
- 그러나, Anthropic 블로그의 Long context prompting for Claude 2.1 글에 따르면, response 시작 부분에 ‘Here is the most relevant sentence in the context.(여기 context에서 가장 관련성이 높은 문장입니다)” 라는 문구를 추가했을 때, 원래 평가에서 점수가 27%에서 98%로 상승했다고 언급했다. 아래의 figure는 Claude 2.1이 전체 200K 토큰의 context window에서 개별 문장을 retrieving 할 때의 성능을 보여준다. 이 실험은 위에서 언급한 프롬프트 기법을 사용한다.
Component-Wise Evaluation
- Component-wise evaluation(구성 요소별 평가)은 LLM 시스템에서 개별 구성 요소들을 각각 평가하는 것을 의미한다. 이 접근 방식은 일반적으로 데이터베이스나 코퍼스에서 관련 정보를 가져오는 retrieval component와, 검색된 데이터를 기반으로 response를 생성하는 generation component의 성능을 검토한다. 이러한 컴포넌트들을 개별적으로 평가함으로써 전체 RAG 시스템에서 개선이 필요한 특정 영역을 식별할 수 있으며, 이는 정보 검색과 응답 생성의 효율성과 정확성을 높이는 데 기여한다.
- Retrieval의 성능을 평가하는 데에는 Context Precision, Context Recall, Context Relevance와 같은 지표가 사용되며, Generation의 품질을 평가하기 위해서는 Groundedness와 Answer Relevance 지표가 사용된다.
- 구체적으로,
- Retrieval 평가 지표: Context Precision은 시스템이 관련 항목을 얼마나 높은 순위에 배치하는지를 평가하고, Context Recall은 시스템이 관련된 모든 맥락을 얼마나 잘 검색하는지를 측정한다. Context Relevance는 검색된 정보가 user query와 얼마나 일치하는지 평가한다. 이러한 지표들은 retrieval 시스템이 정확한 response를 생성하기 위해 가장 관련있고 complete한 context를 제공하는지 보장하는지 평가한다.
- Generation 평가 지표: Faithfullness와 Answer Relevance는 생성된 응답의 사실적 일관성과, 응답이 원래 질문과 얼마나 관련이 있는지를 평가한다. Faithfulness는 응답의 사실적 정확성에 중점을 두며, 모든 주장들이 주어진 맥락에서 추론될 수 있는지를 확인한다. Answer Relevance는 응답이 원래 질문을 얼마나 잘 다루고 있는지를 평가하며, 불완전하거나 중복된 응답에 대해 페널티를 부여한다. 이런 지표들은 generation component가 맥락적으로 적절하고 의미적으로 관련된 응답을 생성하도록 평가한다.
- 4개 점수(Context Precicion, Context Recall, Faithfulness, Answer Relevancy)의 조화 평균(harmonic mean)은 RAGAS score라고 불리며, RAG 시스템의 전반적인 성능을 중요한 모든 측면에서 단일 지표로 측정한 것이다.
- 대부분의 측정은 라벨 데이터가 필요하지 않기 때문에, 테스트 데이터셋을 구축할 필요 없이 수행할 수 있다. RAGAS를 측정하기 위해 필요한 것은 몇 가지 질문과, Context Recall을 사용할 경우 reference answer 뿐이다.
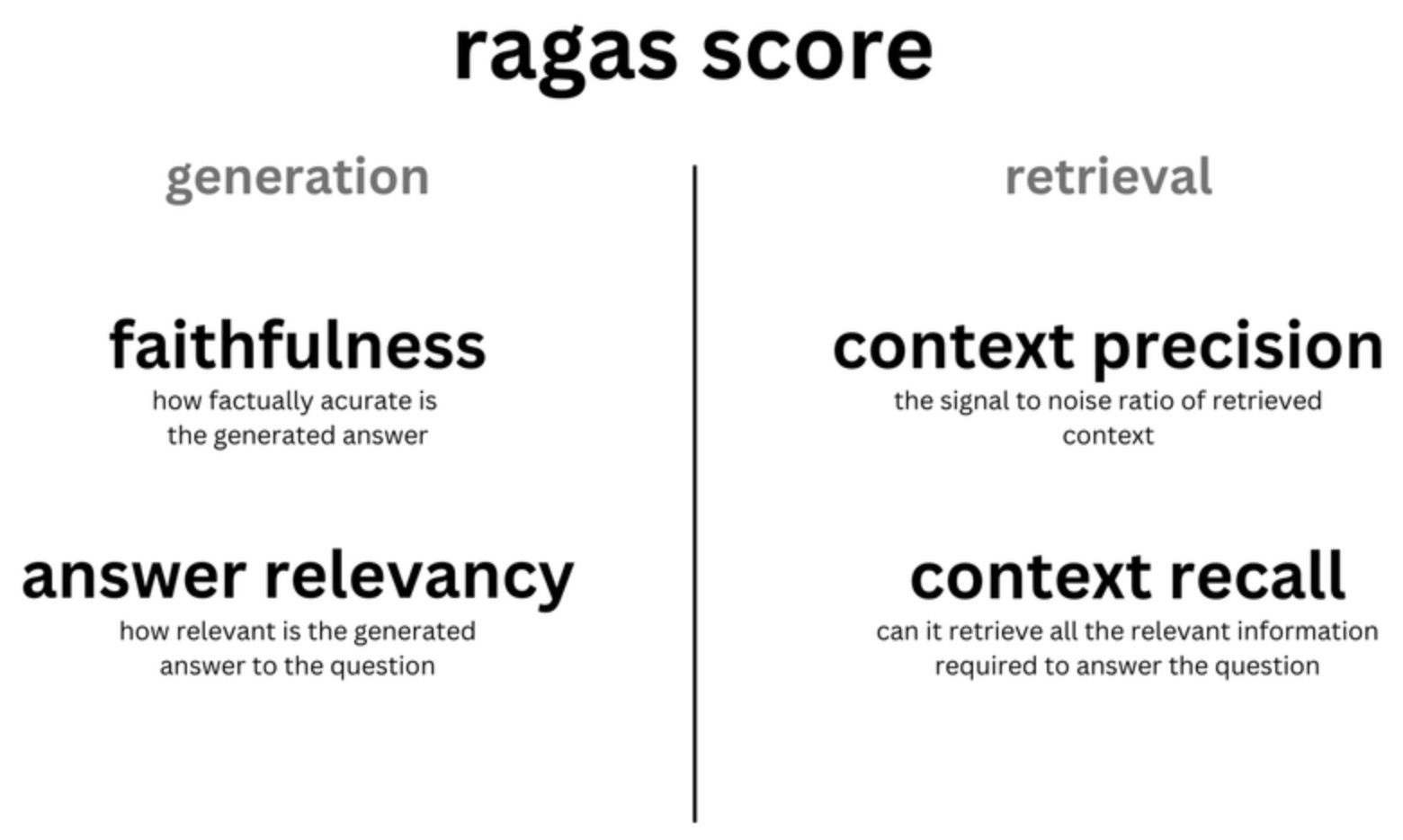
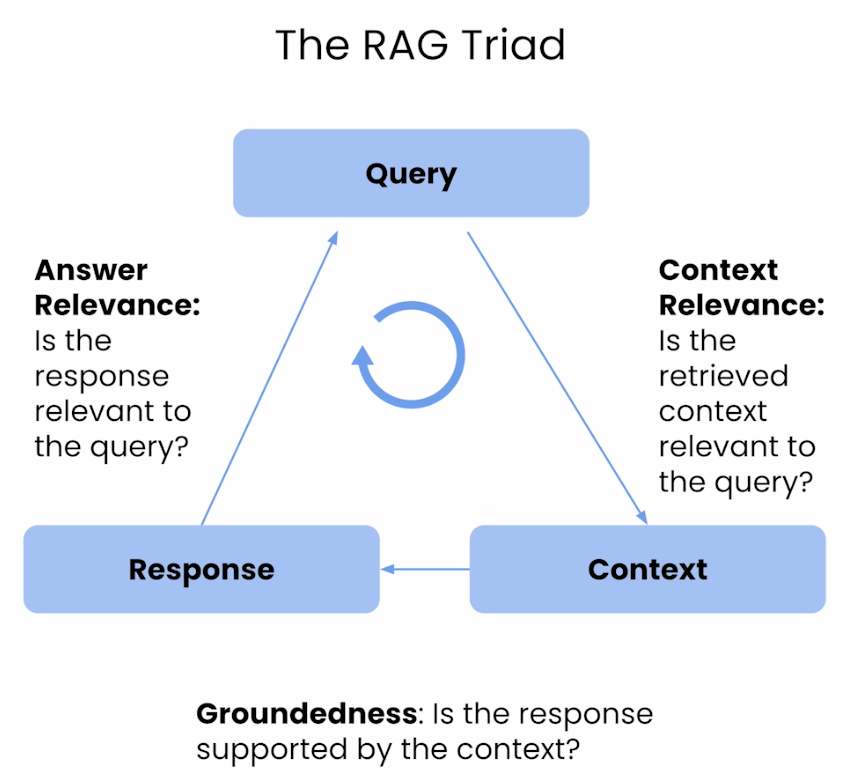
- Groundedness = Faithfulness
Improving RAG Systems
- RAG 시스템의 성능을 개선하기 위해, 아래 세 가지 구조화된 방법을 고려할 수 있다.
- Re-ranking Retrieved results: 기본적이면서도 효과적인 방법으로, 초기 검색을 통해 얻어진 결과를 refine 하기 위해 re-ranking 모델을 사용하는 것이 있다. 이 방식은 더 관련성이 높은 결과에 우선순위를 두어, 생성된 결과의 전반적 퀄리티를 향상시킨다. MonoT5, MonoBERT, DuoBERT 등이 re-ranking 모델로 사용될 수 있다.
- FLARE 기법: re-ranking 이후에는 FLARE를 사용할 수 있다. FLARE는 생성된 content의 일부 구간의 신뢰 수준이 특정 임계값 이하로 떨어질 때마다 인터넷(또는 local knowledge base)를 동적으로 조회한다. 이는 일반 RAG가 knowledge base를 초기에만 조회한 뒤 최종 출력을 생성하는 한계를 극복한다.
- HyDE 기법: HyDE 기법은 쿼리에 응답하기 위해 가상의 문서를 생성하는 개념을 도입한다. 이 문서는 임베딩 벡터로 변환된 후, vector similarity를 기반으로 corpus 임베딩 공간 내에서 유사한 인접 문서를 식별하는 데 사용된다. 이 방법의 독창성은 벡터를 사용해 유사한 실제 문서를 검색하는 데 있다.

Anyone can be anything ... with agent!