📒 요약 : 인덱스는 SELECT를 사용해서 테이블을 조회할 때 결과를 빠르게 추출하도록 도와주는 기능이다. 대용량의 데이터베이스에서는 데이터를 검색하는 데 시간이 오래 걸릴 수 있으므로 인덱스 기능을 활용하면 데이터를 효율적으로 검색할 수 있다. 인덱스에는 클러스터형 인덱스와 보조 인덱스가 있다.
인덱스 개념을 파악하자
1. 인덱스의 개념
인덱스는 데이터를 빠르게 찾을 수 있도록 도와주는 도구이다. 책의 마지막 부분에 있는 '찾아보기' 항목을 생각하면 쉽다. 찾고자 하는 항목을 찾아보기를 이용해서 빠르게 찾을 수 있지만, 찾아보기가 없다면 책의 첫 페이지부터 하나하나 찾아야 할 것이다. SQL에서도 마찬가지로, 인덱스가 없는 테이블에서는 특정 데이터를 찾기 위해 테이블의 처음부터 끝까지 모두 검색해야 하지만, 인덱스를 이용한다면 훨씬 빠르게 데이터를 검색할 수 있다. 이러한 효율성은 용량이 큰 데이터베이스일수록 그 차이가 두드러진다.
인덱스의 문제점
인덱스는 데이터를 효율적으로 찾을 수 있게 하지만, 문제점도 있다. 통상적으로 데이터베이스에서 인덱스를 생성하기 위해 전체의 10%정도의 용량에 해당되는 저장공간이 추가적으로 필요하다. 대용량의 데이터베이스에서 찾아볼 필요가 없는 인덱스를 생성할 경우 저장 공간이 지나치게 많이 필요하게 되는 문제점이 발생할 수 있다.
인덱스의 장점과 단점
인덱스는 SELECT에서 즉각적인 효과를 내는 빠른 방법 중 한가지다. 적절한 인덱스를 생성하고 인덱스를 사용하는 SQL을 만든다면 아주 빠른 은답 속도를 얻을 수 있다. 결과적으로는 시스템 전체의 성능도 향상되는 효과를 가져올 수 있다. 반면 인덱스가 가지는 단점도 있다. 아래에 인덱스의 장점과 단점을 정리해두었다.
인덱스의 장점
- SELECT문으로 검색하는 속도가 매우 빨라진다.
- 그 결과 컴퓨터의 부담이 줄어들어 결국 전체 시스템의 성능이 향상된다.
인덱스의 단점
- 인덱스도 공간을 차지해서 데이터베이스 안에 추가적인 공간이 필요하다.
- 처음에 인덱스를 만드는 데 시간이 오래 걸릴 수 있다.
- SELECT가 아닌 데이터의 변경 작업(INSERT, UPDATE, DELETE)이 자주 일어나면 오히려 성능이 나빠질 수 있다.
2. 인덱스의 종류
MySQL에서 사용되는 인데긋의 종류는 크게 두 가지로 나뉜다. 바로 클러스터형 인덱스와 보조 인덱스이다. 클러스터형 인덱스는 사전처럼 데이터가 알파벳 순서대로 정렬되어 있고, 보조 인덱스는 일반 책의 찾아보기처럼, 해당 내용을 찾은 후 대응되는 위치를 찾아야 한다.
자동으로 생성되는 인덱스
인덱스는 테이블의 열 단위에 생성되며, 하나의 열에는 하나의 인덱스를 생성할 수 있다. 물론 하나의 열에 여러 개의 인덱스를 생성할 수도 있긴 하지만, 이는 거의 사용되지 않는 경우이다. market_db의 member 테이블을 예로 인덱스를 살펴보자.
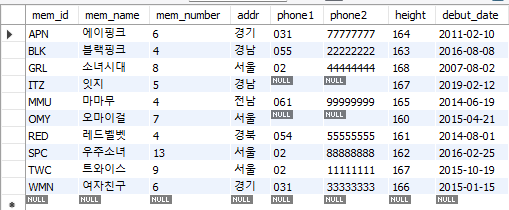
해당 테이블에서 열 하나당 인덱스 하나를 생성하면 이 테이블에는 8개의 서로 다른 인덱스를 생성할 수 있다. 위의 테이블에는 mem_id가 PK로 지정되어 있는데, 이렇게 기본 키로 지정된 열에는 자동으로 클러스터형 인덱스가 생성된다. 기본 키는 테이블 당 하나만 지정할 수 있는데, 이는 결국 클러스터형 인덱스는 하나의 테이블에 한 개만 만들 수 있다는 것을 의미한다.
SHOW INDEX FROM 테이블이름;위와 같은 SQL문을 실행하여 테이블의 인덱스 정보를 확인할 수 있다.

먼저 Key_name 부분을 보면 PRIMARY라고 적혀있는데, 이는 기본 키로 설정해서 자동으로 생성된 인덱스라는 의미이다. 이것이 클러스터형 인덱스이다. 다음으로, Column_name이 mem_id로 적혀있는데, 이는 mem_id 열에 인덱스가 생성되었다는 의미이다. 마지막으로 Non_Unique는 고유하지 않다는 것으로, 인덱스의 중복을 허용하는 지 여부를 나타낸다. 고유 인덱스는 인덱스의 값이 중복되지 않는다는 의미이고, 단순 인덱스는 인덱스의 값이 중복되어도 된다는 의미이다.
기본 키(PK)뿐만 아니라 고유 키(Unique)도 인덱스가 자동으로 생성되는데, 고유 키로 생성되는 인덱스는 보조 인덱스이다. 고유 키로 생성된 인덱스는 중복을 허용하지 않으며, 테이블 당 여러개를 만들 수 있다.
자동으로 정렬되는 클러스터형 인덱스
위의 내용에서 클러스터형 인덱스는 기본 키를 지정하면 해당 열에 자동으로 생성된다는 것을 확인했다. 이번에는 클러스터형 인덱스의 특징을 살펴보자.
일반적으로 테이블에 데이터를 입력하면 해당 테이블을 SELECT문으로 조회했을 때 데이터를 입력한 순서대로 출력된다. 그러나 위의 그림1처럼 인덱스를 사용하면 PK로 설정된 mem_id를 기준으로 알파벳 순서대로 정렬되어 출력되는 것을 확인할 수 있다. 이렇게 클러스터형 인덱스는 인덱스가 생성될 때 자동으로 알파벳 순서대로 정렬된다. 이는 영어 뿐만 아니라 한글에도 적용된다. 만약 테이블에 추가로 데이터를 입력하면 자동으로 기준에 맞춰서 정렬된다.
정렬되지 않는 보조 인덱스
앞서 이야기했듯 고유 키로 지정하면 보조 인덱스가 생성된다. 그리고 보조 인덱스는 하나의 테이블에 여러 개를 설정할 수 있다. 보조 인덱스는 생성할 때 데이터가 자동으로 정렬되지 않는다. 일반적으로 데이터를 입력한 순서대로 출력되듯, 보조 인덱스 역시 데이터를 입력한 순서대로 출력된다. 만약 데이터를 추가로 입력할 경우 해당 테이블의 가장 뒤에 추가된다. 보조 인덱스는 여러 개를 만들 수 있지만, 보조 인덱스를 만들 때마다 데이터베이스의 공간을 차지하게 되고, 전반적으로 시스템에 오히려 나쁜 영향을 미친다. 그러므로 꼭 필요한 경우에만 보조 인덱스를 만들어 주도록 하자.
