📒 요약 : MySQL의 실행 계획에서 인덱스를 효율적으로 사용할 수 있다. 기본적으로는 CREATE INDEX문과 DROP INDEX문을 사용하여 인덱스를 생성하고 제거할 수 있다.
인덱스의 실제 사용
CREATE INDEX문과 DROP INDEX문을 사용하여 인덱스를 생성하고 제거할 수 있다. 아래와 같이 사용하면 된다.
#인덱스 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC|DESC]
#인덱스 제거
DROP INDEX 인덱스_이름 ON 테이블_이름1. 인덱스의 내부 작동 원리
인덱스 생성과 제거에 대한 정확한 문법을 이해하고 활용하는 방법에 대해 알아보자.
인덱스 생성 문법
테이블을 생성할 때 특정 열을 기본 키, 고유 키로 설정하면 인덱스가 자동으로 만들어진다. 그 외에 만약 사용자가 인덱스를 직접 선택하고 싶을 때에는 CREATE INDEX문을 이용해야 한다. 앞서 간단하게 인덱스를 생성할 수 있는 문법을 살펴봤지만, 옵션과 타입 등 세부적으로 인덱스를 생성할 수 있는 문법을 아래와 같다.
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX index_mem_name
[index_type]
ON tbl_mem_name (key_part, ...)
[index_option]
[algorithm_option | lock_option] ...
key_part: {col_mem_name [(length)] |(expr)} [ASC | DESC]
index_option:
KEY_BLOCK_SIZE [=]value
| index_type
| WITH PARSER parser_mem_name
| COMMENT 'string'
| {VISIBLE | INVISIBLE}
index_type:
USING {BTREE | HASH}
algorithm_option:
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option :
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}뭐가 많아 보이는데, 실제로는 위에서 언급했던 두 줄 짜리 인덱스를 생성하는 문장을 자주 사용한다. UNIQUE는 중복이 안 되는 고유 인덱스를 만드는 것인데, 생략하면 중복이 허용된다. CREATE UNIQUE로 인덱스를 생성하려면 기존에 입력된 값들에 중복이 있으면 안 된다. 그리고 인덱스를 생성한 후에 입력되는 데이터와도 중복될 수 없다.
ASC, DESC 옵션은 인덱스를 정렬하는 옵션이다. ASC이 기본 옵션으로, 오름차순으로 정렬하는 것이다.
인덱스 제거 문법
CREATE INDEX문으로 생성한 인덱스는 다음과 같이 DROP INDEX문으로 제거할 수 있다.
DROP INDEX 인덱스_이름 ON 테이블_이름주의한 점은 기본 키, 고유 키로 자동으로 생성된 인덱스는 DROP INDEX문으로 제거하지 못한다는 것이다. ALTER TABLE 문으로 기본 키나 고유 키를 제거하면 이렇게 자동으로 생성된 인덱스도 제거할 수 있음을 알아두자. 그리고 하나의 테이블에 클러스터형 인덱스와 보조 인덱스가 모두 있는 경우, 인덱스를 제거할 때에는 보조 인덱스부터 제거하는 것이 좋다.
2. 인덱스 생성과 제거 실습
인덱스 생성 실습
이번 인덱스를 다루는 실습에서는 market_db 데이터베이스에 있던 member 테이블을 사용할 것이다.
USE market_db;
SELECT * FROM member;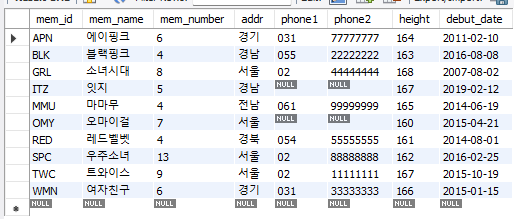
SHOW INDEX문으로 member 테이블에 어떤 인덱스가 설정되어 있는지 확인해 보자. 이 테이블에는 mem_id 열이 PK로 지정되어 있으므로 클러스터형 인덱스 1개가 설정되어 있다.
ALTER TABLE cluster
ADD CONSTRAINT
PRIMARY KEY (mem_id);
SELECT * FROM cluster;
이번에는 인덱스의 크기를 확인해 보자. SHOW TABLE STATUS 문을 이용하면 된다. 결과 중에 Data_length는 클러스터형 인덱스의 크기를 Byte 단위로 표기한 것이다. 클러스터형 인덱스에는 1페이지 당 15KB가 할당되어 있다는 것을 확인할 수 있다. index_length는 보조 인덱스의 크기인데, member 테이블에는 보조 인덱스가 없기 대문에 표기되지 않는다.

member 테이블에는 이미 클러스터형 인덱스가 있으므로 이 테이블에는 더 이상 클러스터형 인덱스를 생성할 수 없다. 대신 addr 열에 중복을 허용하는 단순 보조 인댁스를 생성해보자. 인덱스 이름은 idx_member_addr로 지정하였다. 그 뒤 인덱스를 확인해 보면 조금 전에 추가한 인덱스가 새로 들어온 것을 확인할 수 있다.
CREATE INDEX idx_member_addr
ON member (addr);
여기서 주의할 점은 Non_Unique가 1로 설정되어 있으므로 고유 보조 인덱스가 아니라는 것이다. 즉, 해당 인덱스는 중복된 데이터를 허용한다. 이렇게 추가한 보조 인덱스를 실제로 테이블에 적용시키려면 ANALYZE TABLE문으로 먼저 테이블을 분석/처리해주어야 한다.
ANALYZE TABLE member;이번에는 mem_number에 중복을 허용하지 않는 고유 보조 인덱스를 생성해보자. 블랙핑크, 마마무, 레드벨벳의 인원수가 4이므로 이미 중복된 값이 있다. 따라서 인원수 열에는 고유 보조 인덱스를 생성할 수 없다. 대신 mem_name에 고유 보조 인덱스를 생성할 수 있다. 이렇게 고유 보조 인덱스가 추가된 열에는 새로 데이터를 입력할 때 중복된 값을 입력할 수 없다.
CREATE UNIQUE INDEX idx_member_mem_number
ON member (mem_number); -- 오류 발생, 중복된 데이터가 있기 때문
CREATE UNIQUE INDEX idx_member_mem_name
ON member (mem_name);
SHOW INDEX FROM member;
인덱스의 활용 실습
생성한 인덱스를 활용해 보자. 지금까지 SELECT를 사용해서 인덱스가 있으면 인덱스를 통해서 결과를 출력하고, 인덱스가 없으면 전체 테이블을 찾아서 결과를 출력했다. 일반 사용자 입장에서는 결과의 차이는 없다. 단지 결과를 빠르게 보느냐, 느리게 보느냐의 차이가 있다.
인덱스를 사용하려면 아래와 같이 인덱스가 생성된 열 이름이 SQL 문에 있어야 한다. 그런데 WHERE 절에 열 이름이 들어있어야 인덱스를 사용할 수 있다.
#인덱스를 사용하지 않고 조회하는 경우
SELECT mem_id, mem_name, addr FROM member;
#인덱스를 사용하여 데이터를 조회하는 경우
SELECT mem_id, mem_name, addr
FROM member
WHERE mem_name = '에이핑크';
#숫자의 범위로 검색하고 인덱스를 사용하여 데이터를 조회하는 경우
SELECT mem_name, mem_number
FROM member
WHERE mem_number >= 7; 인덱스를 사용하지 않을 때
인덱스가 있고 WHERE 절에 열 이름이 나와도 인덱스를 사용하지 않는 경우가 있긴 하다. MySQL이 자체적으로 인덱스 검색보다는 전체 테이블 검색이 더 효율적으로 검색할 수 있을 거라고 판단하는 경우에는 테이블의 전체 데이터를 검색하기도 한다. 또한 WHERE 절에서 열에 연산이 가해지면 인덱스를 사용하지 않는다. 그러므로 인덱스를 사용하고 싶다면 WEHRE 절에 나온 열에는 아무 연산도 하지 말자.
#WHERE 절에 연산이 들어가 인덱스를 사용하지 않고 테이블을 조회하는 경우
SELECT mem_name, mem_number
FROM member
WHERE mem_number >= 14/2; 인덱스 제거 실습
지금까지 사용한 인덱스를 제거하는 방법은 아주 간단하다. 앞서 봤던 DROP INDEX문을 이용하면 된다. 단, 클러스터형 인덱스와 보조 인덱스가 함께 있을 때에는 보조 인덱스를 먼저 제거해주자. 보조 인덱스가 여러 개일 때에는 어떤 것을 먼저 제거해도 상관 없다.
#보조 인덱스 제거하기
DROP INDEX idx_member_mem_name ON member;
DROP INDEX idx_member_addr ON member;
DROP INDEX idx_member_mem_number ON member;클러스터형 인덱스를 제거할 때에는 DROP INDEX문을 사용하지 않는다. 대신 테이블에 걸었던 PK 제약조건을 ALTER 문으로 해제하여 인덱스까지 함께 제거할 수 있다.
ALTER TABLE member
DROP PRIMARY KEY;단 이 때 만약 해당 PK를 참조하고 있는 FK가 있다면 인덱스를 제거하기 전에 해당 기본 키-외래 키 관계부터 해제해야 한다.
3. 인덱스를 효과적으로 사용하는 방법
인덱스를 효과적으로 사용하기 위해 몇 가지 기억해야 할 내용들을 대해 정리해보자.
- 인덱스는 열 단위에 생성된다.
- WHERE 절에서 사용되는 열에 인덱스를 만들어야 한다.
- WEHRE 절에 사용되더라도 자주 사용해야 가치가 있다.
- 데이터의 중복이 높은 열은 인덱스를 만들어도 별 효과가 없다.
- 클러스터형 인덱스는 테이블 당 하나만 생성할 수 있다.
- 사용하지 않는 인덱스는 제거하자.
