
Chapter 1. Overview of HTTP
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
❤️ 원문 번역 ❤️
Architectural Components of the Web
In this overview chapter, we’ve focused on how two web applications (web browsers and web servers) send messages back and forth to implement basic transactions. There are many other web applications that you interact with on the Internet. In this section, we’ll outline several other important applications, including:
-> 이번 Overview 챕터에서는 기본적인 트랜잭션을 구현하기 위해 두 웹 애플리케이션(웹 브라우저와 웹 서버)이 메시지를 주고받는 방법에 초점을 맞추었습니다.
-> 여러분이 인터넷에서 상호작용할 서로 다른 웹 애플리케이션들이 있습니다.
-> 이번 섹션에서는 다음을 포함한 몇 가지 중요한 애플리케이션에 대해 살펴볼 겁니다.
Proxies
HTTP intermediaries that sit between clients and serversCaches
HTTP storehouses that keep copies of popular web pages close to clientsGateways
Special web servers that connect to other applicationsTunnels
Special proxies that blindly forward HTTP communicationsAgents
Semi-intelligent web clients that make automated HTTP requests
- Proxies : 클라이언트와 서버 사이에 위치한 HTTP 매개체
- Caches : 인기 있는 웹 페이지의 사본을 클라이언트와 가까운 위치에 두는 HTTP 저장소
- Gateways : 다른 애플리케이션을 연결하는 특별한 웹 서버
- Tunnels : HTTP 통신을 맹목적으로 전달하는 특수한 프록시
- Agents : HTTP Request를 자동화한 반지능적 웹 클라이언트
Proxies
Let’s start by looking at HTTP proxy servers, important building blocks for web security, application integration, and performance optimization.
-> HTTP 웹 보안과 앱 통합, 성능 최적화 측면에서 중요한 요소인 프록시 서버를 살펴봅시다.
As shown in Figure 1-11, a proxy sits between a client and a server, receiving all of the client’s HTTP requests and relaying the requests to the server (perhaps after modifying the requests). These applications act as a proxy for the user, accessing the server on the user’s behalf.
-> Figure 1-11에 나타나듯 프록시는 클라이언트와 서버 사이에 위치하여 클라이언트의 모든 HTTP Request를 받고 서버에 전달합니다. 아마 프록시는 Request를 약간 수정하여 전달할 것입니다.
-> 이 애플리케이션은 유저 대신 서버에 접근하는 유저에 대한 프록시로써 동작합니다.
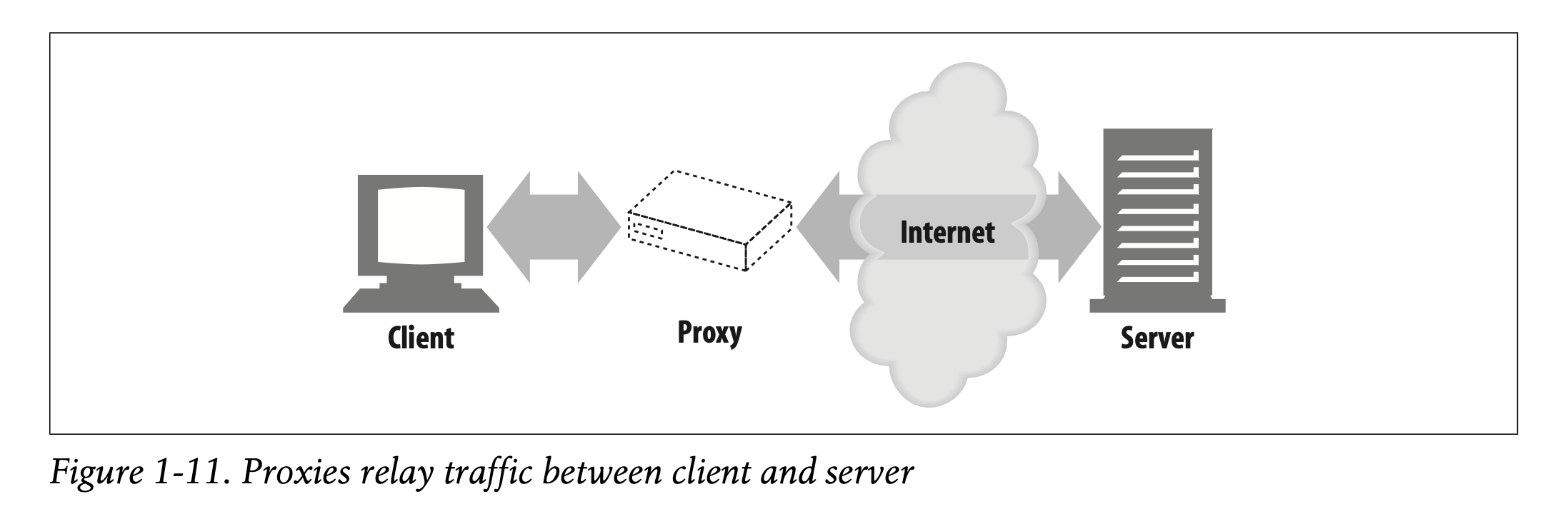
Proxies are often used for security, acting as trusted intermediaries through which all web traffic flows. Proxies can also filter requests and responses; for example, to detect application viruses in corporate downloads or to filter adult content away from elementary-school students. We’ll talk about proxies in detail in Chapter 6.
-> 프록시는 모든 웹 트래픽이 흘러가는 신뢰할 수 있는 매개체로 작동하여 보안에 주로 사용됩니다.
-> 프록시는 요청과 응답을 필터링할 수 있습니다. 예를 들어, 다운로드 과정에서 애플리케이션의 바이러스를 감지하거나 초등학생들에게 성인 콘텐츠를 필터링하는 역할을 합니다.
-> 프록시에 대해서는 Chapter 6에서 자세히 이야기할 예정입니다.
Caches
A web cache or caching proxy is a special type of HTTP proxy server that keeps copies of popular documents that pass through the proxy. The next client requesting the same document can be served from the cache’s personal copy (see Figure 1-12).
-> 웹 캐시 혹은 캐싱 프록시는 HTTP 프록시 서버의 특수한 유형입니다. 이는 프록시를 통과하는 인기 문서들의 사본을 보관하고 있습니다.
-> 동일한 문서를 요청하는 다음 클라이언트는 캐시의 개별적인 복사본을 전달받을 수 있습니다(Figure 1-12).
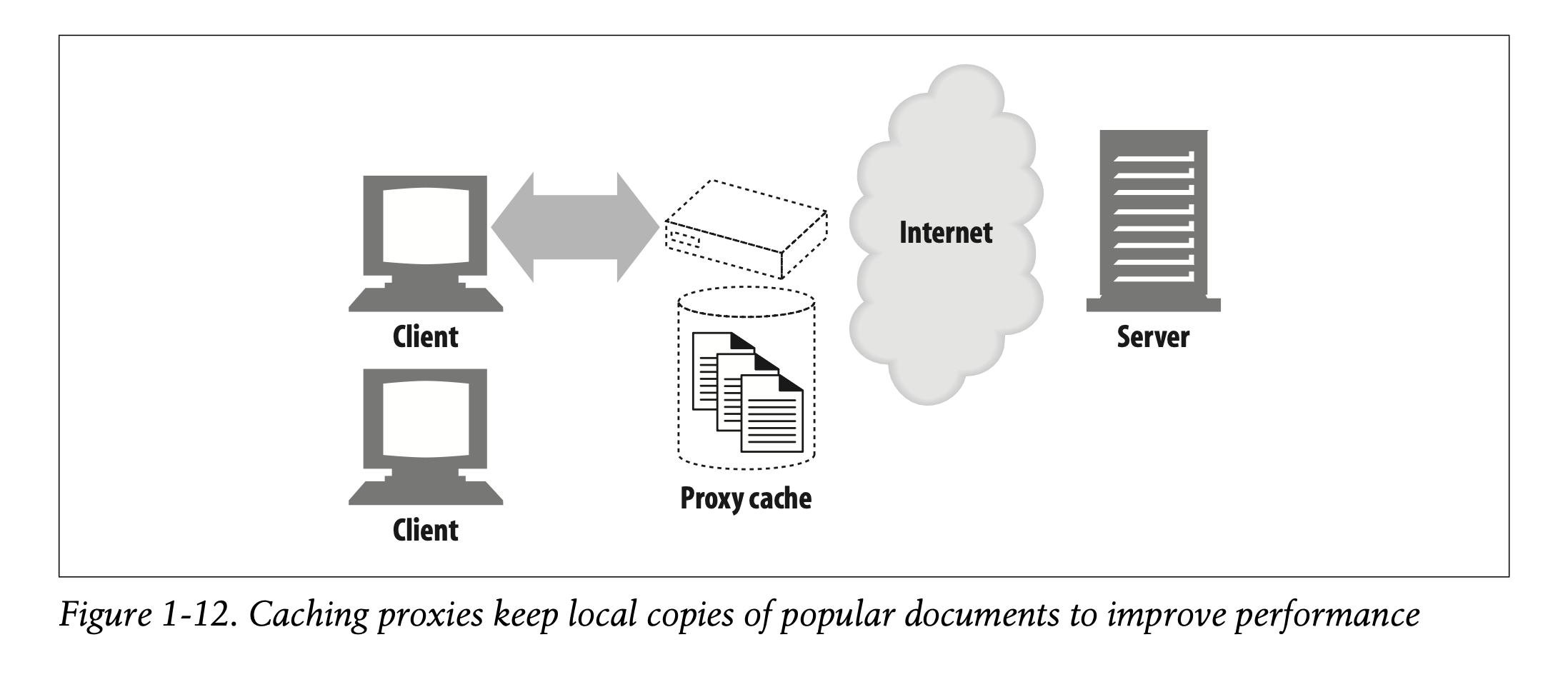
A client may be able to download a document much more quickly from a nearby cache than from a distant web server. HTTP defines many facilities to make caching more effective and to regulate the freshness and privacy of cached content. We cover caching technology in Chapter 7.
-> 클라이언트는 원격 웹 서버보다 가까이 위치한 캐시에서 훨씬 빠르게 문서를 다운로드할 수 있을 것입니다.
-> HTTP는 캐싱을 보다 효율적이게 하고 캐시된 콘텐츠의 유효기간과 보안을 규제하기 위해 많은 장치를 두고 있습니다.
-> 캐싱 기술에 대해서는 Chapter 7에서 다룹니다.
Gateways
Gateways are special servers that act as intermediaries for other servers. They are often used to convert HTTP traffic to another protocol. A gateway always receives requests as if it was the origin server for the resource. The client may not be aware it is communicating with a gateway.
-> 게이트웨이는 다른 서버들의 매개체로써 동작하는 특수 서버입니다.
-> HTTP 트래픽을 또다른 프로토콜로 변환하는 데 주로 사용됩니다.
-> 게이트웨이는 마치 자신이 리소스의 클라이언트가 접근하려 하는 원래 서버인 것처럼 요청을 받습니다.
-> 클라이언트는 자신이 게이트웨이와 통신하고 있다는 점을 알 수 없을지도 모릅니다.
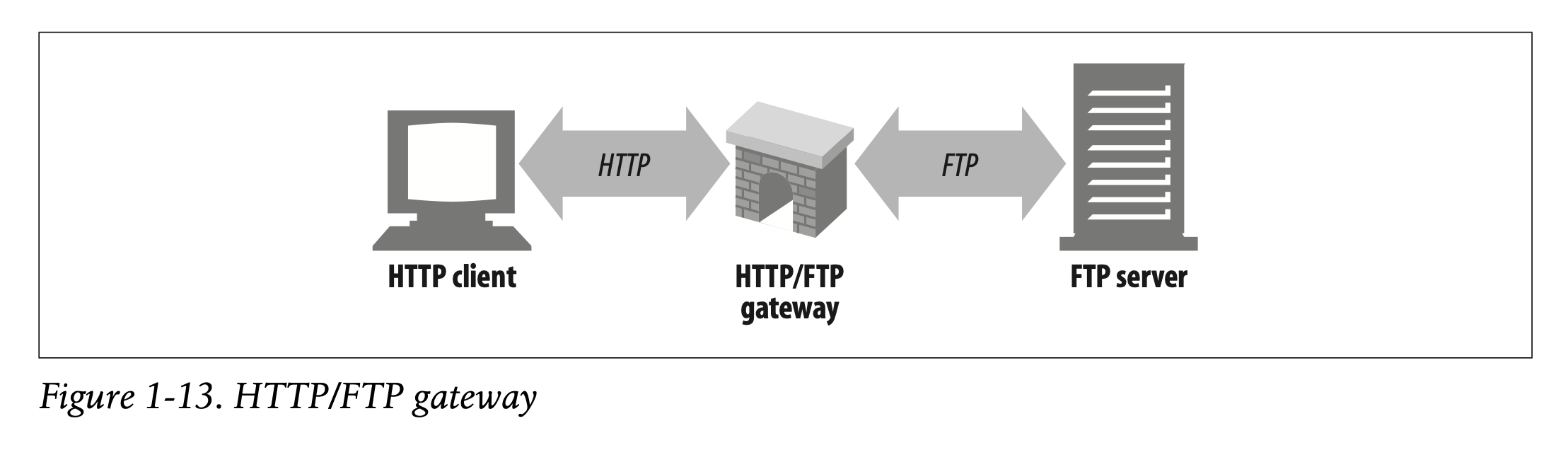
For example, an HTTP/FTP gateway receives requests for FTP URIs via HTTP requests but fetches the documents using the FTP protocol (see Figure 1-13). The resulting document is packed into an HTTP message and sent to the client. We discuss gateways in Chapter 8.
-> 예를 들어 HTTP/FTP 게이트웨이는 HTTP Request를 통해 FTP URI를 요청하지만 FTP 프로토콜을 통해 문서를 불러옵니다(Figure 1-13).
-> 결과물은 HTTP 메시지로 포장되여 클라이언트에 전송됩니다.
-> 게이트웨이에 대해서는 Chapter 8에서 이야기합니다.
Tunnels
Tunnels are HTTP applications that, after setup, blindly relay raw data between two connections. HTTP tunnels are often used to transport non-HTTP data over one or more HTTP connections, without looking at the data.
-> 터널은 설정 후 두 연결 사이에서 원시 데이터를 맹목적으로 전달하는 HTTP 애플리케이션입니다.
-> HTTP 터널은 데이터를 열람하지 않으면서 하나 이상의 HTTP 연결을 통해 HTTP가 아닌 데이터를 전송할 때 주로 사용됩니다.
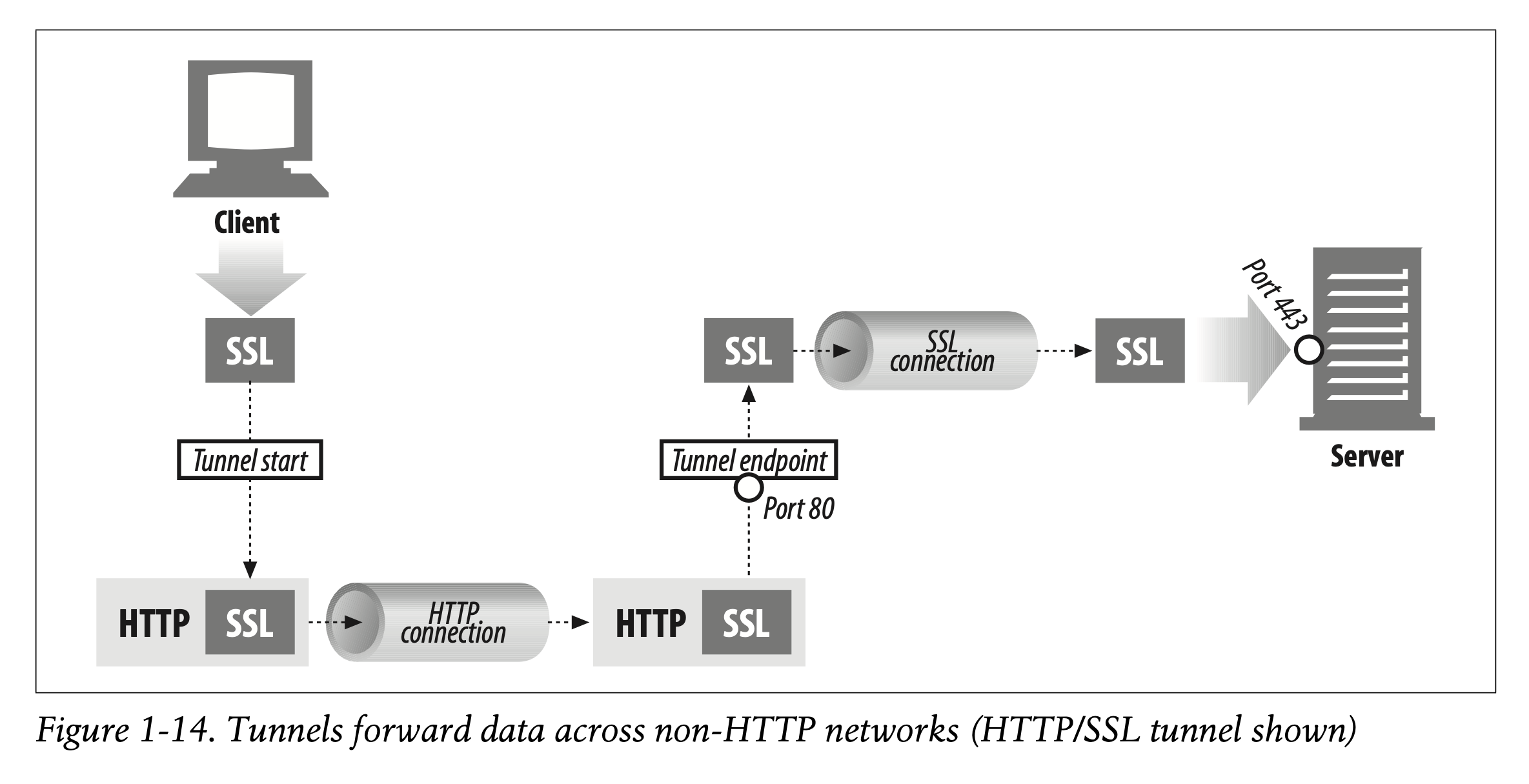
One popular use of HTTP tunnels is to carry encrypted Secure Sockets Layer (SSL) traffic through an HTTP connection, allowing SSL traffic through corporate firewalls that permit only web traffic. As sketched in Figure 1-14, an HTTP/SSL tunnel receives an HTTP request to establish an outgoing connection to a destination address and port, then proceeds to tunnel the encrypted SSL traffic over the HTTP channel so that it can be blindly relayed to the destination server.
-> HTTP 터널의 잘 알려진 용도 중 하나는 암호화된 Secure Sockets Layer(SSL) 트래픽을 HTTP 연결을 통해 전송하는 것입니다. 이때 터널은 SSL 트래픽이 오직 웹 트래픽만을 허용하는 기업의 방화벽을 통과하는 것을 가능하게 합니다.
-> Figure 1-14에 나타나는 것처럼, HTTP/SSL 터널은 목적 주소와 포트로의 연결을 설정하기 위해 HTTP Request를 받습니다. 이후 암호화된 SSL 트래픽을 HTTP 채널 위로 나아가게 하여 목적 서버에 맹목적으로 전달 가능하게 합니다.
(맹목적이라는 번역이 살짝 이상하긴 한데 한국말로 어떻게 표현해야 할지 모르겠네요)
Agents
User agents (or just agents) are client programs that make HTTP requests on the user’s behalf. Any application that issues web requests is an HTTP agent. So far, we’ve talked about only one kind of HTTP agent: web browsers. But there are many other kinds of user agents.
-> 유저 에이전트(혹은 그냥 에이전트)는 유저 대신 HTTP Request를 생성하는 클라이언트 프로그램입니다.
-> 웹 요청을 발생시키는 모든 애플리케이션은 HTTP 에이전트입니다.
-> 지금까지 우리는 오직 한 종류의 HTTP 에이전트 "웹 브라우저"에 대해서만 이야기해왔습니다.
-> 그러나 유저 에이전트에는 여러 가지 종류가 있습니다.
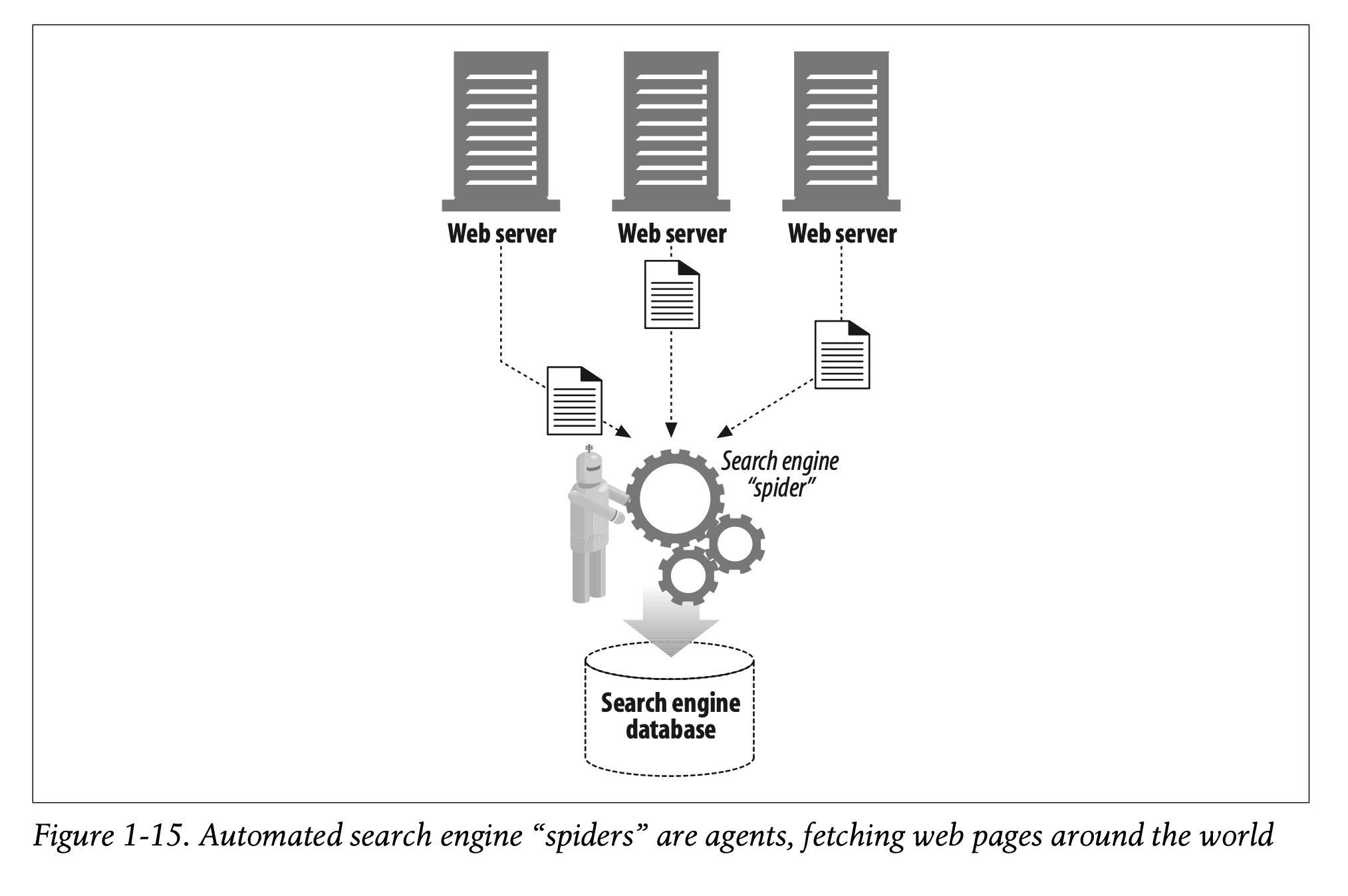
For example, there are machine-automated user agents that autonomously wander the Web, issuing HTTP transactions and fetching content, without human supervi- sion. These automated agents often have colorful names, such as “spiders” or “web robots” (see Figure 1-15). Spiders wander the Web to build useful archives of web content, such as a search engine’s database or a product catalog for a comparison-shopping robot. See Chapter 9 for more information.
-> 예를 들어, 인간의 관리감독 없이 HTTP 트랜잭션을 발생시키고 콘텐츠를 불러오며 자율적으로 웹을 거닐고 다니는 기기 자동화된 유저 에이전트가 있습니다.
-> 이러한 자동화된 에이전트는 "스파이더", "웹 로봇" 등의 다양한 이름을 가지고 있습니다(Figure 1-15).
-> 스파이더는 검색 엔진의 데이터베이스나 비교 쇼핑을 위한 상품 카탈로그처럼 웹 콘텐츠의 유용한 보관소를 만들어내기 위해 웹을 돌아다닙니다.
-> 더 많은 정보는 Chapter 9에서 확인할 수 있습니다.
🧡 요약 정리 🧡
Architectural Components of the Web
- Proxy : 클라이언트와 서버 사이에서 모든 HTTP 요청과 응답을 매개하는 서버 -> 요청과 응답 필터링, 웹 보안, 성능 최적화, 앱 통합
- Cache : 인기 문서들의 사본을 보관하는 프록시 서버의 특수형, 빠른 다운로드
- Gateway : HTTP 트래픽을 다른 프로토콜로 변환하는 역할을 수행하는 서버 -> 클라이언트는 게이트웨이와 HTTP 통신, 게이트웨이는 서버와 별도의 프로토콜로 통신
- Tunnel : 하나 이상의 HTTP 연결을 통해 HTTP가 아닌 트래픽을 전송하기 위한 HTTP 애플리케이션
- Agent : HTTP 요청을 발생시키는 모든 애플리케이션(웹 브라우저, 스파이더 등)
💛 감상 💛
-
프록시 중에서도 Caching 기능을 보유하고 있는 서버가 있다는 것을 알게 되었다. 매개 서버도 CPU처럼 캐시를 갖게 하자는 이런 기발한 발상은 도대체 어떤 똑똑한 사람이 한 걸까. 세상에는 똑똑한 사람들이 정말 많은 것 같다.
-
나는 HTTP를 배우면서 만약에 전송하고자 하는 데이터가 HTTP 데이터가 아니라면 어떻게 해야 할지 늘 궁금했다. 아직까지 코딩을 하면서 이런 이유로 막혀본 적은 없었기에 '그때가 되면 내가 알아서 하겠지~' 하고 속으로만 궁금해했던 것 같다. 검색을 게을리하면 안 된다는 걸 알면서도 말이다...ㅎㅎ 그래도 책을 읽다 보니 Tunnel에 대한 것을 알게 돼서 찜찜했던 부분이 어느 정도 해결되었다.
이제부터는 궁금한 게 생기면 그때그때 검색하는 사람이 되자. -
글을 읽으면서 "웹 로봇" 에이전트가 무엇인지 알게 되었다. 그러나 책에 나오는 글과 그림만으로는 웹 로봇이 구체적으로 어떻게 작동하는 것인지 알 수 없어서 추가로 서칭을 진행했다.
웹 로봇은 방문을 시작하는 Root Set부터 탐색을 시작하여 HTML 문서에 포함된 URL을 파싱하고 또 파싱하여 크롤링한다고 한다. 위 방식대로 URL을 계속해서 돌면 루프가 발생할 수 있어서 루프를 피하기 위한 별도의 처리가 필요하다고 한다.
추가로, 서칭 과정에서 그 유명한 robots.txt도 웹 로봇 때문에 나오게 된 것이라는 사실을 알게 되었다. 이는 로봇의 접근을 제어하는 정보를 저장하는 파일이다. 만약 웹 로봇이 표준을 따르고 있다면 웹 서버가 문서의 루트에 robots.txt를 가지고 있는지 확인할 것이다. 이때 robots.txt가 존재한다면 로봇의 접근이 제한되고, 404 Not Found를 돌려받으면 모든 리소스를 요청한다.
