
Chapter 8. Integration Points: Gateways, Tunnels, and Relays
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Relays
HTTP relays are simple HTTP proxies that do not fully adhere to the HTTP specifications. Relays process enough HTTP to establish connections, then blindly forward bytes.
-
HTTP 릴레이(Relay)는 HTTP 명세를 완벽하게 고수하지 않는 단순한 HTTP 프록시입니다.
-
릴레이는 HTTP를 사용하여 연결을 설정한 후 바이트를 포워딩합니다. 이때 바이트의 내용은 알지 못합니다.
Because HTTP is complicated, it’s sometimes useful to implement bare-bones proxies that just blindly forward traffic, without performing all of the header and method logic. Because blind relays are easy to implement, they sometimes are used to provide simple filtering, diagnostics, or content transformation. But they should be deployed with great caution, because of the serious potential for interoperability problems.
-
HTTP는 복잡하기 때문에 헤더와 메서드 로직을 수행하지 않고 맹목적으로 트래픽만 포워딩하는 프록시를 구현하는 것이 더 유용할 때가 있습니다.
-
맹목적인 중계는 구현하기도 쉽고 필터링, 진단, 콘텐츠 변경 등의 기능을 제공하기도 좋습니다.
-
그러나 HTTP 릴레이에는 한 가지 큰 주의사항이 있습니다.
-
바로 상호운용성 문제가 심각하게 발생할 수 있다는 점입니다.
One of the more common (and infamous) problems with some implementations of simple blind relays relates to their potential to cause keep-alive connections to hang, because they don’t properly process the Connection header. This situation is depicted in Figure8-14.
-
맹목적인 중계 과정에서 가장 흔하고 악명 높은 문제 중 하나는 keep-alive 연결이 중단될 잠재 위험이 있다는 점입니다.
-
릴레이가 Connection 헤더를 적절히 처리하지 않기 때문입니다.
-
Figure 8-14에서 이 상황을 나타내고 있습니다.
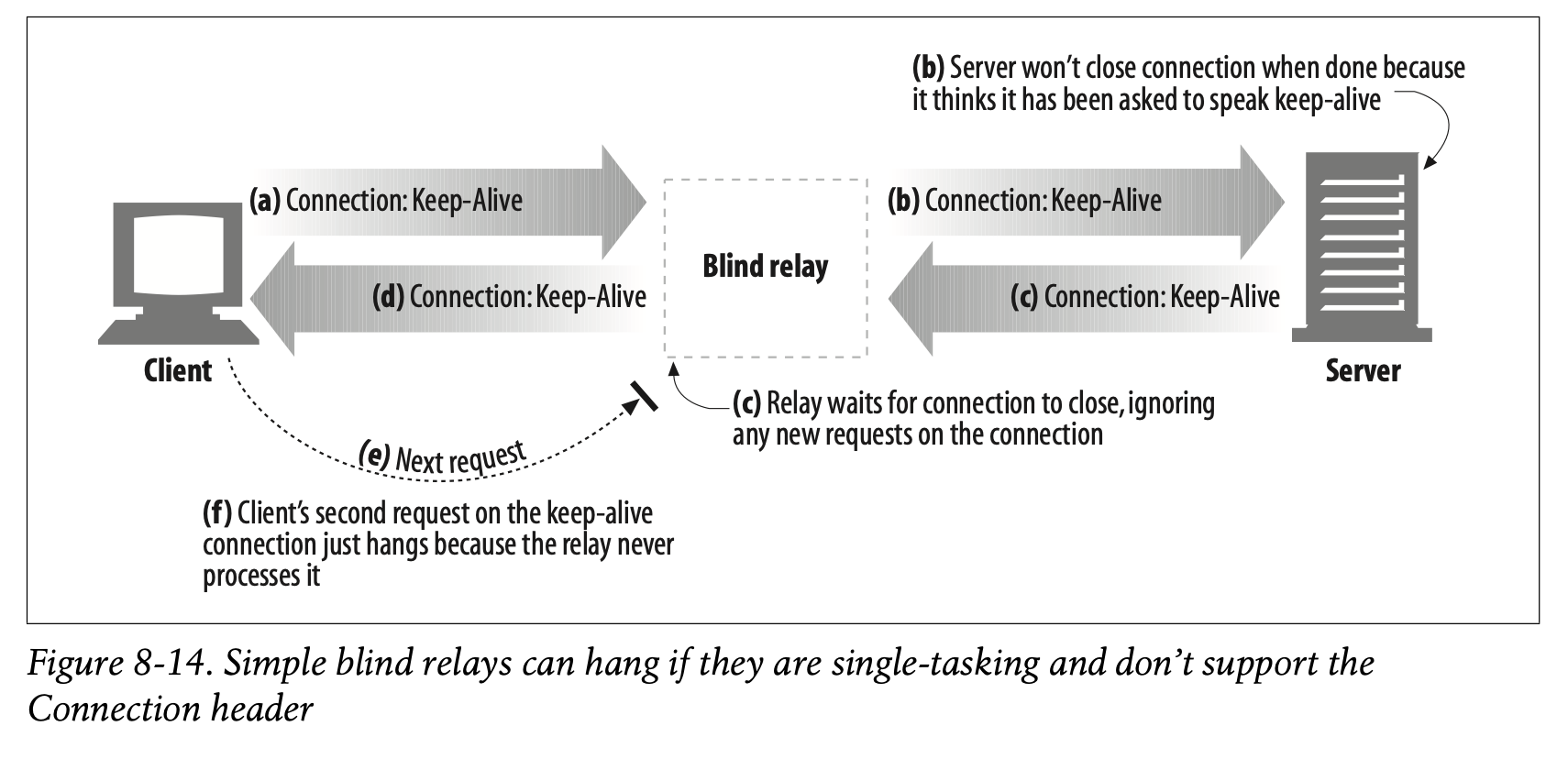
Here’s what’s going on in this figure:
- 각 과정에서 발생하는 일은 다음과 같습니다.
• In Figure 8-14a, a web client sends a message to the relay, including the Connection: Keep-Alive header, requesting a keep-alive connection if possible. The client waits for a response to learn if its request for a keep-alive channel was granted.
- Figure 8-14a에서 웹 클라이언트는 Connection: Keep-Alive 헤더를 포함하여 릴레이로 메시지를 전달합니다. 가능한 연결을 유지할 것을 요청하는 것입니다. 클라이언트는 keep-alive 요청이 승인되었는지 확인하기 위해 응답을 기다립니다.
• The relay gets the HTTP request, but it doesn’t understand the Connection header, so it passes the message verbatim down the chain to the server (Figure8-14b). However, the Connection header is a hop-by-hop header; it applies only to a single transport link and shouldn’t be passed down the chain. Bad things are about to start happening!
- 릴레이는 HTTP 요청을 전달받지만 Connection 헤더를 이해하지 못한 채 메시지를 다운스트림 서버로 전달합니다. (Figure 8-14b) 그러나 Connection 헤더는 hop-by-hop 헤더입니다. 즉, 단일한 전달 링크에만 적용 가능하며 체인을 따라 전달해서는 안 됩니다. 여기서부터 뭔가 잘못되기 시작합니다.
• In Figure 8-14b, the relayed HTTP request arrives at the web server. When the web server receives the proxied Connection: Keep-Alive header, it mistakenly concludes that the relay (which looks like any other client to the server) wants to speak keep-alive! That’s fine with the web server—it agrees to speak keep-alive and sends a Connection: Keep-Alive response header back in Figure 8-14c. So, at this point, the web server thinks it is speaking keep-alive with the relay, and it will adhere to rules of keep-alive. But the relay doesn’t know anything about keep-alive.
-
Figure 8-14b에서 중계된 HTTP 요청이 웹 서버에 도달합니다.
-
웹 서버가 프록시된 Connection: Keep-Alive 헤더를 받았을 때, 릴레이가 keep-alive를 요청한 것이라고 착각합니다.
-
웹 서버 입장에서는 이러나 저러나 아무 상관이 없습니다. keep-alive 연결에 동의하고 Connection: Keep-Alive 응답 헤더를 Figure 8-14c에서처럼 돌려보내면 그만입니다.
-
웹 서버는 자신이 릴레이와 keep-alive로 통신하고 있다고 생각하기 때문에 keep-alive 규칙을 준수할 것입니다.
-
하지만 릴레이는 keep-alive에 대해 아무것도 알지 못합니다.
• In Figure 8-14d, the relay forwards the web server’s response message back to the client, passing along the Connection: Keep-Alive header from the web server. The client sees this header and assumes the relay has agreed to speak keep-alive. At this point, both the client and server believe they are speaking keep-alive, but the relay to which they are talking doesn’t know the first thing about keep-alive.
- Figure 8-14d에서 릴레이는 웹 서버의 응답 메시지를 클라이언트에게 포워딩합니다. 이때 웹 서버로부터 Connection: Keep-Alive 헤더도 함께 전달됩니다. 클라이언트는 이 헤더를 확인하고 릴레이가 keep-alive 연결에 동의한 것으로 간주합니다. 클라이언트와 서버는 서로가 keep-alive로 통신하고 있다고 믿지만, 그들이 통신하고 있는 릴레이는 keep-alive에 대해 전혀 알지 못합니다.
• Because the relay doesn’t know anything about keepalive, it forwards all the data it receives back to the client, waiting for the origin server to close the connection. But the origin server will not close the connection, because it believes the relay asked the server to keep the connection open! So, the relay will hang waiting for the connection to close.
- 릴레이는 keep-alive에 대해 아무것도 알지 못하기 때문에 클라이언트에게 데이터를 그대로 전달하고 원본 서버가 연결 종료되기를 기다립니다. 하지만 원본 서버는 연결을 종료하지 않을 것입니다. 서버는 릴레이가 연결 유지를 요청했다고 생각하기 때문입니다. 따라서 릴레이는 연결 종료를 대기하며 중단될 것입니다.
• When the client gets the response message back in Figure 8-14d, it moves right along to the next request, sending another request to the relay on the keep-alive connection (Figure8-14e). Simple relays usually never expect another request on the same connection. The browser just spins, making no progress.
-
Figure 8-14d에서 클라이언트가 응답 메시지를 돌려받을 때 다음 요청이 keep-alive 연결을 따라 릴레이로 전달됩니다. (Figure 8-14e)
-
단순한 릴레이는 동일한 연결에 다른 요청이 들어온다는 것을 전혀 예측하지 못합니다.
-
브라우저는 무한 로딩에 빠지며 아무런 진전을 보이지 않습니다.
There are ways to make relays slightly smarter, to remove these risks, but any simplification of proxies runs the risk of interoperation problems. If you are building simple HTTP relays for a particular purpose, be cautious how you use them. For any wide-scale deployment, you should strongly consider using a real, HTTP-compliant proxy server instead.
-
이러한 리스크를 줄이고 릴레이를 더 똑똑하게 만드는 방법도 존재하지만, 프록시를 단순화하면 상호운용 문제가 발생할 수 있습니다.
-
어떤 이유로 단순한 HTTP 릴레이를 직접 구축할 일이 생긴다면 사용 방법에 유의해야 합니다.
-
대규모 배포의 경우 실제 HTTP 호환 프록시 서버를 사용하는 것을 적극적으로 고려하는 것이 좋습니다.
For more information about relays and connection management, see “Keep-Alive and Dumb Proxies” in Chapter 4.
- 릴레이와 연결 관리에 대한 자세한 정보는 Chapter 4의 "Keep-Alive and Dumb Proxies"를 참고하기 바랍니다.
(이미 읽은 부분이라 벨로그에도 있습니다 ---> https://velog.io/@dvlp-sy/TIL-HTTP-The-Definitive-Guide-p94-p96)
✏️ 요약
Relays
: 헤더와 메서드 로직을 수행하지 않고 맹목적으로 트래픽만 포워딩하는 HTTP 프록시
- 클라이언트 -> 릴레이 : Connection: Keep-Alive 전달
- 릴레이 -> 서버 : Connection 헤더를 처리하지 않고 서버에 전달, 서버는 릴레이가 keep-alive 연결을 시도한다고 착각
- 서버 -> 릴레이 : keep-alive 연결을 승인한다는 뜻으로 Connection 헤더 전달
- 릴레이 -> 클라이언트 : Connection 헤더를 처리하지 않고 클라이언트에 전달, 클라이언트는 릴레이가 keep-alive 연결을 승인했다고 착각
- 릴레이는 서버가 연결을 종료할 것을 기대하지만 클라이언트는 릴레이에 또다른 요청 전송 -> 요청 무시
- 클라이언트나 서버가 타임아웃으로 연결을 종료할 때까지 로딩 발생
(감상은 전에 읽었던 내용과 비슷하여 생략합니다.)
