
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Preface
We continue our tour of HTTP architecture with a close look at the self-animating user agents called web robots.
- 이제 스스로 움직이는 사용자 에이전트인 웹 로봇에 대해 자세히 살펴보면서 HTTP 아키텍처에 대한 설명을 이어갑니다.
Web robots are software programs that automate a series of web transactions without human interaction. Many robots wander from web site to web site, fetching content, following hyperlinks, and processing the data they find. These kinds of robots are given colorful names such as “crawlers,” “spiders,” “worms,” and “bots” because of the way they automatically explore web sites, seemingly with minds of their own.
-
웹 로봇은 인간 상호작용 없이 일련의 웹 트랜잭션 과정을 자동화하는 소프트웨어 프로그램입니다.
-
많은 로봇들이 웹 사이트와 웹 사이트 사이를 돌아다니고 있습니다. 콘텐츠를 수집하고 하이퍼링크를 추적하고 그들이 찾은 데이터를 처리하기도 합니다.
-
이러한 종류의 로봇은 "crawler(크롤러)", "spider(스파이더)", "worm(웜)", "bot(봇)" 등 다양한 이름으로 불립니다.
-
로봇이 자신의 생각대로 웹 사이트를 자동 탐색하는 것처럼 보이기 때문입니다.
Here are a few examples of web robots:
• Stock-graphing robots issue HTTP GETs to stock market servers every few minutes and use the data to build stock price trend graphs.
• Web-census robots gather “census” information about the scale and evolution of the World Wide Web. They wander the Web counting the number of pages and recording the size, language, and media type of each page.
• Search-engine robots collect all the documents they find to create search databases.
• Comparison-shopping robots gather web pages from online store catalogs to build databases of products and their prices.
-
다음은 웹 로봇의 몇 가지 예시입니다.
-
Stock-graphing Robots : 몇 분마다 주식 시장 서버에 HTTP Get 메서드를 발행하고, 그 데이터를 사용하여 주가 추세 그래프를 생성합니다.
-
Web-census Robots : World Wide Web의 규모와 진화에 대해 조사한 정보를 수집합니다. 이 로봇은 페이지의 수를 계산하고 각 페이지의 사이즈와 언어, 미디어 타입에 대해 기록합니다.
-
Search-engine Robots : 로봇이 찾은 문서들을 모두 수집하여 검색 데이터베이스를 구축합니다.
-
Comparison-shopping Robots : 온라인 스토어 카탈로그에서 웹 페이지를 수집하여 상품과 가격에 대한 데이터베이스를 구축합니다.
-
Crawlers and Crawling
Web crawlers are robots that recursively traverse information webs, fetching first one web page, then all the web pages to which that page points, then all the web pages to which those pages point, and so on. When a robot recursively follows web links, it is called a crawler or a spider because it “crawls” along the web created by HTML hyperlinks.
-
웹 크롤러는 정보 웹을 재귀적으로 탐색하는 로봇입니다. 첫 번째 웹 페이지를 불러온 후 해당 페이지에 있는 모든 웹 페이지를 불러오고, 그 페이지에서 또다시 모든 웹 페이지를 불러오는 것을 반복합니다.
-
로봇이 재귀적으로 웹 링크를 따라갈 때 크롤러 혹은 스파이더를 호출합니다.
-
HTML 하이퍼링크로 생성되는 웹을 따라 크롤링을 수행해야 하기 때문입니다.
Internet search engines use crawlers to wander about the Web and pull back all the documents they encounter. These documents are then processed to create a searchable database, allowing users to find documents that contain particular words. With billions of web pages out there to find and bring back, these search-engine spiders necessarily are some of the most sophisticated robots. Let’s look in more detail at how crawlers work.
-
인터넷 검색 엔진은 크롤러를 사용하여 웹을 탐색하며 발견한 모든 문서를 가져옵니다.
-
이 문서들은 탐색 가능한 데이터베이스를 생성하기 위해 처리됩니다. 사용자가 특정 단어를 포함한 문서를 찾을 수 있게 하기 위함입니다.
-
수십억 개의 웹 페이지를 찾아서 불러와야 하는 Search-engine 스파이더는 가장 정교한 로봇 중 하나입니다.
-
그럼 크롤러의 동작 방식에 대해 자세히 알아봅시다.
Where to Start: The "Root Set"
Before you can unleash your hungry crawler, you need to give it a starting point. The initial set of URLs that a crawler starts visiting is referred to as the root set. When picking a root set, you should choose URLs from enough different places that crawling all the links will eventually get you to most of the web pages that interest you.
-
배고픈 크롤러를 풀어주기 전에 먼저 시작점을 지정해주어야 합니다.
-
크롤러가 방문을 시작하는 URL의 초기 집합을 루트 집합이라고 부릅니다.
-
루트 집합을 선택할 때는 크롤링한 모든 링크로 결과적으로 사용자가 관심을 갖고 있는 모든 웹 페이지에 도달할 수 있도록 충분히 다양한 URL을 선택해야 합니다.
What’s a good root set to use for crawling the web in Figure 9-1? As in the real Web, there is no single document that eventually links to every document. If you start with document A in Figure 9-1, you can get to B, C, and D, then to E and F, then to J, and then to K. But there’s no chain of links from A to G or from A to N.
-
Figure 9-1에서 웹 크롤링에 사용하기 좋은 루트 집합은 무엇일까요?
-
실제 웹에서처럼 최종적으로 모든 문서가 링크와 연결된 문서는 없습니다.
-
Figure 9-1에서 A 문서부터 시작하면 B, C, D, 다음 E, F, 다음 J, 다음 K 순서대로 방문하게 됩니다.
-
하지만 A부터 G, A부터 N까지는 링크가 생기지 않습니다.
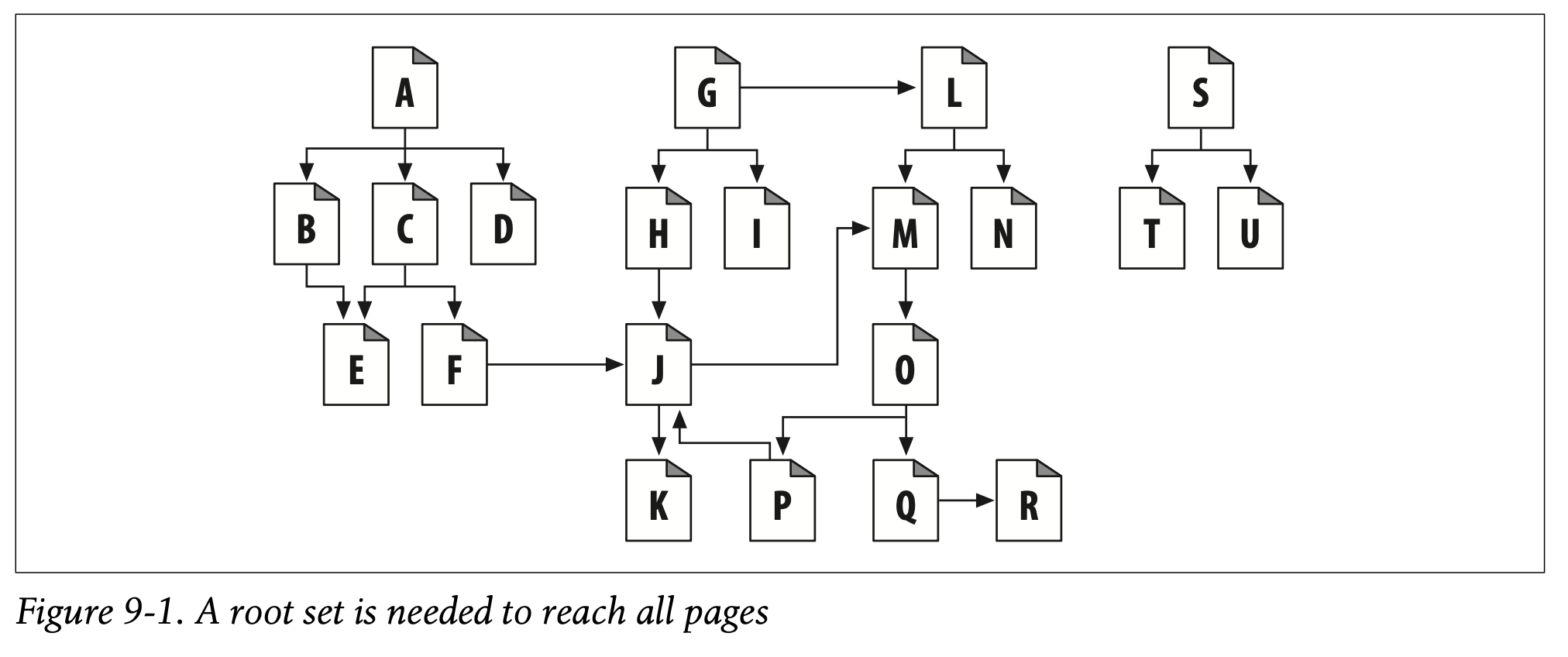
Some web pages in this web, such as S, T, and U, are nearly stranded—isolated, without any links pointing at them. Perhaps these lonely pages are new, and no one has found them yet. Or perhaps they are really old or obscure.
-
S, T, U와 같은 일부 웹 페이지는 링크 없이 거의 고립되어 있습니다.
-
아마도 이 외로운 페이지들은 새로 만들어져서 아직 아무도 발견하지 못한 페이지일 수도 있습니다.
-
그게 아니라면 매우 오래되었거나 모호한 페이지일 수도 있습니다.
In general, you don’t need too many pages in the root set to cover a large portion of the web. In Figure9-1, you need only A, G, and S in the root set to reach all pages.
-
일반적으로는 웹의 많은 부분을 커버하기 위해 루트 집합에 너무 많은 페이지를 담을 필요는 없습니다.
-
Figure 9-1에서 모든 페이지를 방문하기 위해 루트 집합에 A, G, S만 포함하면 됩니다.
Typically, a good root set consists of the big, popular web sites (for example, http://www.yahoo.com), a list of newly created pages, and a list of obscure pages that aren’t often linked to. Many large-scale production crawlers, such as those used by Internet search engines, have a way for users to submit new or obscure pages into the root set. This root set grows over time and is the seed list for any fresh crawls.
-
좋은 루트 집합은 대체로 크고 유명한 웹 사이트들과 새로 생성된 페이지, 자주 링크되지 않은 모호한 페이지들로 구성되어 있습니다.
-
인터넷 검색 엔진에 의해 사용되는 대규모 상용 크롤러들은 새로 생성된 페이지나 모호한 페이지를 루트 집합에 제출하게 하는 방법을 가지고 있습니다.
-
루트 집합은 나날이 거대해져 새로운 크롤링의 시드 목록이 됩니다.
✏️ 요약
Robots(Crawlers)
: 웹 페이지를 재귀적으로 탐색하는 로봇
- Stock-graphing Robots : 일정 시간마다 주식 시장 서버에 GET 메서드를 발행하여 그래프를 생성하는 로봇
- Web-census Robots : World Wide Web의 규모를 조사하는 로봇
- Search-engine Robots : 검색 데이터베이스를 구축하는 로봇
Comparison-shopping Robots : 온라인 스토어 상품과 가격에 대한 데이터베이스를 구축하는 로봇
Root Set
: 웹 크롤링의 시작점이자 새로운 크롤링의 시드 목록
- 사용자가 관심을 가지고 있는 모든 웹 페이지에 도달할 수 있어야 함
- 크고 유명한 웹 페이지
- 새로 생성된 웹 페이지
- 다른 페이지와 많이 링크되지 않은 웹 페이지
✏️ 감상
검색 엔진으로 접근할 수 없는 Deep Web
검색 엔진 크롤러의 루트 집합에 가능한 많은 웹 페이지를 포함한다고 해도 수십억 개의 페이지에 모두 도달하기란 불가능하다. 그래서 검색 엔진으로 접근할 수 없는 딥웹(Deep Web)도 반드시 존재하기 마련이다. 물론 딥웹이 생기는 것은 크롤러의 구조적인 이유도 있겠지만 웹 개발자가 검색 엔진이 접근하지 못하도록 의도적으로 막았을 확률이 높다. 개인의 클라우드 저장 공간이나 외부로 유출되어서는 안 되는 문서들까지 검색 엔진에 노출되어서는 안 되기 때문이다. 검색 엔진이 페이지를 찾더라도 robots.txt가 크롤러를 차단하도록 설정되어 있다면 내용을 읽을 수가 없다.
그런데 딥웹에 대해 논하다 보면 반드시 같이 따라오는 단어가 있다. 바로 다크웹(Dark Web)이다. 딥웹이 단순히 검색 엔진으로 접근 불가능한 웹 페이지를 나타내는 개념이라면 다크웹은 딥웹 중에서도 다크넷을 통해서만 접근이 가능한 웹 페이지를 말한다. 다크넷에서는 암호화된 트래픽을 노드 바이 노드로 전달하기 때문에 사용자의 지리적인 위치나 IP를 추적하기 어렵고, 사용자 또한 host에 대한 정보를 얻기 어렵다. 이런 특성으로 인해 다크웹은 불법 약물, 무기류, 신분증 위조 등의 암시장으로 사용되는 경우가 많다고 한다...ㅋㅋ 위키피디아를 읽어보면 진짜 온갖 불법 사례들을 확인할 수 있다. 제일 충격적이었던 내용은 다크웹에서 가장 인기 있는 것이 불법 포르노(여기까지는 예측 가능했다), 그 중에서도 약 80%의 트래픽이 아동 포르노 접속과 연관되어 있다는 이야기였다. 전부 깜방으로 보내버려야 한다.
https://en.wikipedia.org/wiki/Dark_web
(불법 사례는 영문 위키피디아에만 있다)
지난 글에서 DNS 터널링 얘기를 해서 그런지 불법 웹 사이트에 접속하는 것만으로도 전자기기가 악성코드에 감염될 수 있겠다는 생각이 든다. 불법적인 일로 돈을 버는 사람들인데, 사람을 협박할 수 있는 좋은 수단을 보험으로 갖고 있지 않을 이유가 없다.
최소한 네트워크를 공부한 사람이라면 웹을 사용하면서 경각심을 갖는 것이 좋겠다. 배우면 배울수록 네트워크가 굉장히 허술하다는 것을 느끼고 있다...
