
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Avoiding Loops and Dups
Pattern detection
Cycles caused by filesystem symlinks and similar misconfigurations tend to follow patterns; for example, the URL may grow with components duplicated. Some robots view URLs with repeating components as potential cycles and refuse to crawl URLs with more than two or three repeated components.
Not all repetition is immediate (e.g., “/subdir/subdir/subdir...”). It’s possible to have cycles of period 2 or other intervals, such as “/subdir/images/subdir/images/subdir/images/...”. Some robots look for repeating patterns of a few different periods.
Pattern detection
-
파일 시스템의 Symlink 및 그와 유사한 방식에 의한 사이클은 대체로 패턴을 따릅니다.
-
URL이 구성 요소가 중복되어 커지는 것이 그 예시입니다.
-
일부 로봇은 반복적인 구성 요소를 가진 URL을 잠재적인 사이클로 여겨 두 개 혹은 세 개 이상의 반복 요소를 가진 URL을 크롤링하지 않습니다.
-
모든 반복이 연결되어 나타나지는 않습니다 (/subdir/subdir/subdir...처럼).
-
"subdir/images/subdir/images/subdir/images/.../"와 같이 두 칸 이상의 간격을 두고 사이클이 나타날 수도 있습니다.
-
어떤 로봇은 서로 다른 주기로 반복하는 패턴을 발견해내기도 합니다.
Content fingerprinting
Fingerprinting is a more direct way of detecting duplicates that is used by some of the more sophisticated web crawlers. Robots using content fingerprinting take the bytes in the content of the page and compute a checksum. This checksum is a compact representation of the content of the page. If a robot ever fetches a page whose checksum it has seen before, the page’s links are not crawled—if the robot has seen the page’s content before, it has already initiated the crawling of
the page’s links.The checksum function must be chosen so that the odds of two different pages having the same checksum are small. Message digest functions such as MD5 are popular for fingerprinting.
Because some web servers dynamically modify pages on the fly, robots sometimes omit certain parts of the web page content, such as embedded links, from the checksum calculation. Still, dynamic server-side includes that customize arbitrary page content (adding dates, access counters, etc.) may prevent duplicate detection.
Content fingerprinting
-
핑거프린팅은 더 정교한 웹 크롤러가 보다 직접적으로 중복 페이지를 감지하는 방식입니다.
-
콘텐츠 핑거프린팅을 사용하는 로봇은 페이지의 내용에서 바이트를 수집하여 checksum을 연산합니다.
-
checksum은 페이지의 내용을 압축하여 표현한 것입니다.
-
로봇이 가져온 페이지의 checksum이 이전에 확인된 것이라면 해당 페이지의 링크는 크롤링되지 않습니다.
-
로봇이 콘텐츠를 이전에 확인했다는 것은 해당 페이지의 링크를 이미 크롤링하기 시작했음을 의미합니다.
-
checksum 함수는 서로 다른 두 페이지가 동일한 checksum을 가질 odds가 작도록 선택되어야 합니다.
(** odds : P(A)/P(~A) -> odds가 작을수록 checksum이 일치하지 않을 확률이 높다) -
MD5와 같은 메시지 다이제스트 함수가 핑거프린팅에 자주 사용됩니다.
(** message digest : checksum 함수의 입력 데이터를 고정 길이의 출력 값으로 변환한 것) -
일부 웹 서버는 페이지를 동적으로 즉시 수정하기 때문에 로봇이 임베딩된 링크와 같은 웹 페이지의 특정 콘텐츠를 checksum 계산에서 생략하는 경우가 있습니다.
-
여전히 페이지의 일부 내용을 커스터마이징(날짜를 더하거나 숫자를 카운팅하는 등)하는 동적 서버는 중복 페이지를 감지하지 못할 수 있습니다.
Human monitoring
The Web is a wild place. Your brave robot eventually will stumble into a problem that none of your techniques will catch. All production-quality robots must be designed with diagnostics and logging, so human beings can easily monitor the robot’s progress and be warned quickly if something unusual is happening. In some cases, angry net citizens will highlight the problem for you by sending you nasty email.
Human Monitoring
-
웹은 거친 세상입니다.
-
용감한 로봇은 결국 어떤 기술로도 찾지 못한 문제에 부딪히게 될 것입니다.
-
모든 상용 로봇은 진단과 로그 기능을 지원하도록 설계되었습니다.
-
따라서 인간이 로봇의 작업 과정을 쉽게 모니터링할 수 있고, 무언가 이상이 발생했을 때 신속하게 경고를 받을 수 있습니다.
-
화가 난 인터넷 시민들이 불쾌한 이메일을 전송하며 문제를 조명하는 경우도 있을 것입니다.
Good spider heuristics for crawling datasets as vast as the Web are always works in progress. Rules are built over time and adapted as new types of resources are added to the Web. Good rules are always evolving.
-
웹과 같이 방대한 데이터셋을 크롤링하기 위한 좋은 스파이더 휴리스틱은 지금도 계속해서 작동 중입니다.
-
규칙은 오랜 시간 구축되고 웹에 새로운 종류의 리소스가 추가됨에 따라 채택됩니다.
-
좋은 규칙은 항상 진화하는 것입니다.
Many smaller, more customized crawlers skirt some of these issues, as the resources (servers, network bandwidth, etc.) that are impacted by an errant crawler are manageable, or possibly even are under the control of the person performing the crawl (such as on an intranet site). These crawlers rely on more human monitoring to prevent problems.
-
오류가 있는 크롤러에 영향을 받은 리소스(서버, 네트워크, 대역폭 등)가 관리 가능하며 크롤링을 수행하는 인간에 의해 통제할 수 있는 경우, 규모가 더 작고 맞춤화된 많은 크롤러는 몇 가지 문제들을 회피하는 경우가 많습니다.
-
이러한 크롤러들은 문제를 막기 위해 인간의 모니터링에 의존합니다.
Robotic HTTP
Robots are no different from any other HTTP client program. They too need to abide by the rules of the HTTP specification. A robot that is making HTTP requests and advertising itself as an HTTP/1.1 client needs to use the appropriate HTTP request headers.
-
로봇도 다른 HTTP 클라이언트 프로그램과 별반 다르지 않습니다.
-
로봇도 HTTP 명세상의 규칙을 엄연히 준수해야 합니다.
-
HTTP 요청을 생성하고 자신을 HTTP/1.1 클라이언트라 주장하는 로봇이라면 적절한 HTTP 요청 헤더를 사용해야 합니다.
Many robots try to implement the minimum amount of HTTP needed to request the content they seek. This can lead to problems; however, it’s unlikely that this behavior will change anytime soon. As a result, many robots make HTTP/1.0 requests, because that protocol has few requirements.
-
많은 로봇들이 찾고자 하는 콘텐츠를 요청하기 위해 필요한 HTTP를 최소한으로 구현하고자 합니다.
-
이 방식이 문제를 일으키기도 하지만 당분간 바뀔 일은 거의 없습니다.
-
결과적으로 로봇은 대체로 HTTP/1.0 요청을 전송합니다. 프로토콜이 요구하는 사항이 거의 없기 때문입니다.
Identifying Request Headers
Despite the minimum amount of HTTP that robots tend to support, most do implement and send some identification headers—most notably, the User-Agent HTTP header. It’s recommended that robot implementors send some basic header information to notify the site of the capabilities of the robot, the robot’s identity, and where it originated.
-
로봇이 HTTP를 최소한으로 지원하더라도 대부분의 로봇은 일부 식별 헤더들을 구현하여 전송합니다.
-
대표적인 것이 바로 User-Agent HTTP 헤더입니다.
-
요청을 전송할 때는 로봇 개발자가 몇 가지 기본적인 헤더 정보를 전송할 것을 권장하고 있습니다.
-
로봇의 기능, 신원, 출처를 사이트에 알리기 위함입니다.
This is useful information both for tracking down the owner of an errant crawler and for giving the server some information about what types of content the robot can handle. Some of the basic identifying headers that robot implementors are encouraged to implement are:
User-Agent
Tells the server the name of the robot making the request.From
Provides the email address of the robot’s user/administrator.Accept
Tells the server what media types are okay to send.† This can help ensure that the robot receives only content in which it’s interested (text, images, etc.).Referer
Provides the URL of the document that contains the current request-URL.
-
이는 잘못된 크롤러의 소유자를 추적하고 로봇이 처리할 수 있는 콘텐츠의 종류를 서버에 알리는 데 있어 유용한 정보입니다.
-
로봇 개발자가 구현하기를 권장하는 기본적인 식별 헤더는 다음과 같습니다.
- User-Agent : 서버에게 요청을 생성한 로봇의 이름 전달
- From : 로봇 사용자 및 관리자의 이메일 주소 제공
- Accept : 전송 가능한 미디어 타입을 서버에 전달 (로봇이 필요로 하는 콘텐츠(텍스트, 이미지 등)만 받을 수 있도록 보장 가능)
- Referer : 현재 요청 URL을 포함하고 있는 문서의 URL 제공
Virtual Hosting
Robot implementors need to support the Host header. Given the prevalence of virtual hosting (Chapter 5 discusses virtually hosted servers in more detail), not including the Host HTTP header in requests can lead to robots identifying the wrong content with a particular URL. HTTP/1.1 requires the use of the Host header for this reason.
-
로봇 개발자는 Host 헤더를 지원해야 합니다.
-
가상 호스팅이 널리 보급되어 있는 환경에서는 Host HTTP 헤더를 요청에 포함하지 않으면 로봇이 특정 URL을 잘못된 콘텐츠로 식별할 가능성이 있습니다. (가상으로 호스팅된 서버는 Chapter 5에서 자세히 다루고 있습니다.)
-
HTTP/1.1은 이러한 이유로 Host 헤더를 사용하도록 요구합니다.
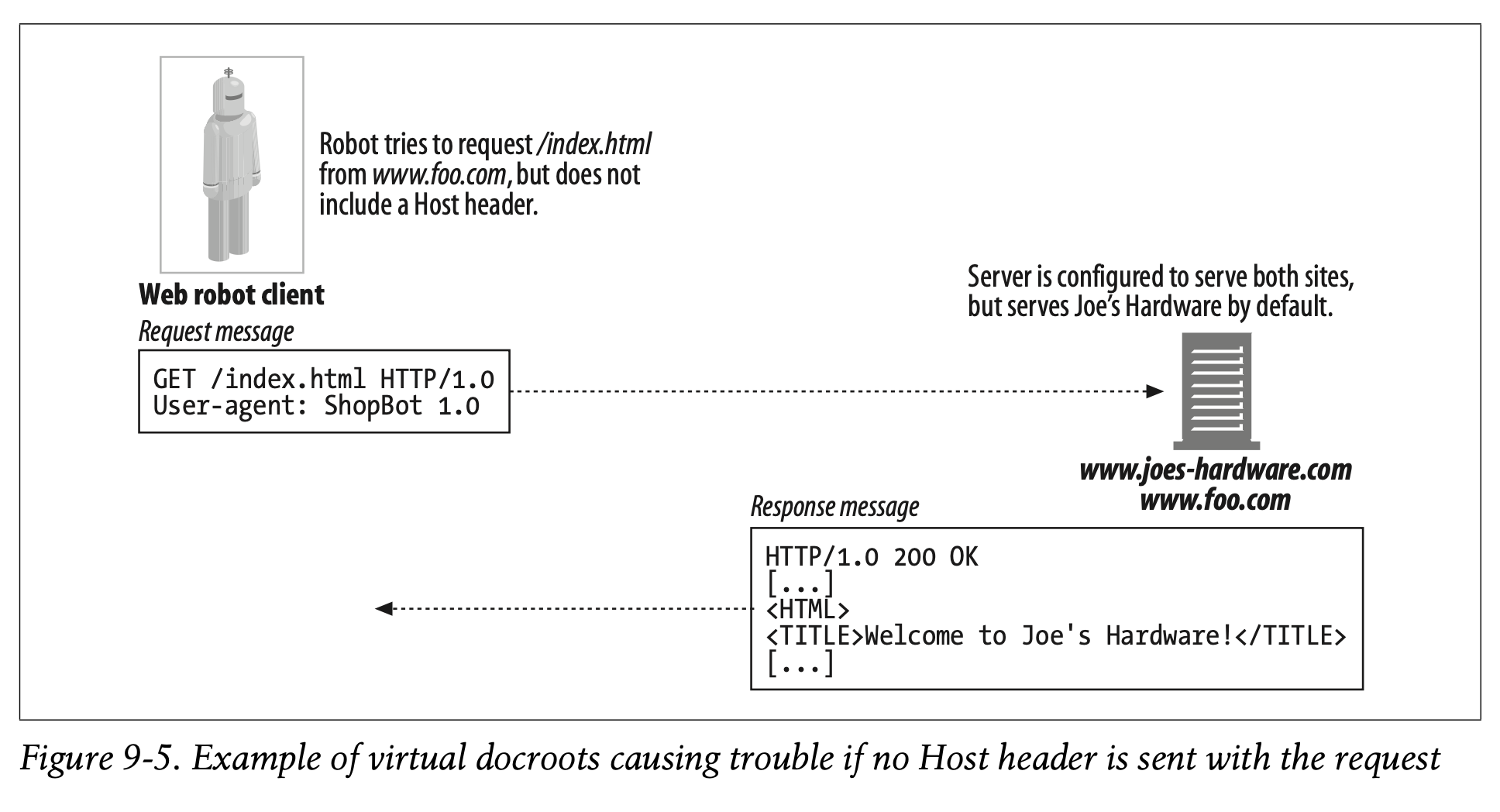
Most servers are configured to serve a particular site by default. Thus, a crawler not including the Host header can make a request to a server serving two sites, like those in Figure9-5 (www.joes-hardware.com and www.foo.com) and, if the server is configured to serve www.joes-hardware.com by default (and does not require the Host header), a request for a page on www.foo.com can result in the crawler getting content from the Joe’s Hardware site. Worse yet, the crawler will actually think the content from Joe’s Hardware was from www.foo.com. I am sure you can think of some more unfortunate situations if documents from two sites with polar political or other views were served from the same server.
-
대부분의 서버는 특정 사이트를 기본으로 제공하도록 구성되어 있습니다.
-
따라서 Host 헤더를 포함하지 않은 크롤러는 Figure 9-5에 나타난 것과 같이 서버가 두 개의 사이트를 제공하도록 요청할 수 있습니다.
-
Figure 9-5에서 서버는 www.joes-hardware.com을 기본으로 제공하도록 구성되어 있습니다. 이때 Host 헤더는 필요하지 않습니다.
-
결과적으로 www.foo.com 에 대한 페이지 요청은 크롤러가 Joe's Hardware 사이트로부터 콘텐츠를 불러옵니다.
-
심지어 크롤러는 Joe's Hardware로부터 불러온 콘텐츠가 www.foo.com에서 왔다고 착각할 것입니다.
-
정치적 견해가 극과 극인 두 사이트의 문서가 같은 서버에서 제공된다면 꽤나 불운한 상황이 발생할 수 있습니다.
✏️ 요약
Heuristics to Avoid Loops
[1]~[5]는 이전 게시글 참조
https://velog.io/@dvlp-sy/TIL-HTTP-The-Definitive-Guide-p221-p223
[6] 패턴 감지
: 반복적인 구성 요소를 가진 URL을 잠재적인 사이클로 간주하여 크롤링하지 않는 기법
- 파일 시스템의 Symlink에 의한 사이클은 대체로 패턴 존재
- 서로 다른 주기로 반복하는 패턴도 있을 수 있음
[7] 핑거프린팅
: Checksum을 계산하여 중복 페이지를 감지하는 기법
- Checksum : 페이지의 바이트를 수집하여 내용을 압축하여 표현한 것
- 이전에 방문한 페이지의 Checksum과 값이 동일하면 크롤링하지 않음
- Checksum Function : MD5 등 (서로 다른 두 페이지가 동일한 Checksum을 가질 확률이 작도록 설계해야 함)
- 동적으로 일부 내용을 수정하는 서버는 여전히 중복 페이지를 감지하지 못할 수 있음
[8] 모니터링
: 로봇의 진단 기능과 로그 기능을 통해 직접 모니터링하는 기법
Identifying Request Headers
: 로봇의 기능, 신원, 출처를 사이트에 알리기 위해 포함하는 기본적인 HTTP 식별 헤더
- Host : 가상 호스팅이 널리 보급된 환경에서 어떤 사이트에 대한 요청인지 명확하게 전달
- User-Agent : 서버에게 요청을 생성한 로봇의 이름 전달
- From : 로봇 사용자 및 관리자의 이메일 주소 제공
- Accept : 전송 가능한 미디어 타입을 서버에 전달 (로봇이 필요로 하는 콘텐츠(텍스트, 이미지 등)만 받을 수 있도록 보장 가능)
- Referer : 현재 요청 URL을 포함하고 있는 문서의 URL 제공
✏️ 감상
MD5는 어떤 함수일까
MD5는 대표적인 해시 알고리즘 중 하나다. 입력한 문자열을 128비트의 해시값으로 변환하여 출력하는 기능을 갖고 있다. 어떤 길이의 문자열을 입력하든 압축된 값을 반환하며 빠르게 연산 가능하다는 특징 덕에 Checksum으로 자주 활용된다. 특히 네트워크 전송 과정에서의 데이터 손실을 확인할 때 많이 쓰인다.
MD5가 Checksum으로써의 가치가 있다는 것은 분명한 사실이지만 요즘은 MD5 사용을 권장하지 않는 것으로 알고 있다. 빠른 연산이 가능하다는 점이 양날의 검이 된 것인데, 1분만에 해시 충돌을 찾을 수 있을 정도로 빠른 알고리즘이 세상에 공개되었기 때문이다. 2006년 기준 1분이니까 지금은 사실상 아무 의미가 없는 암호화인 셈이다. Salt를 붙여도 속도가 빨라서 금방 뚫린다고 한다. 보안을 목적으로 해시 함수를 쓸 것이라면 MD5 대신 SHA(Secure Hash Algorithms) 함수군을 쓰도록 하자.
