
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Dynamic Virtual Web Spaces
It’s possible for malicious webmasters to intentionally create sophisticated crawler loops to trap innocent, unsuspecting robots. In particular, it’s easy to publish a URL that looks like a normal file but really is a gateway application. This application can whip up HTML on the fly that contains links to imaginary URLs on the same server. When these imaginary URLs are requested, the nasty server fabricates a new HTML page with new imaginary URLs.
-
악의적인 웹마스터는 단순하고 의심하지 않는 로봇을 속이기 위해 의도적으로 정교한 크롤러 루프를 생성할 수 있습니다.
-
특히 일반적인 파일처럼 보이지만 실제로는 게이트웨이 응용 프로그램인 URL을 게시하는 것은 쉽습니다.
-
이 응용 프로그램은 동일한 서버에 대한 가상의 URL과 연결된 링크가 포함된 HTML을 즉시 생성할 수 있습니다.
-
가상의 URL에 대한 요청이 오면 악성 서버는 새로운 가상 URL을 가진 새로운 HTML 페이지를 만들어냅니다.
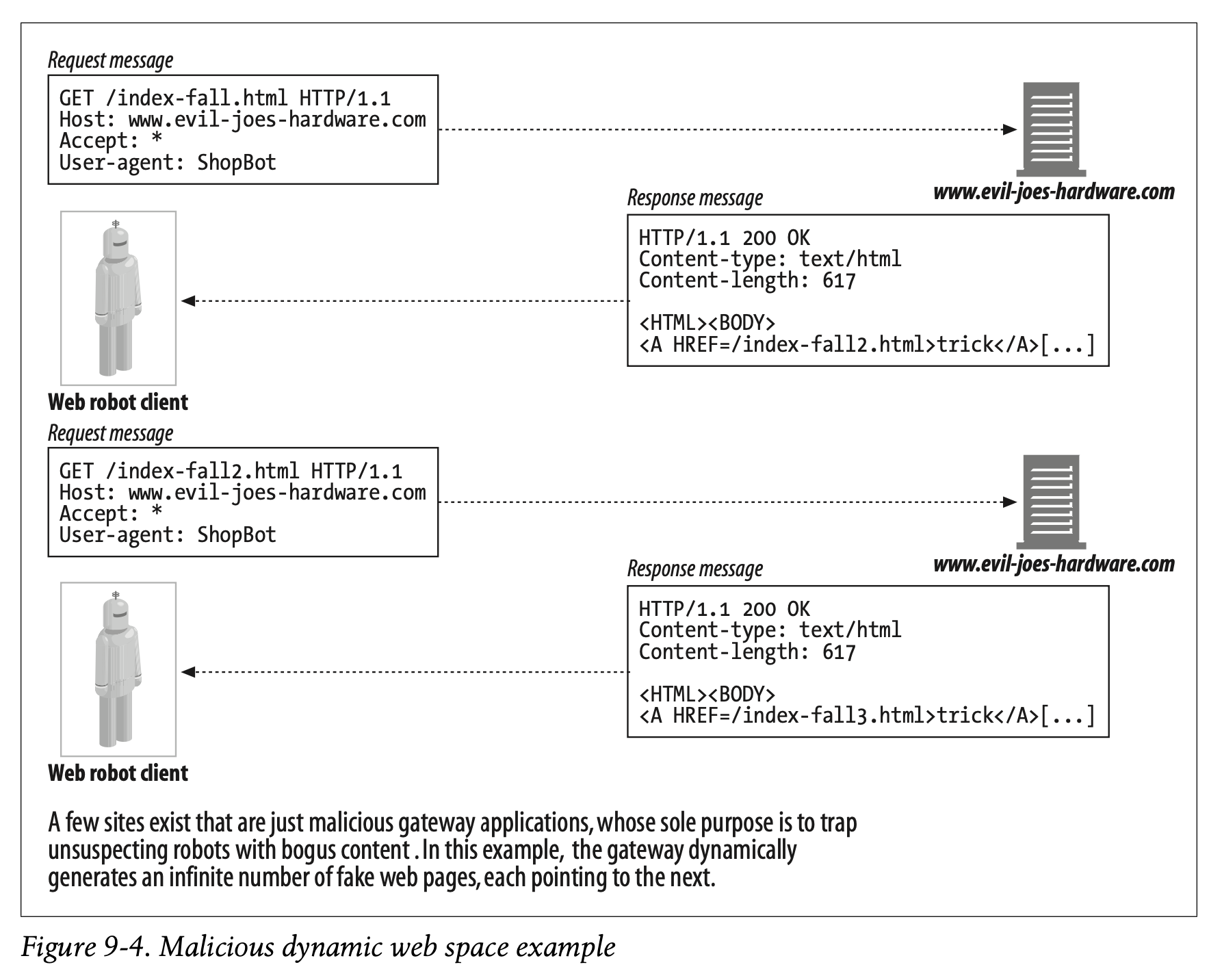
The malicious web server can take the poor robot on an Alice-in-Wonderland journey through an infinite virtual web space, even if the web server doesn’t really contain any files. Even worse, it can make it very difficult for the robot to detect the cycle, because the URLs and HTML can look very different each time. Figure 9-4 shows an example of a malicious web server generating bogus content.
-
악의적인 웹 서버는 가엾은 로봇이 이상한 나라의 앨리스처럼 무한한 가상의 웹 공간을 누비게 합니다.
-
웹 서버가 실제로 아무 파일도 포함하고 있지 않더라도 말입니다.
-
더 심각한 것은 URL과 HTML이 매번 다르기 때문에 로봇이 사이클을 감지하기 어렵다는 점입니다.
-
Figure 9-4는 가짜 콘텐츠를 생성하는 악의적인 웹 서버를 나타냅니다.
More commonly, well-intentioned webmasters may unwittingly create a crawler trap through symbolic links or dynamic content. For example, consider a CGI-based calendaring program that generates a monthly calendar and a link to the next month. A real user would not keep requesting the next-month link forever, but a robot that is unaware of the dynamic nature of the content might keep requesting these resources indefinitely.
-
사실 선의를 가진 웹 마스터가 Symbolic Links나 동적 콘텐츠를 통해 의도치 않게 크롤러 트랩을 생성하는 일이 더 많습니다.
-
예를 들어 월별 달력과 다음 달로 연결되는 링크를 생성하는 CGI 기반의 캘린더 프로그램을 가정해봅시다.
-
실제 사용자는 계속해서 다음 달에 대한 링크를 요청하지 않겠지만, 동적 콘텐츠에 대해 알지 못하는 로봇은 리소스를 무한정 요청할 수 있습니다.
Avoiding Loops and Dups
There is no foolproof way to avoid all cycles. In practice, well-designed robots need to include a set of heuristics to try to avoid cycles.
-
모든 사이클을 회피할 수 있는 완벽한 방법은 없습니다.
-
하지만 실제로 제대로 설계된 로봇은 사이클을 피하기 위해 시도해볼 만한 휴리스틱 집합을 포함할 필요가 있습니다.
Generally, the more autonomous a crawler is (less human oversight), the more likely it is to get into trouble. There is a bit of a trade-off that robot implementors need to make—these heuristics can help avoid problems, but they also are somewhat “lossy,” because you can end up skipping valid content that looks suspect.
-
일반적으로 크롤러가 자동화 될수록(인간의 개입이 적을수록) 문제가 발생할 위험이 높습니다.
-
때문에 로봇 개발자가 고려해야 하는 약간의 trade-off가 있습니다.
-
휴리스틱은 문제를 회피하도록 도와줄 수 있지만 그럼에도 손실이 있음을 감안해야 합니다.
-
의심스러워 보이지만 실제로 유효한 콘텐츠를 그냥 지나칠 수 있기 때문입니다.
Some techniques that robots use to behave better in a web full of robot dangers are:
- 위험으로 가득한 웹 상에서 로봇이 더 잘 동작하기 위해 사용하는 몇 가지 기술들에 대해 지금부터 소개합니다.
Canonicalizing URLs
Avoid syntactic aliases by converting URLs into standard form.
Canonicalizing URLs
- URL을 표준형으로 변환하여 문법적인 Alias를 회피합니다.
Breadth-first crawling
Crawlers have a large set of potential URLs to crawl at any one time. By scheduling the URLs to visit in a breadth-first manner, across web sites, you can minimize the impact of cycles. Even if you hit a robot trap, you still can fetch hundreds of thousands of pages from other web sites before returning to fetch a page from the cycle. If you operate depth-first, diving head-first into a single site, you may hit a cycle and never escape to other sites.
Breadth-first crawling
-
크롤러는 한 번에 크롤링 할 수 있는 거대한 URL 집합을 가지고 있습니다.
-
웹 사이트를 따라 Breadth-first(너비 우선) 방식으로 방문할 URL을 스케줄링함으로써 사이클의 영향을 최소화할 수 있습니다.
-
로봇 트랩에 걸리더라도 사이클을 돌아올 때까지 여전히 다른 웹 사이트로부터 수십만 개의 페이지를 불러올 수 있습니다.
-
만약 Depth-first(깊이 우선) 탐색을 수행한다면 보이는 사이트로 곧장 들어가게 됩니다.
-
따라서 사이클을 만나면 다른 사이트로 빠져나가지 못할 수 있습니다.
Throttling
Limit the number of pages the robot can fetch from a web site in a period of time. If the robot hits a cycle and continually tries to access aliases from a site, you can cap the total number of duplicates generated and the total number of accesses to the server by throttling.
Throttling
-
로봇이 일정 시간 동안 웹 사이트에서 불러올 수 있는 페이지의 개수를 제한합니다.
-
로봇이 사이클에 빠져 지속적으로 사이트의 Alias에 접근하려고 시도한다면 Throttling을 통해 생성되는 전체 Duplicate의 수와 서버에 대한 액세스 횟수를 제한할 수 있습니다.
** Duplicates : 크롤러가 불러오는 중복 페이지
** Throttling : 리소스의 사용을 제한하거나 제어하는 것
Limit URL size
The robot may refuse to crawl URLs beyond a certain length (1KB is common). If a cycle causes the URL to grow in size, a length limit will eventually stop the cycle. Some web servers fail when given long URLs, and robots caught in a URL-increasing cycle can cause some web servers to crash. This may make webmasters misinterpret the robot as a denial-of-service attacker.
As a caution, this technique can certainly lead to missed content. Many sites today use URLs to help manage user state (for example, storing user IDs in the URLs referenced in a page). URL size can be a tricky way to limit a crawl; however, it can provide a great flag for a user to inspect what is happening on a particular site, by logging an error whenever requested URLs reach a certain size.
Limit URL size
-
로봇이 일정 길이(보통 1KB)를 초과하는 URL을 크롤링하는 것을 차단할 수 있습니다.
-
사이클로 인해 URL의 길이가 계속 늘어난다면 결국 길이 제한으로 사이클이 멈추게 될 것입니다.
-
일부 웹 서버는 길이가 긴 URL이 주어졌을 때 Fail 처리되며, URL이 길어지는 사이클에 빠진 로봇은 일부 웹 서버와 충돌을 일으킬 수 있습니다.
-
때문에 웹 마스터가 로봇을 서비스 중단 공격자로 오인할지도 모릅니다.
-
주의할 점은 이 기술이 콘텐츠 일부를 누락시킬 수 있다는 점입니다.
-
오늘날의 많은 사이트가 사용자의 상태를 관리할 수 있게 하는 URL을 사용하고 있습니다(페이지에서 참조하는 URL에 사용자의 ID를 저장하는 등).
-
URL의 길이는 크롤링을 제한하는 까다로운 방법이 되기도 합니다.
-
하지만 요청받은 URL이 특정 크기에 도달할 때마다 에러 로그를 기록함으로써 특정 사이트에서 어떤 일이 발생하고 있는지 사용자가 확인할 수 있게 하는 좋은 수단을 제공합니다.
URL/site blacklist
Maintain a list of known sites and URLs that correspond to robot cycles and traps, and avoid them like the plague. As new problems are found, add them to the blacklist.
This requires human action. However, most large-scale crawlers in production today have some form of a blacklist, used to avoid certain sites because of inherent problems or something malicious in the sites. The blacklist also can be used to avoid certain sites that have made a fuss about being crawled.
URL/site blacklist
-
로봇 사이클과 트랩으로 알려진 사이트와 URL의 리스트를 관리하여 전염병처럼 피해 다닙니다.
-
새로운 문제가 발견되면 블랙리스트에 사이트를 추가합니다.
-
이것은 인간의 개입이 필요합니다.
-
그러나 오늘날 대부분의 대규모 상용 크롤러는 블랙리스트를 사용하고 있습니다.
-
선천적인 결함이나 악의적인 요소를 가진 특정 사이트를 회피하기 위함입니다.
-
블랙리스트를 사용하면 크롤링으로 소란을 일으킨(아마도 법적 소송이나 기술적인 방어 조치 등을 이야기하는 듯하다) 특정 사이트 또한 회피할 수 있습니다.
✏️ 요약
Dynamic Virtual Web Spaces
: 게이트웨이 응용 프로그램을 통해 가상의 URL 링크를 포함한 HTML을 지속적으로 생성하는 무한한 가상 웹 공간
- 로봇을 속이기 위한 크롤러 루프로 사용
- URL과 HTML이 매번 다르기 때문에 사이클을 감지하기 어려움
Heuristics to Avoid Loops
[1] Alias 회피
- Cacnonicalizing URLs
- URL을 표준형으로 변환하여 문법상의 Alias 회피
[2] Breadth-first 방식 사용
- 크롤링할 URL 집합을 Breadth-first로 스케줄링
- FIFO -> 트랩에 걸리더라도 사이클이 돌 때까지 다른 웹 사이트로부터 수십만 개의 페이지를 더 불러올 수 있음
[3] Throttling
- 로봇이 일정 시간 동안 웹에서 불러올 수 있는 페이지 개수 제한
- 서버에 대한 액세스 횟수 제한
[4] URL 길이 제한
- 일정 길이를 초과하는 URL을 크롤링하는 것을 차단
- URL이 특정 길이에 도달할 때마다 에러 로그를 기록할 수 있음
- 길이가 길지만 유효한 URL이 주어졌을 때 Fail 처리될 수 있음
- 로봇을 서비스 중단 공격자로 오인할 가능성이 있음
[5] 블랙리스트 생성
- 로봇 트랩으로 알려진 사이트와 URL의 리스트를 별도 관리 (인간 개입)
- 선천적 결함이나 악의적인 요소를 가진 사이트 회피 가능
- 대부분의 상용 크롤러에서 사용
✏️ 감상
BFS 쓰는 거 좀 똑똑하다
어차피 리스트에 있는 모든 URL을 탐색해야 하는 거라면 DFS를 쓰든 BFS를 쓰든 별로 상관 없겠지...? 라고 생각했지만 착각이었다. 크롤링은 루프가 발생할 위험이 있기 때문에 방문 순서가 매우 중요하다. 그리고 URL을 스택으로 관리하냐 큐로 관리하냐에 따라 어떤 URL을 우선 방문할지가 달라진다. 탐색 방식만 잘 선택해도 효율이 대폭 상승한다는 것이다.
HTTP에 대해서 공부하고 있다고 해서 HTTP만 알려고 하면 안 된다는 것을 많이 느끼고 있다. 이 책은 그간 배운 컴퓨터 구조론과 자료구조 및 알고리즘, OS에 대한 지식을 총동원해서 읽어야 더욱 가치가 있는 것 같다.
