
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Search Engines
The most wide spread web robots are used by Internet search engines. Internet search engines allow users to find documents about any subject all around the world.
-
인터넷 검색엔진에 사용되는 로봇이 가장 널리 알려져 있습니다.
-
검색엔진은 전 세계의 모든 주제에 대한 문서를 찾아냅니다.
Many of the most popular sites on the Web today are search engines. They serve as a starting point for many web users and provide the invaluable service of helping users find the information in which they are interested.
-
오늘날 대부분의 인기 웹 사이트들이 검색엔진에 해당합니다.
-
많은 사용자가 웹 서핑을 시작하는 지점이자 원하는 정보를 알려주는 가치 있는 서비스기도 합니다.
Web crawlers feed Internet search engines, by retrieving the documents that exist on the Web and allowing the search engines to create indexes of what words appear in what documents, much like the index at the back of this book. Search engines are the leading source of web robots—let’s take a quick look at how they work.
-
웹 크롤러는 인터넷 검색엔진에 정보를 제공합니다.
-
웹 상에 존재하는 문서를 수집하여 검색엔진이 어떤 문서에 어떤 단어가 나타나고 있는지에 관한 인덱스를 생성할 수 있게 합니다.
-
마치 이 책의 뒷부분에 있는 인덱스와 같습니다.
-
검색엔진은 웹 로봇의 주요한 소스입니다.
-
지금부터 검색엔진이 어떻게 동작하는지 간단히 살펴봅시다.
Think Big
When the Web was in its infancy, search engines were relatively simple databases that helped users locate documents on the Web. Today, with the billions of pages accessible on the Web, search engines have become essential in helping Internet users find information. They also have become quite complex, as they have had to evolve to handle the sheer scale of the Web.
-
웹이 복잡하지 않았을 때는 검색엔진이 사용자에게 웹 상의 문서 위치를 알려주는 상대적으로 간단한 데이터베이스였습니다.
-
하지만 오늘날에는 웹 상에서 수십억 개의 페이지에 접근할 수 있습니다.
-
인터넷 사용자가 정보를 찾기 위해서 검색엔진이 반드시 필요하게 되었습니다.
-
대규모의 웹을 처리해야 했기 때문에 검색엔진은 꽤 복잡해지기 시작합니다.
With billions of web pages and many millions of users looking for information, search engines have to deploy sophisticated crawlers to retrieve these billions of web pages, as well as sophisticated query engines to handle the query load that millions of users generate.
-
수십억 개의 웹 페이지와 검색을 시도하는 수백만 명의 사용자가 있습니다.
-
검색엔진은 수백만의 사용자가 생성하는 쿼리를 처리하기 위해 정교한 쿼리 엔진을 구축할 뿐만 아니라 정교한 크롤러를 배포하여 수십 억개의 웹 페이지를 수집할 필요가 있습니다.
Think about the task of a production web crawler, having to issue billions of HTTP queries in order to retrieve the pages needed by the search index. If each request took half a second to complete (which is probably slow for some servers and fast for others*), that still takes (for 1 billion documents):
0.5 seconds × (1,000,000,000) / ((60 sec/day) × (60 min/hour) × (24 hour/day))which works out to roughly 5,700 days if the requests are made sequentially! Clearly, large-scale crawlers need to be more clever, parallelizing requests and using banks of machines to complete the task. However, because of its scale, trying to crawl the entire Web still is a daunting challenge.
-
상용 크롤러가 수행해야 하는 작업에 대해 생각해봅시다.
-
검색 인덱스에 추가할 페이지를 불러오기 위해 수십억 개의 HTTP 쿼리를 날릴 것입니다.
-
각각의 요청이 연쇄적으로 발생하고 완료하는 데 0.5초가 걸리고 가정한다면 약
0.5 seconds × (1,000,000,000) / ((60 sec/day) × (60 min/hour) × (24 hour/day))초, 즉 5700일이 소요될 것입니다. -
분명 대규모 크롤러는 요청을 병렬로 전송하거나 작업을 완수하기 위해 여러 대의 컴퓨터를 동원하는 등 더 현명한 방식을 요구할 것입니다.
-
하지만 방대한 규모로 인해 전체 웹을 크롤링하려는 시도는 여전히 어려운 과제로 남아 있습니다.
Modern Search Engine Architecture
Today’s search engines build complicated local databases, called “full-text indexes,” about the web pages around the world and what they contain. These indexes act as a sort of card catalog for all the documents on the Web.
-
오늘날의 검색엔진은 "full-text index"라고 불리는 복잡한 로컬 데이터베이스를 구축합니다.
-
전 세계에 있는 웹 페이지와 각각의 페이지가 포함하고 있는 내용에 대해 기록하고 있습니다.
-
인덱스는 웹 상에 존재하는 모든 문서에 대한 일종의 카드 카탈로그 역할을 수행합니다.
Search-engine crawlers gather up web pages and bring them home, adding them to the full-text index. At the same time, search-engine users issue queries against the full-text index through web search gateways such as HotBot (http://www.hotbot.com) or Google (http://www.google.com). Because the web pages are changing all the time, and because of the amount of time it can take to crawl a large chunk of the Web, the full-text index is at best a snapshot of the Web.
-
검색엔진 크롤러는 웹 페이지를 수집하여 홈으로 가져온 후, full-text index에 추가합니다.
-
동시에 검색엔진 사용자는 HotBot이나 Google과 같은 웹 검색 게이트웨이를 통해 full-text index에 쿼리를 요청합니다.
-
웹 페이지는 실시간으로 변하고 있으며 거대한 웹을 크롤링하는 데는 많은 시간이 소요됩니다.
-
따라서 full-text index는 기껏해야 웹의 스냅샷에 불과합니다.
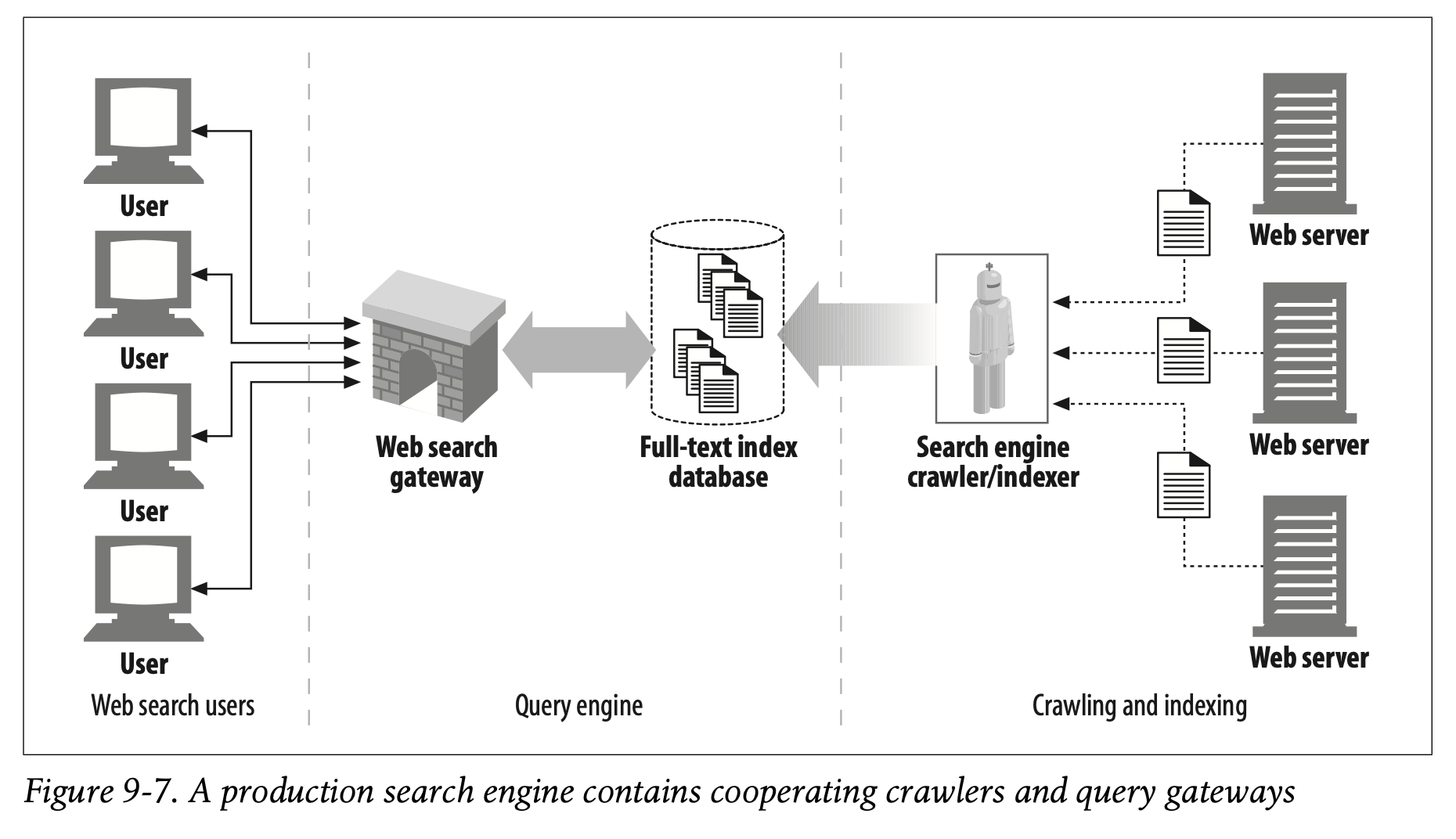
The high-level architecture of a modern search engine is shown in Figure 9-7.
- 현대적인 검색엔진의 high-level 아키텍처는 Figure 9-7에 나타난 것과 같습니다.
Full-Text Index
A full-text index is a database that takes a word and immediately tells you all the documents that contain that word. The documents themselves do not need to be scanned after the index is created.
-
full-text index는 단어를 입력하면 해당 단어가 포함된 모든 문서를 즉시 반환하도록 되어 있습니다.
-
인덱스가 생성된 이후에는 문서 자체를 스캔할 필요가 없습니다.
Figure 9-8 shows three documents and the corresponding full-text index. The full-text index lists the documents containing each word.
-
Figure 9-8은 세 개의 문서와 그에 상응하는 full-text index를 제시합니다.
-
full-text index는 각각의 단어를 포함하고 있는 문서의 목록을 나열하고 있습니다.
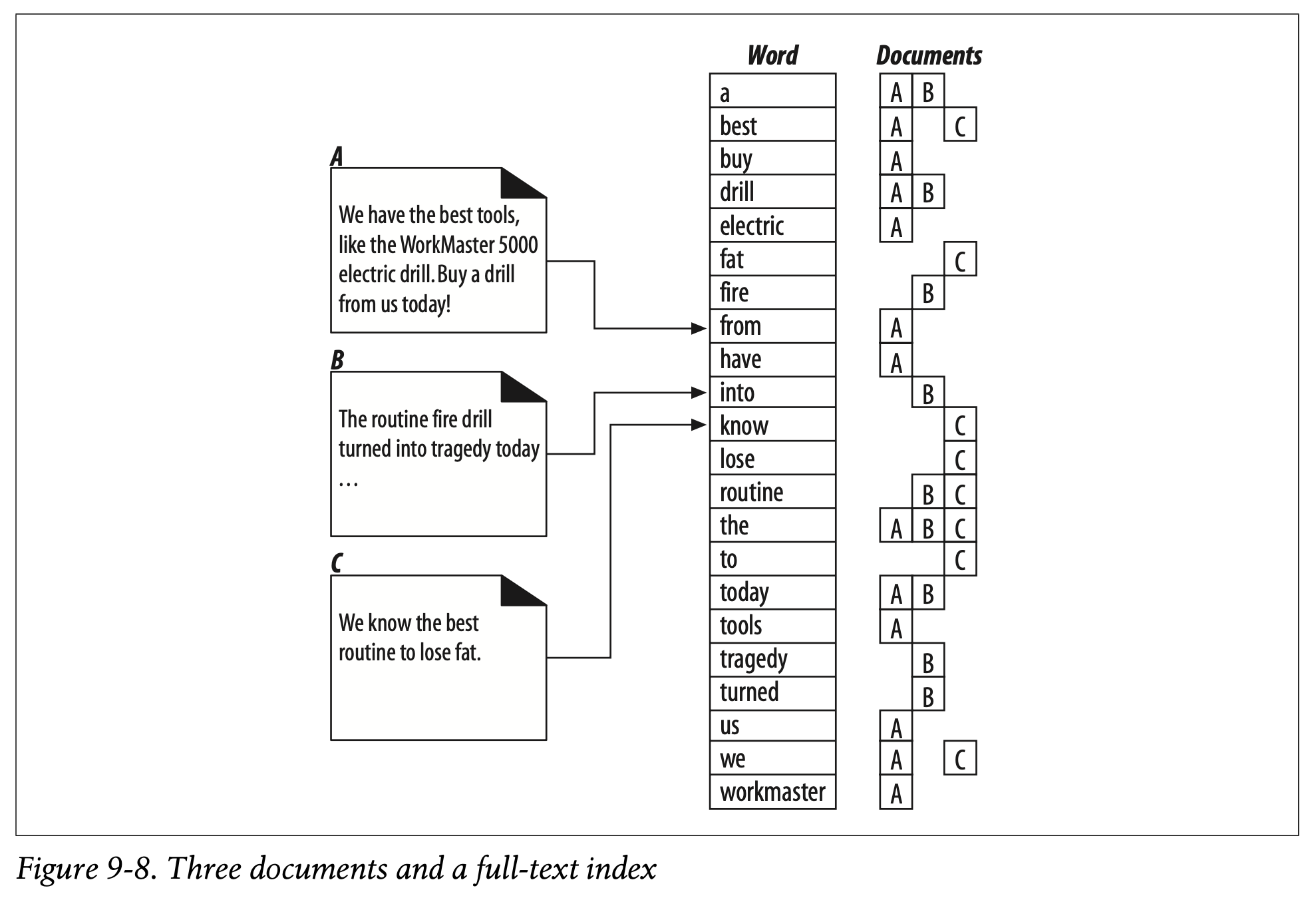
For example:
• The word “a” is in documents A and B.
• The word “best” is in documents A and C.
• The word “drill” is in documents A and B.
• The word “routine” is in documents B and C.
• The word “the” is in all three documents, A, B, and C.
- 예를 들면 이렇습니다.
- "a"는 A와 B 문서에 존재합니다.
- "best"는 A와 C 문서에 존재합니다.
- "drill"은 A와 B 문서에 존재합니다.
- "routine"은 B와 C 문서에 존재합니다.
- "the"는 A, B, C 문서에 모두 존재합니다.
✏️ 요약
Full-text Index
: 전 세계의 웹 페이지와 각각의 페이지가 포함하고 있는 내용에 대해 저장한 데이터베이스
- 수집 : 검색엔진 크롤러가 페이지를 수집하여 스냅샷을 Full-text Index에 저장
- 검색 : 사용자가 웹 검색 게이트웨이(ex. Google)를 통해 Full-text Index에 쿼리 요청 -> 사용자가 입력한 단어가 포함된 모든 문서를 반환
✏️ 감상
Inverted Index (역색인)
인덱스는 대개 키를 입력하면 그것에 해당하는 값을 반환하는 형태다. 반면 Full-text Index는 문서가 포함하고 있는 값인 "단어"를 입력하면 키에 해당하는 "문서"를 반환한다. Full-text Index와 같이 결과를 역으로 반환하는 형태를 역색인, 역인덱스라고 부른다.
사용자는 특정 단어와 연관된 문서가 빠른 속도로 반환되기를 원한다. 만약 역색인을 사용하지 않는다면 원하는 결과를 얻기까지 상당히 오랜 시간이 걸리게 될 것이다. 그 이유는 아래와 같은 RDBMS 쿼리를 생각해보면 간단하다.
SELECT id
FROM documents
WHERE content LIKE '%keyword%'위의 쿼리는 keyword가 포함된 문서를 찾기 위해 모든 행에 대해 LIKE를 수행한다. 데이터베이스에 존재하는 문서의 양이 얼마나 많은데 이걸 한땀한땀 비교하기에는 너무 많은 시간과 노력이 필요하지 않겠는가.
따라서 상용 DBMS에서는 역색인을 생성할 수 있는 수단을 제공하고 있다. MySQL에서는 FULLTEXT INDEX를 사용하여 역색인을 구축하는 방법을 제공하고 있다. 처음 테이블을 생성할 때부터 역색인을 만들 수도 있고 나중에 따로 추가할 수도 있다.
역색인 생성
CREATE FULLTEXT INDEX findex ON documents (content)
역색인 삭제
DROP INDEX findex ON documents
역색인을 통해 데이터를 검색할 때는 MATCH()와 AGAINST() 메서드를 사용하면 된다. MATCH의 인자는 역색인을 생성한 열의 이름이며, AGAINST의 인자는 검색하고자 하는 단어다.
데이터 검색 (1)
SELECT * FROM documents WHERE MATCH(content) AGAINST('HTTP')
(1)은 문서의 내용이 정확히 "HTTP"와 일치하는 것만 반환한다. 하지만 우리가 원하는 것은 "HTTP"를 포함한 모든 문서를 반환하는 것이다. 이때는 BOOLEAN MODE를 적절히 사용해주어야 한다. BOOLEAN MODE는 다양한 연산자를 통해 검색의 자유도를 높인다.
데이터 검색 (2)
SELECT * FROM documents WHERE MATCH(content) AGAINST("HTTP" IN BOOLEAN MODE)
큰따옴표는 역색인에서 "HTTP"라는 구문이 들어간 모든 문서를 찾아오게 하는 연산자다. 그 외에도 연산자의 종류가 꽤 많지만 여기서는 한 가지만 적어보겠다.
감상을 쓰면서 역색인에 관한 티스토리 게시글을 하나 읽었는데, 여기서 새로 알게 된 정보가 정말 많다. 시간이 있다면 블로그에 들어가서 역색인에 대해 자세히 알아보는 것도 좋겠다. 검색 API를 구현해야 하는 상황이 왔을 때 속도를 최적화할 수 있는 좋은 무기가 될 것이다.
