
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Posting the Query
When a user issues a query to a web search-engine gateway, she fills out an HTML form and her browser sends the form to the gateway, using an HTTP GET or POST request. The gateway program extracts the search query and converts the web UI query into the expression used to search the full-text index.
-
웹 검색엔진 게이트웨이에 쿼리를 요청할 때 사용자는 브라우저에서 HTML 폼을 작성하여 HTTP GET 혹은 POST 요청을 전송합니다.
-
게이트웨이 프로그램은 검색 쿼리를 추출한 후 웹 UI에서 생성한 쿼리를 full-text index에서 사용하는 형태로 변환합니다.
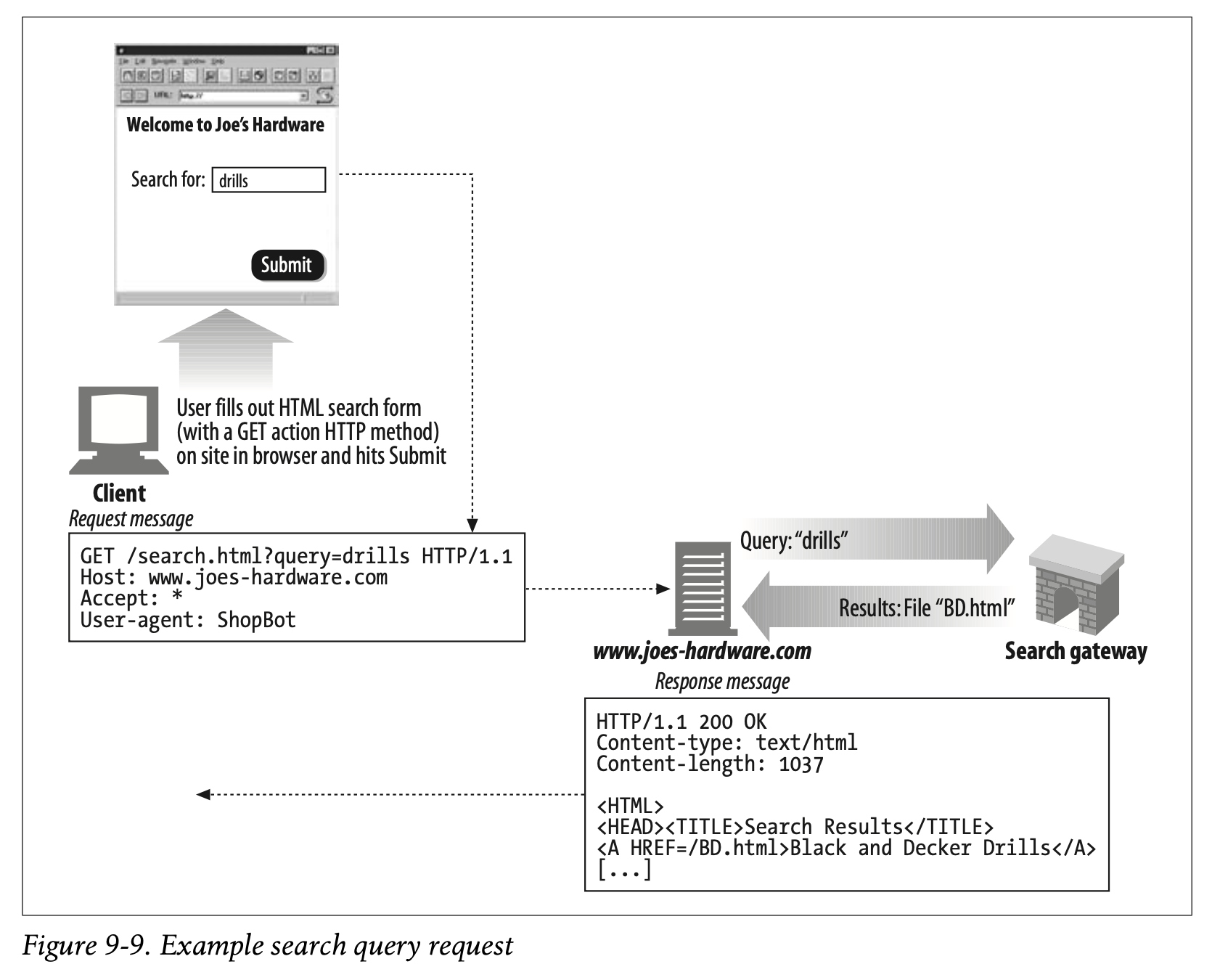
Figure 9-9 shows a simple user query to the www.joes-hardware.com site. The user types “drills” into the search box form, and the browser translates this into a GET request with the query parameter as part of the URL.† The Joe’s Hardware web server receives the query and hands it off to its search gateway application, which returns the resulting list of documents to the web server, which in turn formats those results into an HTML page for the user.
-
Figure 9-9는 www.joes-hardware.com 사이트에 대한 간단한 사용자 쿼리를 나타냅니다.
-
사용자가 검색창에 "drills"라고 입력하면 브라우저가 이것을 URL의 쿼리 파라미터와 함께 GET 요청으로 변환합니다.
-
Joe's Hardware의 웹 서버는 쿼리를 받으면 검색 게이트웨이 응용 프로그램에 전달합니다.
-
게이트웨이는 결과로 나온 문서의 목록을 웹 서버에 전달합니다.
-
이것은 사용자에게 적합한 HTML로 형식화하여 나타납니다.
Sorting and Presenting the Results
Once a search engine has used its index to determine the results of a query, the gateway application takes the results and cooks up a results page for the end user.
-
검색엔진은 인덱스를 사용하여 쿼리의 결과를 결정합니다.
-
게이트웨이 응용 프로그램은 해당 결과를 불러와 사용자를 위한 페이지를 만들어냅니다.
Since many web pages can contain any given word, search engines deploy clever algorithms to try to rank the results. For example, in Figure 9-8, the word “best” appears in multiple documents; search engines need to know the order in which they should present the list of result documents in order to present users with the most relevant results. This is called relevancy ranking—the process of scoring and ordering a list of search results.
-
많은 웹 페이지에 특정 단어가 포함될 수 있으므로 검색엔진은 영리한 알고리즘을 배포하여 결과를 정렬합니다.
-
예를 들어 Figure 9-8에서 "best"라는 단어는 여러 개의 문서에 동시에 나타나고 있습니다.
-
검색엔진은 사용자의 검색어와 가장 연관된 결과를 제시하기 위해 결과 문서들이 보이는 순서를 결정해야 합니다.
-
이것을 연관성 랭킹(Relevancy Ranking)이라고 합니다.
-
검색 결과에 점수를 매기고 정렬하는 과정입니다.
To better aid this process, many of the larger search engines actually use census data collected during the crawl of the Web. For example, counting how many links point to a given page can help determine its popularity, and this information can be used to weight the order in which results are presented. The algorithms, tips from crawling, and other tricks used by search engines are some of their most guarded secrets.
-
대규모의 검색엔진은 순위를 더 잘 매기기 위해 실제 웹 크롤링 중에 수집한 인구조사 데이터를 활용합니다.
-
주어진 페이지를 가리키는 링크의 개수를 세어 인기도(Popularity)를 측정합니다.
-
인기도는 결과를 표시할 순서를 결정하는 데 사용됩니다.
-
검색엔진이 사용하는 알고리즘과 크롤링 팁, 기타 기술들은 가장 소중히 여기는 비밀 중 하나입니다.
Spoofing
Since users often get frustrated when they do not see what they are looking for in the first few results of a search query, the order of search results can be important in finding a site. There is a lot of incentive for webmasters to attempt to get their sites listed near the top of the results sections for the words that they think best describe their sites, particularly if the sites are commercial and are relying on users to find
them and use their services.
-
사용자들은 대체로 검색 결과의 앞부분에서 찾고자 하는 정보를 얻지 못하면 신경질을 냅니다.
-
때문에 검색 결과의 순서는 사이트를 찾는 데 중요합니다.
-
특히 사용자가 사이트를 찾아 서비스를 이용하는 것에 의존하는 상업용 사이트들은 자신의 사이트를 가장 잘 나타내는 것처럼 보이는 검색 결과 섹션의 상단에 사이트를 위치시키려고 하는 경우가 많습니다.
This desire for better listing has led to a lot of gaming of the search system and has created a constant tug-of-war between search-engine implementors and those seeking to get their sites listed prominently. Many webmasters list tons of keywords(some irrelevant) and deploy fake pages, or spoofs—even gateway applications that generate fake pages that may better trick the search engines’ relevancy algorithms for particular words.
-
더 나은 검색 결과에 대한 욕구로 인해 검색 시스템을 조작하는 일이 많아졌습니다.
-
검색엔진 구현자와 사이트를 더 많이 노출시키려는 사람들간의 지속적인 줄다리기가 벌어지고 있습니다.
-
많은 웹마스터가 관련성이 없을 수도 있는 수많은 키워드를 나열하고 가짜 페이지를 배포하고 있습니다.
-
심지어는 가짜 페이지를 생성하는 게이트웨이 응용 프로그램을 통해 특정 단어에 대한 검색엔진의 연관성 알고리즘을 속이는 스푸핑까지 배포하고 있습니다.
As a result of all this, search engine and robot implementors constantly have to tweak their relevancy algorithms to better catch these spoofs.
- 따라서 검색엔진과 로봇 구현자는 계속해서 연관성 알고리즘을 조정하여 스푸핑을 보다 잘 잡아낼 수 있도록 해야 합니다.
✏️ 요약
Search Query Request
: 검색 쿼리 요청의 절차
- 사용자가 브라우저에서 HTML 폼 작성
- 검색어를 쿼리 파라미터에 넣어 HTTP 요청(GET/POST) 전송
- 게이트웨이 프로그램이 검색 쿼리를 추출한 후 full-text index가 사용하는 형태로 변환
- 결과로 나온 문서의 목록을 HTML의 형태로 웹 서버에 전달
- 웹 서버가 사용자에게 응답 전달
Relevancy Ranking
: 검색 결과에 점수를 매기고 정렬하는 과정
- 검색어와 가장 연관된 문서를 상단에 제시하기 위해 사용
- 상업용 사이트를 검색 결과 상단에 노출시키기 위해 뒷돈을 먹이는 경우가 있음(?)
- Relevancy Ranking 알고리즘을 속여 가짜 페이지를 생성하는 스푸핑이 발생하기도 함
✏️ 감상
Chapter 9 끝!
길었던 크롤러와의 여정이 여기서 끝이 났다.
솔직히 한 챕터가 끝날 때마다 후련할 걸 기대하지만, 단 한 번도 후련해본 적이 없다. 뒤에 아직도 챕터가 많이 남아있기 때문이다 ㅠㅁㅠ 101번째 글을 쓰고 있는데 아직도 절반을 오지 않았다는 사실이 믿기지 않는다. 페이지로 따지면 거의 딱 절반 정도..? 읽은 것 같지만 갈 길이 멀다.
그래도 재미로 읽는 거고 급할 것도 없으니까 천천히 한 번 끝까지 읽어보겠다. 절반이나 왔는데 끝까지 안 읽는 것도 좀 아깝지 않을까. 오기를 부려서라도 어떻게든 다 읽을 것 같다...ㅋㅋㅋㅋㅋ
