
Chapter 2. URLs and Resources
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
❤️ 원문 번역 ❤️
The Future
URLs are a powerful tool. Their design allows them to name all existing objects and easily encompass new formats. They provide a uniform naming mechanism that can be shared between Internet protocols.
-
URL은 아주 강력한 도구입니다.
-
URL의 설계는 모든 존재하는 객체를 명명하고 새로운 형태를 쉽게 포괄할 수 있게 했습니다.
-
동시에 인터넷 프로토콜 사이에서 공유할 수 있는 단일 작명 매커니즘을 제공합니다.
However, they are not perfect. URLs are really addresses, not true names. This means that a URL tells you where something is located, for the moment. It provides you with the name of a specific server on a specific port, where you can find the resource. The downfall of this scheme is that if the resource is moved, the URL is no longer valid. And at that point, it provides no way to locate the object.
-
그러나 이것이 완벽하지는 않습니다.
-
URL은 실제 주소를 의미하지 실제 이름을 나타내는 것이 아닙니다.
-
URL은 특정 순간 어떤 객체의 위치를 알려줍니다.
-
즉 리소스를 찾을 수 있는 특정 서버의 이름과 특정 포트를 제공합니다.
-
이러한 전략의 단점은 리소스의 위치가 변하면 URL이 더 이상 유효하지 않게 된다는 것입니다.
-
그와 동시에 객체를 가리키는 방법 역시 사라지게 됩니다.
What would be ideal is if you had the real name of an object, which you could use to look up that object regardless of its location. As with a person, given the name of the resource and a few other facts, you could track down that resource, regardless of where it moved.
-
이상적인 방법은 객체의 실제 이름이 있으면 위치에 관계없이 해당 객체를 찾는 데 그것을 활용하는 것입니다.
-
사람과 마찬가지로, 리소스의 이름과 몇 가지 추가 정보가 주어진다면 위치가 바뀌었는지와 관계없이 리소스를 추적할 수 있을 것입니다.
The Internet Engineering Task Force (IETF) has been working on a new standard, uniform resource names (URNs), for some time now, to address just this issue. URNs provide a stable name for an object, regardless of where that object moves (either inside a web server or across web servers).
-
Internet Engineering Task Force (IETF)는 이 문제를 해결하기 위해 새로운 표준인 Uniform Resource Name (URN)을 개발해왔습니다.
-
URN은 객체의 이동 여부(웹 서버 내부에서의 이동이나 웹 서버간의 이동)와 상관없는 안정적인 객체의 이름을 제공합니다.
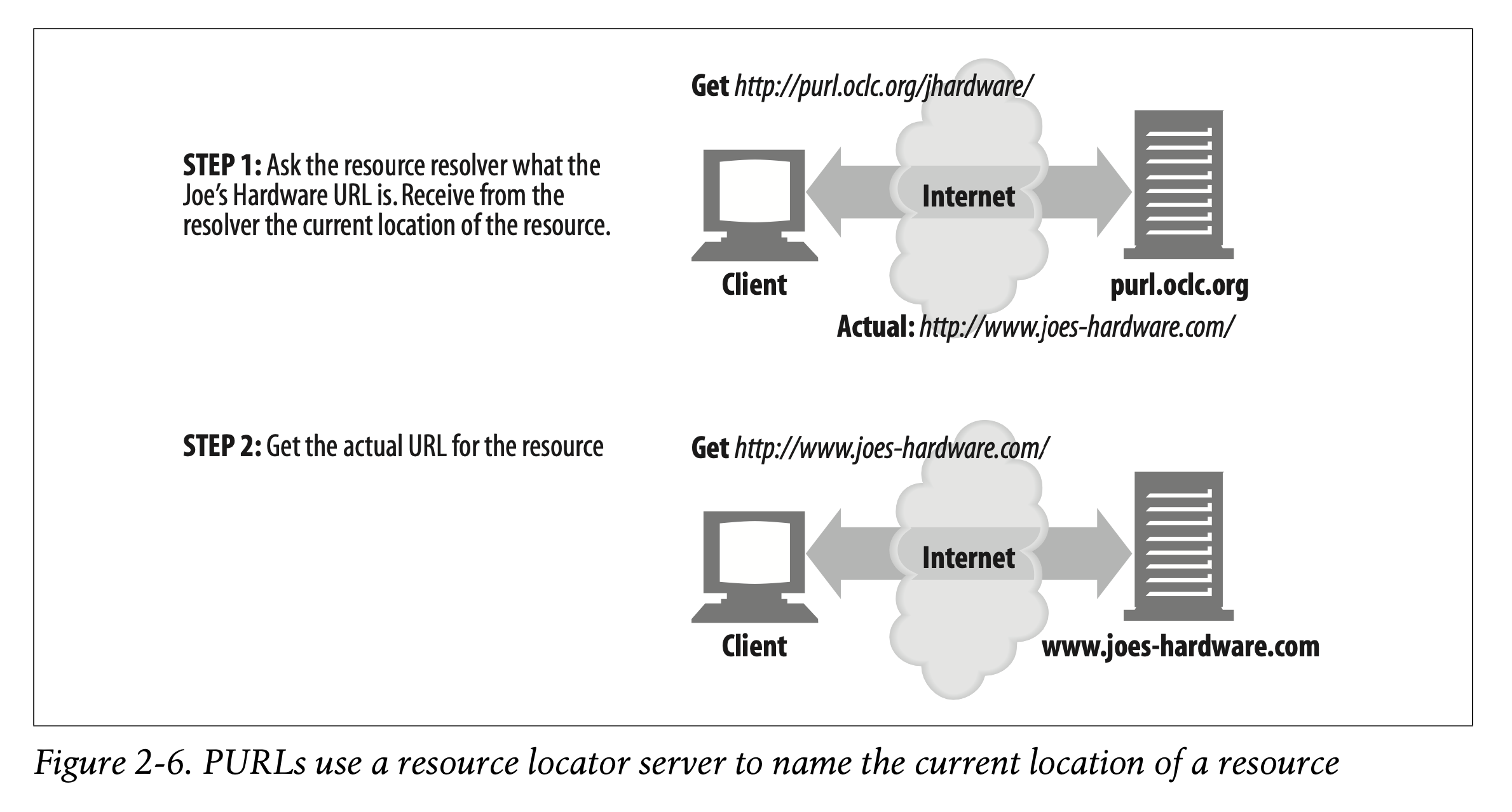
Persistent uniform resource locators (PURLs) are an example of how URN functionality can be achieved using URLs. The concept is to introduce another level of indirection in looking up a resource, using an intermediary resource locator server that catalogues and tracks the actual URL of a resource. A client can request a persistent URL from the locator, which can then respond with a resource that redirects the client to the actual and current URL for the resource (see Figure 2-6). For more information on PURLs, visit http://purl.oclc.org.
-
Persistent Uniform Resource Locators (PURLs)는 URL을 사용하여 URN의 성능을 완성하는 방법을 보여주는 예시입니다.
-
이것은 리소스 탐색에서의 간접성을 위해 추가적인 단계를 도입한다는 개념입니다. 중간 단계에서는 리소스의 실제 URL을 나열하고 추적하는 리소스 로케이터 서버가 사용됩니다.
-
클라이언트는 로케이터로부터 Persistent URL을 요청합니다. 이후 클라이언트를 리소스의 현재 사용중인 실제 URL로 리디렉션(재안내)하는 리소스로 응답합니다. (Figure 2-6)
-
PURL에 대한 더 많은 정보를 알고 싶다면 http://purl.oclc.org를 방문하기 바랍니다.
If Not Now, When?
The ideas behind URNs have been around for some time. Indeed, if you look at the publication dates for some of their specifications, you might ask yourself why they have yet to be adopted.
-
URN에 대한 아이디어는 오랫동안 존재해왔습니다.
-
URN의 명세서가 출판된 날짜를 살펴보면 아직까지 그것이 왜 채택되지 않았는지 의아해할지도 모릅니다.
The change from URLs to URNs is an enormous task. Standardization is a slow process, often for good reason. Support for URNs will require many changes—consensus from the standards bodies, modifications to various HTTP applications, etc. A tremendous amount of critical mass is required to make such changes, and unfortunately (or perhaps fortunately), there is so much momentum behind URLs that it will be some time before all the stars align to make such a conversion possible.
-
URL에서 URN으로의 변환은 거대한 규모의 작업입니다.
-
표준화의 과정은 느리고, 일반적으로 그럴 만한 이유들이 있습니다.
-
URN을 지원하기 위해서는 표준 기관의 합의와 다양한 HTTP 응용 프로그램의 수정 등 많은 변화를 필요로 합니다.
-
이러한 변화를 만들기 위해서는 많은 양의 임계 질량이 필요합니다. 그리고 이것이 불행일지 행운일지 모르지만, URL이라는 별에는 매우 많은 모멘텀이 잠재되어 있기 때문에 모든 URL이 진화하는 데는 오랜 시간이 소요될 것입니다.
(대충 URL이 URN으로 변화하는 과정을 별의 진화에 비유한 것 같다)
Throughout the explosive growth of the Web, Internet users—everyone from computer scientists to the average Internet user—have been taught to use URLs. While they suffer from clumsy syntax (for the novice) and persistence problems, people have learned how to use them and how to deal with their drawbacks. URLs have some limitations, but they’re not the web development community’s most pressing problem.
-
웹의 폭발적인 성장과 함께 컴퓨터 과학자부터 일반인을 포함한 모든 인터넷 사용자들은 URL의 사용법을 배워왔습니다.
-
그들은 (초보자를 위한) 어설픈 구문과 지속성 문제로 골머리를 앓으면서도 URL을 사용하는 방법과 그것의 단점을 해결하는 방법을 학습했습니다.
-
URL은 몇 가지 한계가 있지만, 웹 개발 커뮤니티의 가장 시급한 문제는 아닙니다.
Currently, and for the foreseeable future, URLs are the way to name resources on the Internet. They are everywhere, and they have proven to be a very important part of the Web’s success. It will be a while before any other naming scheme unseats URLs. However, URLs do have their limitations, and it is likely that new standards (possibly URNs) will emerge and be deployed to address some of these limitations.
-
URL은 현재, 그리고 예측할 수 있는 미래에 인터넷의 리소스를 명명하는 수단일 것입니다.
-
이것은 어디에나 존재하며 웹의 성공에 있어 아주 중요한 부분이라는 것이 증명되었습니다.
-
아마도 다른 명명 체계가 URL을 대체하기까지는 시간이 걸릴 것입니다.
-
그러나 URL은 분명 한계점을 가지고 있고, 오늘날의 한계를 극복하기 위해 새로운 표준(아마도 URN)이 나타나 배포될지도 모릅니다.
🧡 요약 정리 🧡
URN
- 웹 서버 내부에서의 이동이나 서버간의 이동 여부와 관계없이 안정적인 객체 이름 제공
- PURLs : 클라이언트가 로케이터에 Persistent URL을 요청하면 리소스의 원본 URL로 리디렉션하는 리소스로 응답하는 방식
- 표준화의 과정과 응용 프로그램의 수정이 복잡하여 아직까지 채택되지 않음
💛 감상 💛
-
어제 업로드 버튼을 누르고 잔다는 게 깜빡하고 그냥 잠들어버렸다. 그래서 오늘은 포스팅이 2개 올라갈 예정이다!
-
새로운 표준이 나타날지도 모른다는 저자의 생각과는 달리 아직까지도 URL이 널리 사용되고 있다. URN은 URL과 달리 객체의 위치와 관계없이 리소스를 나타낼 수 있지만, 지금까지 URL로 만들어진 모든 체계를 뒤집어 엎을 만큼의 메리트가 없는 걸지도 모르겠다. 이미 우리는 URL의 한계를 느끼지 못할 정도로 그것을 편리하게 사용하고 있다. URL로 인한 치명적인 문제를 마주치지 않는 한 굳을대로 굳어져버린 관습을 고칠 이유는 없을 듯하다.
-
41페이지까지 하여 Chapter 2를 마쳤다. 후반부에 짧게 등장하는 For More Information 부분은 참고할 만한 홈페이지 몇 개 적혀있는 게 전부라 건너뛰었다. Chapter 2에서는 주로 URL에 대해 다루었는데, 그동안 유심히 들여다보지 않았던 URL에 대해 자세히 공부할 수 있어 유익한 시간이었다.
