
Chapter 3. HTTP Messages
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
❤️ 원문 번역 ❤️
Preface
If HTTP is the Internet’s courier, HTTP messages are the packages it uses to move things around. In Chapter 1, we showed how HTTP programs send each other messages to get work done. This chapter tells you all about HTTP messages—how to create them and how to understand them. After reading this chapter, you’ll know most of what you need to know to write your own HTTP applications. In particular, you’ll understand:
• How messages flow
• The three parts of HTTP messages (start line, headers, and entity body)
• The differences between request and response messages
• The various functions (methods) that request messages support
• The various status codes that are returned with response messages
• What the various HTTP headers do
-
HTTP가 인터넷의 운송 수단이라면, HTTP 메시지는 물건을 옮기는 데 사용되는 택배 상자입니다.
-
Chapter 1에서 우리는 HTTP 프로그램이 서로 다른 메시지들을 전송하고 작업을 수행하는 방법에 대해 배웠습니다.
-
이번 챕터에서는 HTTP 메시지에 대한 모든 것들을 배울 겁니다. HTTP 메시지를 어떻게 생성하고 어떻게 이해하는지 말입니다.
-
이 챕터를 읽고 난 후 여러분들은 여러분만의 HTTP 애플리케이션을 작성하기 위해 알아야 할 대부분의 내용을 알게 될 겁니다.
-
특히 다음과 같은 것들을 이해하게 됩니다.
- 메시지의 흐름
- HTTP 메시지의 세 가지 부분 (Start Line, Headers, Entity Body)
- 요청과 응답 메시지의 차이점
- 요청 메시지가 지원하는 다양한 메소드
- 응답 메시지로 반환되는 다양한 상태 코드
- HTTP 헤더의 다양한 역할
The Flow of Messages
HTTP messages are the blocks of data sent between HTTP applications. These blocks of data begin with some text meta-information describing the message contents and meaning, followed by optional data. These messages flow between clients, servers, and proxies. The terms “inbound,” “outbound,” “upstream,” and “downstream” describe message direction.
-
HTTP 메시지는 HTTP 애플리케이션 사이에서 전송되는 데이터 블록입니다.
-
이러한 데이터 블록은 메시지의 내용과 의미를 표현하는 몇 가지 텍스트 메타 정보로 시작하여 부가 정보들로 이어집니다.
-
메시지는 클라이언트와 서버, 그리고 프록시 사이에서 흘러갑니다.
-
"inbound(인바운드)", "outbound(아웃바운드)", "upstream(업스트림)", "downstream(다운스트림)"과 같은 용어들은 메시지의 방향을 나타냅니다.
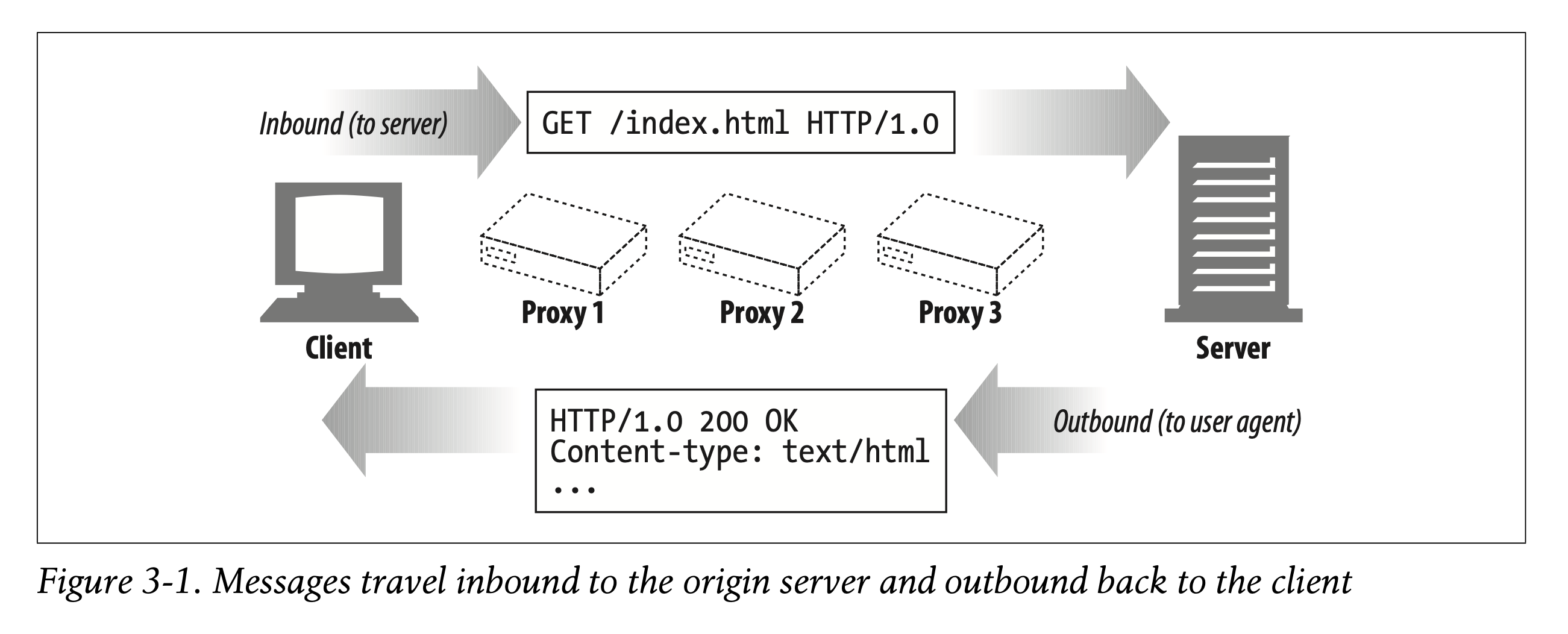
[1] Messages Commute Inbound to the Origin Server
HTTP uses the terms inbound and outbound to describe transactional direction. Messages travel inbound to the origin server, and when their work is done, they travel outbound back to the user agent (see Figure 3-1).
-
HTTP는 트랜잭션의 방향을 설명하기 위해 인바운드와 아웃바운드 개념을 사용합니다.
-
메시지는 Origin 서버 쪽으로 인바운드 이동하고, 작업이 완료되면 아웃바운드로 이동하여 유저 에이전트에게 돌아옵니다. (Figure 3-1)
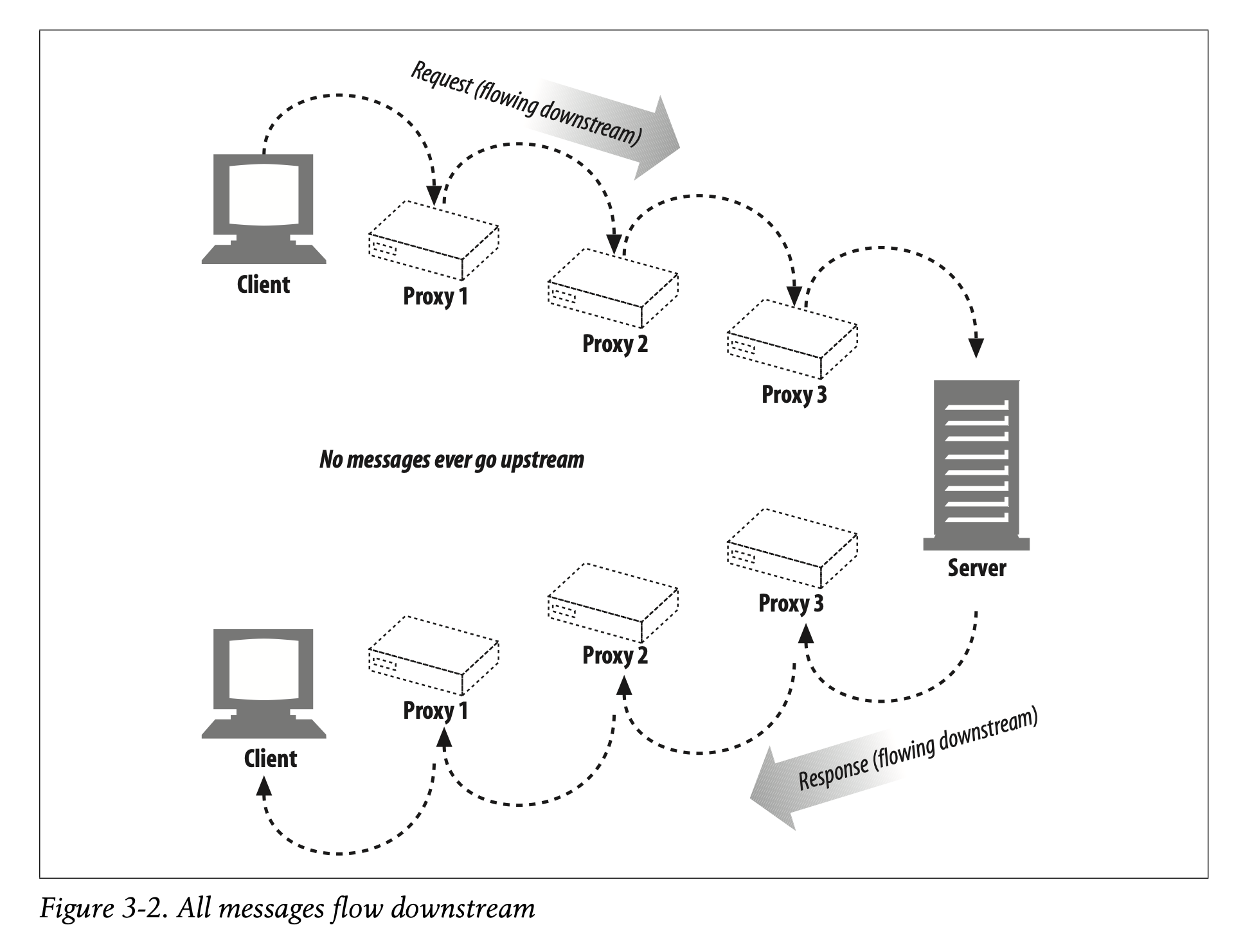
[2] Messages Flow Downstream
HTTP messages flow like rivers. All messages flow downstream, regardless of whether they are request messages or response messages (see Figure 3-2). The sender of any message is upstream of the receiver. In Figure 3-2, proxy 1 is upstream of proxy 3 for the request but downstream of proxy 3 for the response.*
-
HTTP 메시지는 마치 강처럼 흘러갑니다.
-
모든 메시지들은 다운스트림으로 향합니다. 그 메시지가 요청 메시지인지 응답 메시지인지는 중요하지 않습니다. (Figure 3-2)
-
모든 메시지의 송신 장치는 수신 장치의 업스트림입니다.
-
Figure 3-2을 살펴보면, 요청 상황에서 프록시 1은 프록시 3의 업스트림입니다. 반면 응답 상황에서 프록시 1은 프록시 3의 다운스트림입니다.
The Parts of a Message
HTTP messages are simple, formatted blocks of data. Take a peek at Figure 3-3 for an example. Each message contains either a request from a client or a response from a server. They consist of three parts: a start line describing the message, a block of headers containing attributes, and an optional body containing data.
-
HTTP 메시지는 간단하게 정형화된 데이터 블록입니다.
-
예시로 Figure 3-3을 살펴봅시다.
-
각각의 메시지는 클라이언트로부터의 요청이나 서버로부터의 응답을 포함하고 있습니다.
-
메시지는 메시지를 설명하는 '스타트라인', 속성(attribute)을 포함하는 '헤더', 데이터를 포함하는 선택적인 '본문', 이렇게 세 가지로 구성됩니다.
The start line and headers are just ASCII text, broken up by lines. Each line ends with a two-character end-of-line sequence, consisting of a carriage return (ASCII 13) and a line-feed character (ASCII 10). This end-of-line sequence is written “CRLF.” It is worth pointing out that while the HTTP specification for terminating lines is CRLF, robust applications also should accept just a line-feed character. Some older or broken HTTP applications do not always send both the carriage return and line feed.
-
스타트라인과 헤더는 라인으로 구별되는 아스키 텍스트입니다.
-
각각의 라인은 문자 두 개로 이루어진 end-of-line sequence로 종료됩니다. 이때 사용되는 두 문자는 Carriage Return (ASCII 13, CR)과 Line-Feed (ASCII 10, LF)입니다.
-
라인 변환에 대한 HTTP 규정은 CRLF지만, 견고한 응용 프로그램은 LF 문자만으로도 라인 변환을 허용해야 한다는 점을 비판할 필요가 있습니다.
-
몇몇 오래되고 망가진 HTTP 애플리케이션은 항상 CR과 LF 문자를 모두 전송하지 않습니다.
The entity body or message body (or just plain “body”) is simply an optional chunk of data. Unlike the start line and headers, the body can contain text or binary data or can be empty.
-
Entity Body 혹은 Message Body(그냥 "Body(본문)"라고 부르기도 한다)는 단순히 선택적인 데이터 덩어리입니다.
-
스타트라인과 헤더와는 달리 본문은 텍스트나 이진 정보를 포함할 수 있고, 아예 비어있을 수도 있습니다.
In the example in Figure 3-3, the headers give you a bit of information about the body. The Content-Type line tells you what the body is—in this example, it is a plain-text document. The Content-Length line tells you how big the body is; here it is a meager 19 bytes.
-
Figure 3-3에 나온 예시처럼, 헤더는 본문에 대한 약간의 정보만을 제공합니다.
-
Content-Type 라인은 본문이 어떤 것인지를 알려줍니다. 이 예제에서는 Plain-text 문서입니다.
-
Content-Length 라인은 본문의 길이 혹은 크기를 알려줍니다. 여기서는 약 19바이트 정도입니다.

🧡 요약 정리 🧡
Terms
- Inbound(인바운드) : 클라이언트 -> 서버
- Outbound(아웃바운드) : 서버 -> 클라이언트
- Upstream(업스트림) : 송신 장치
- Downsteram(다운스트림) : 수신 장치
The Parts of a Message
- Start Line(스타트라인) : 메시지 설명, 아스키 텍스트
- Header(헤더) : 속성을 비롯한 본문 정보, 아스키 텍스트
** 아스키 텍스트에서 각각의 라인은 CRLF에 의해 구분 가능 - Body(본문) : 선택적인 데이터 정보, 비어있거나 텍스트 및 이진 정보
💛 감상 💛
-
한 챕터를 마치고 새로운 챕터를 시작하는 것은 여러모로 기분 좋은 일이다. 챕터 하나를 완독했다는 성취감, 다음 챕터에 도전하고자 하는 목표 의식, 작심삼일 마인드의 리셋(?) 등... 분명 새로운 시작이 주는 설렘 같은 것이 있다. URL이 지루해지던 참이었는데 이제 HTTP 메시지가 또 색다른 자극을 주기 시작했다.
-
인바운드, 아웃바운드는 항상 볼 때마다 헷갈리는데 서버를 기준으로 생각하면 편할 것 같다. 서버가 리소스를 주고받는 은행이라고 한다면 움직이는 고객은 클라이언트지 서버가 아니다. 그러니까 고객이 은행으로 오는 것은 In Boundary, 나가는 것은 Out Boundary라고 하는 것이 자연스럽다. 클라이언트를 기준으로 생각하면 뭔가 이상해지지 않나. 그렇게 생각하면 기억하기 한결 쉽다.
