프로젝트 소개
소스코드
batch 프로그램에 대한 고민
주기적으로 작동하는 크롤러를 만들기로 결정한 후 처음 들었던 고민은 '어떤 배치 서비스를 사용해야 하나' 하는 것이었다. 백엔드는 spring boot로 개발하고 AWS에 배포할 계획이었기 때문에 높은 통합성을 보이리라고 생각되는 spring batch, AWS batch 등을 검토해보았다.
배치 서비스는 훌륭한 기능들을 다수 제공해주었지만 러닝커브가 생각보다 깊어보였고, 대용량 처리에 적합한 배치 프로그램은 가벼운 트래픽을 예상하는 우리 어플리케이션에는 과할 것 같다는 생각이 들었다. 그래서 배치 서비스를 이용한 프로그램을 만들기보다는 cron 등으로 간단하게 스케줄링하여 주기적으로 작업을 수행할 수 있게 해주는 정도로 구현하기로 했다.
Serverless
Serverless application은 서버 인스턴스 위에 상주하지 않고 필요할 때만 호출되어 경제적이라는 이점이 있으며, 며칠에 한번씩만 크롤링을 수행하는 우리 어플리케이션의 특성은 이 이점과 특히 잘 어울린다고 생각했다. 기본적으로 배치 작업은 사용자와의 기민한 소통을 요구하지 않기 때문에 극한의 성능은 필요 없으며 serverless application의 한계라고 여겨지는 cold start에 관한 문제도 신경쓸 필요가 없어보였다. 따라서 AWS의 Lambda를 이용해 serverless 환경에서 동작하는 크롤러를 만들어보기로 결정했다.
Cloudwatch Trigger
Cloudwatch는 aws에서 제공하는 모니터링 및 관찰 기능 서비스이다. lambda를 trigger할 수 있는 aws 서비스가 몇가지 있는데, cloudwatch는 cron expression을 사용해서 주기적으로 원하는 lambda function을 trigger할 수 있다. 또한 cloudwatch는 lambda function에서 남기는 로그를 쉽게 모니터링할 수 있다는 장점이 있다.
Infrastructure
결론적으로, 학식 정보 크롤러의 인프라 구조는 아래와 같다.
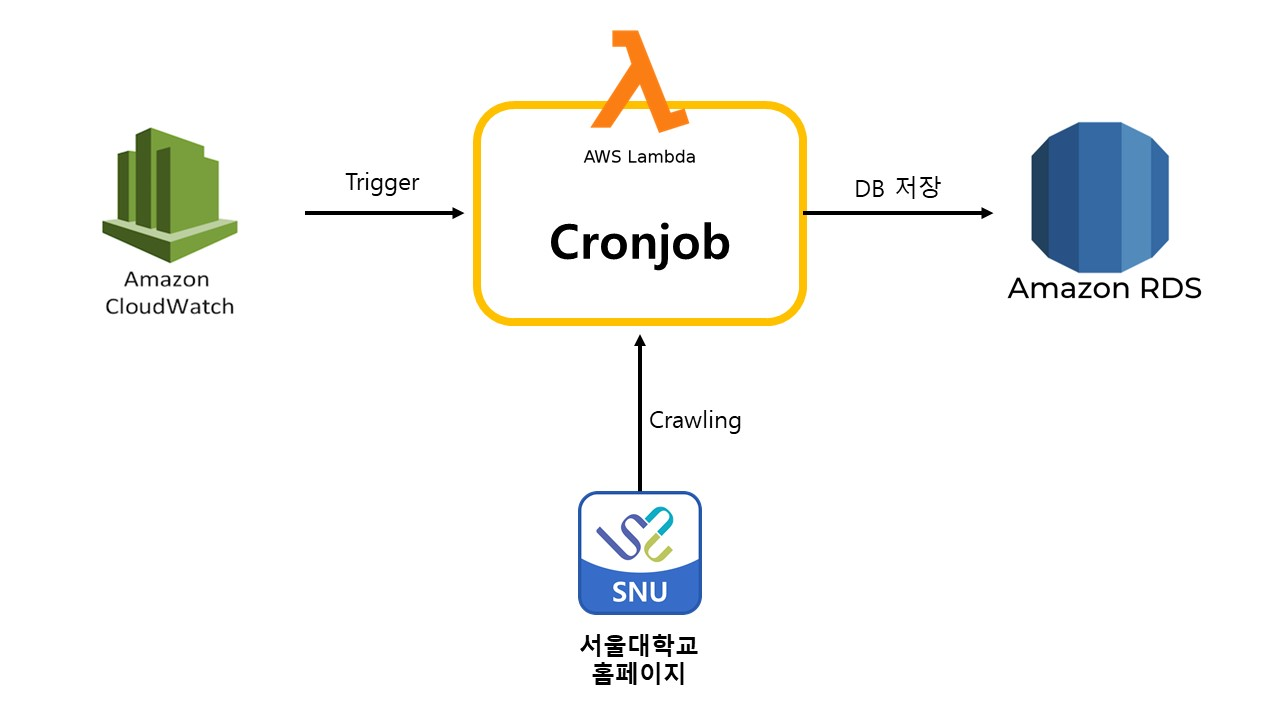
lambda function 만들기
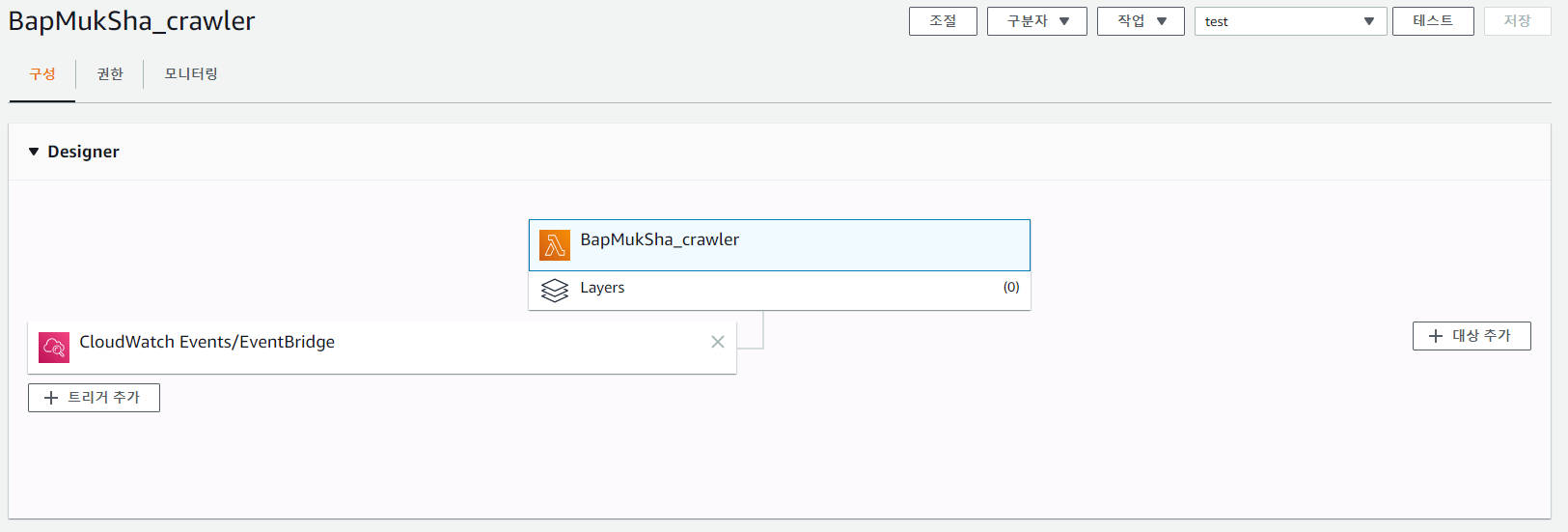
코틀린을 사용해서 크롤러를 만들었기 때문에 runtime 환경은 java 11을 선택했고, 필요한 패키지들을 모두 포함한 단일 jar 파일이 필요했기 때문에 gradle의 shadowJar 플러그인을 추가하고 이를 이용해 빌드했다. (shadowJar 빌드를 하면 비륻 결과물 이름에 all 이라는 suffix가 붙는다.)
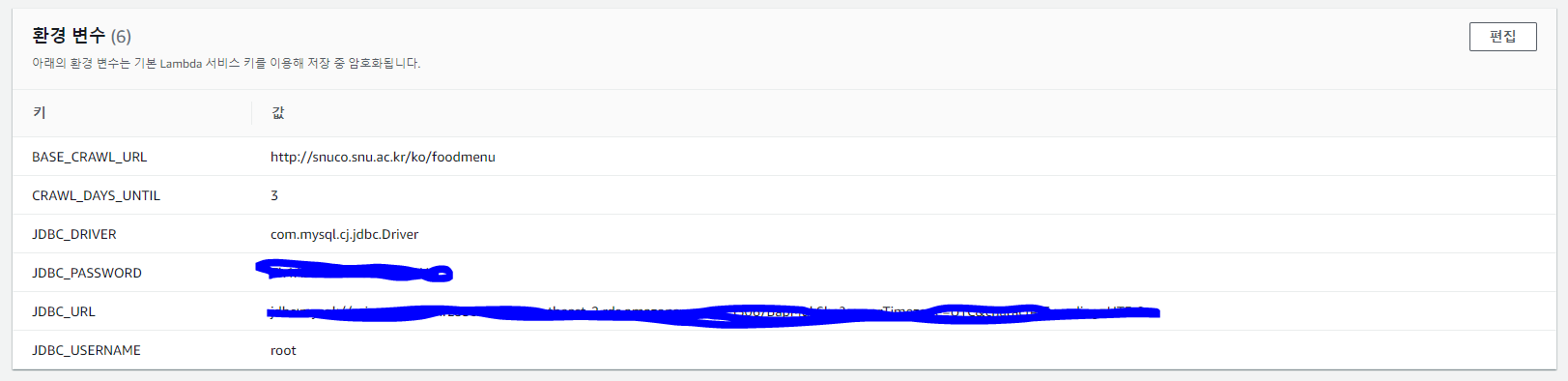
환경에 따라 바뀔 수 있는 값들은 모두 아래와 같이 환경변수화를 해놓았기 때문에, aws console에서 환경변수를 주입해주면 정상적으로 작동할 것을 기대할 수 있다.
class Constants {
companion object {
val BASE_CRAWL_URL: String = System.getenv("BASE_CRAWL_URL") ?: "http://snuco.snu.ac.kr/ko/foodmenu"
val JDBC_URL: String = System.getenv("JDBC_URL") ?: "jdbc:mysql://localhost:3306/test_db?serverTimezone=UTC&characterEncoding=UTF-8"
val JDBC_DRIVER: String = System.getenv("JDBC_DRIVER") ?: "com.mysql.cj.jdbc.Driver"
val JDBC_USERNAME: String = System.getenv("JDBC_USERNAME") ?: "root"
val JDBC_PASSWORD: String = System.getenv("JDBC_PASSWORD") ?: "password"
val CRAWL_DAYS_UNTIL: Int = System.getenv("CRAWL_DAYS_UNTIL")?.toInt() ?: 3
}
}
테스트로 람다 함수를 실행시켜본 결과 정상적으로 작동하는 것을 확인할 수 있었고, cloudwatch를 통해 내가 남긴 로그를 확인할 수 있었다.
RDS에 저장이 잘 되었는지를 mysql workbench에서 확인해본 결과 역시 데이터가 잘 저장되었음을 확인할 수 있었다.

