패스트캠퍼스의 데이터사이언스&딥러닝 강의를 수강하면서 처음으로 해본 프로젝트이다.
사실 프로젝트라고 하기엔 너무나 하찮고, 기초적인 것이지만 처음하는 미니 프로젝트이고, 실제로 배운 코드들과 개념을 써본 사례이기에 기록해본다.
🛳️ Titanic competition of Kaggle
💡 프로젝트 중점사항
- task : 타이타닉의 생존자 예측하기
- 간단한 분류 문제를 통해 분류모델 익히기
- sklearn 라이브러리로 머신러닝 모델 구현하기
- 머신러닝 Workflow 익히기(with fastcamps)
💻 기술스택
- Python
- sklearn
- google colab
- pandas
📥 titanic data source : https://www.kaggle.com/c/titanic1. 타이타닉 데이터 다운로드 받기
- 먼저 kaggle에 들어가서 titanic을 검색을 하면 데이터들을 다운로드 받을 수 있습니다.
- 총 'gender_submission.csv', 'test.csv', 'train.csv' 3개의 파일이 있습니다.
- 다운로드 받은 파일들을 구글드라이브에 저장하는 것이 좋습니다.
2. titanic data 불러오기
import pandas as pd
basepath = "/content/drive/MyDrive/data/titanic/"
train = pd.read_csv(basepath + "train.csv")
test = pd.read_csv(basepath + "test.csv")
submission = pd.read_csv(basepath + 'gender_submission.csv')- 먼저 'pandas' 파이썬 라이브러리를 불러옵니다.
- 'basepath'라는 변수에 타이타닉 데이터 경로를 저장해줍니다.
- 해당 경로는 'titanic'이라는 폴더의 경로이고, 폴더 안에 3개('gender_submission.csv', 'test.csv', 'train.csv')의 파일이 있습니다.
- 'train'과 'test'라는 변수를 생성하고 위에서 저장한 타이타닉 데이터 경로에 파일명들을 붙여 저장해줍니다.
3. Data Preprocessing
1) 결측치 확인 및 처리
2) feature selection(분석에 사용하지 않을 불필요한 column 제거하기)
1) 결측치 확인 및 처리
train[train.isnull().any(axis = 1)]
- train 데이터에서 적어도 하나의 열에 누락된 값(null)이 있는 모든 행을 추출한 것입니다.
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
** 5 Age 714 non-null float64**
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
** 10 Cabin 204 non-null object
** 11 Embarked 889 non-null object**
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB- 각 컬럼의 non-null 개수를 파악하여 결측치를 처리할 컬럼을 추출합니다.
- "Age", "Cabin", "Embarked" 컬럼의 결측치를 처리해야 합니다.
- 먼저 결측값이 가장 적어보이는 "Embarked" 컬럼의 결측값부터 처리해봅시다.
☑️ Emarked column의 결측치 "S"로 처리하기
train[train.Embarked.isnull()]
# train.Embarked.value_counts() -> "S"
train.loc[train.Embarked.isnull(), "Embarked"] = "S"- Embarked column이 NaN인 row를 찾습니다.
- Embarked 컬럼을 기준으로 value 값들의 갯수를 세주었습니다.
- 가장 최빈값인 "S"로 결측치를 처리하는 것이 좋을 것으로 판단됩니다.
- Embarked 컬럼의 결측치들을 "S"로 바꾸어 처리해줍니다.
- 이제 train.info()를 하여 확인해보면 "Embarked" 컬럼의 결측치가 없어졌습니다. 즉, 결측치는 "S"로 변경되어 처리된 것입니다.
<<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object ** 11 Embarked 891 non-null object ** dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
2) feature selection(분석에 사용하지 않을 불필요한 column 제거하기)
- 데이터 처리를 간단하게 하기 위해 예측에는 도움이 안 되는 column들을 판단하여 삭제합니다.
train = train.drop(columns = ['PassengerId', 'Name', 'Ticket', 'Cabin'])
# => 'PassengerId', 'Name', 'Ticket', 'Cabin' 해당 column들은 이번 task와는 상관이 없어 삭제합니다.☑️ "Age" column 결측치 처리하기(평균값 채우기)
train = train.fillna(train.Age.mean())
- train 데이터의 결측값을 "Age" column의 평균값으로 채워줍니다.
- ** 앞에서 "Cabin" column도 결측치가 있어 처리해주어야 했지만 불필요한 컬럼을 제거할 때 "Cabin" 컬럼도 삭제했으므로 "Cabin"의 결측치는 처리해줄 필요가 없습니다.
4. Feature Engineering
1) Categorical feature encoding
2) Normalization
1) Categorical feature encoding
Categorical feature는 두 가지로 나뉩니다.
1. Ordinal Encoding -> Ordinal feature를 변환할 때 쓰임. e.g. 학력, 선호도, ...
2. One-hot Encoding -> Nominal feature를 변환할 때 쓰임. e.g. 성별, 부서, 출신학교, ...❗One-hot Encoding
- Nominal feature를 인코딩 하는 방법으로, 하나의 feature를 0과 1로 이루어진 여러 개 feature로 나누는 방법입니다.
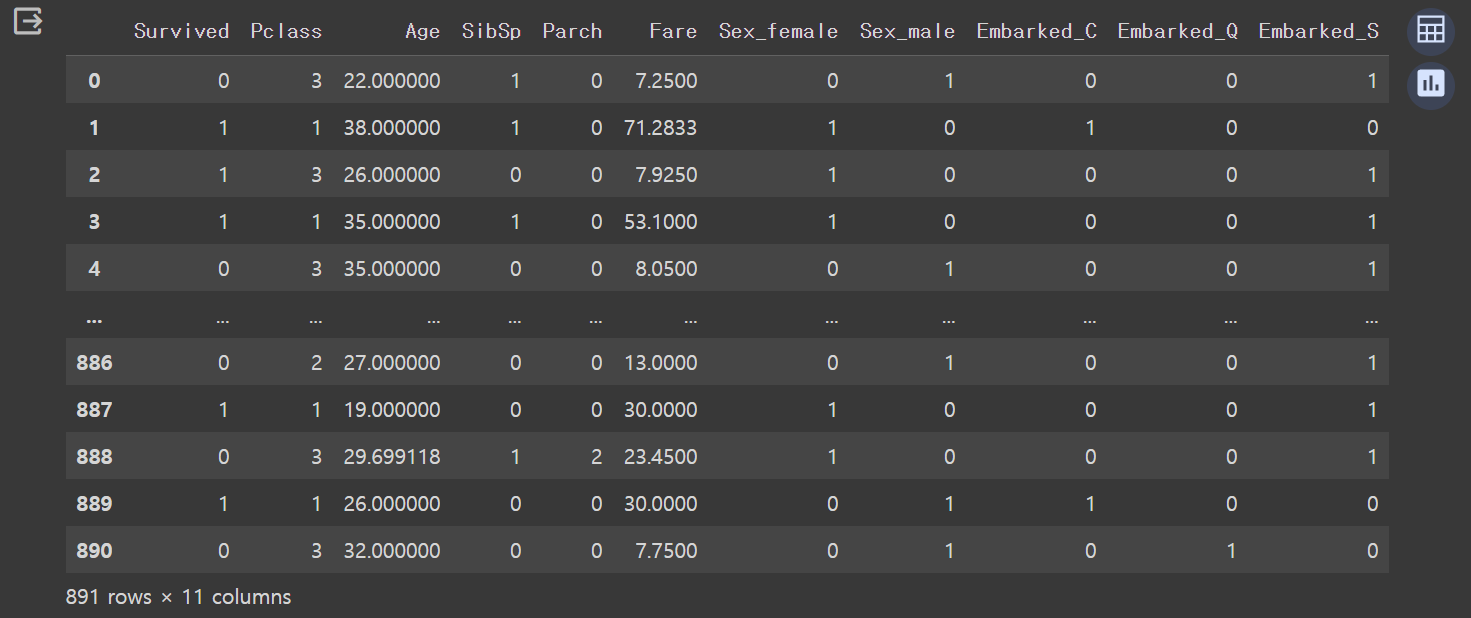
train_OHE = pd.get_dummies(train, columns = ['Sex', 'Embarked'])- .get_dummies() 메소드를 이용하여 'Sex'와 'Embarked'의 가변수(더미값)을 만들어줍니다.
- 결과
2) Normalization(정규화)
X = train_OHE.drop(columns = 'Survived') # input matrix
y = train_OHE.Survived # target vector
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# scaler.fit()
# scaler.transform()
temp = scaler.fit_transform(X.loc[:, ["Age", "Fare"]])
X["Age"] = temp[:, 0]
X["Fare"] = temp[:, 1]- 데이터를 Min-Max 스케일링을 사용하여 "Age"와 "Fare"를 정규화합니다.
- MinMaxScaler()를 통해 "Age", "Fare" column의 값을 0~1까지의 값으로 바꾸어줍니다.
- 그리고 바꾼 값을 다시 X에 적용시킵니다.
5. Training
1) 분류모델 호출
2) 평가지표 설정
3) 모델 학습
4) 모델 성능평가 비교
1) 분류모델 호출
from sklearn.linear_model import SGDClassifier # 1. Linear Classifier
from sklearn.linear_model import LogisticRegression # 2. Logistic Regression
from sklearn.tree import DecisionTreeClassifier # 3. Decision Tree
from sklearn.ensemble import RandomForestClassifier # 4. Random Forest2) 평가지표 설정
# 평가 지표
from sklearn.metrics import accuracy_score3) 모델 학습(fit)
# 호출한 분류 모델로 학습(fit)시키기
clf = SGDClassifier()
clf2 = LogisticRegression()
clf3 = DecisionTreeClassifier()
clf4 = RandomForestClassifier()
clf.fit(X, y)
clf2.fit(X, y)
clf3.fit(X, y)
clf4.fit(X, y)4)모델 성능평가 하기
pred = clf.predict(X)
pred2 = clf2.predict(X)
pred3 = clf3.predict(X)
pred4 = clf4.predict(X)
print("1. Linear Classifier, Accuracy for Training : %.4f" % accuracy_score(y, pred))
print("2. Logistic Regression, Accuracy for Training : %.4f" % accuracy_score(y, pred2))
print("3. Decision Tree, Accuracy for Training : %.4f" % accuracy_score(y, pred3))
print("4. Random Forest, Accuracy for Training : %.4f" % accuracy_score(y, pred4))
--------------------------------------------------------------------------------------------------
1. Linear Classifier, Accuracy for Training : 0.7160
2. Logistic Regression, Accuracy for Training : 0.8013
~~**3. Decision Tree, Accuracy for Training : 0.9820**~~
~~**4. Random Forest, Accuracy for Training : 0.9820**~~- Random Forest 모델과 Decision Tree 모델이 0.9820으로 가장 높게 나왔습니다.
6. Test(Predict)
1) Imputation(결측치 대체)
2) Normalization(정규화)
1) Imputation(결측치 대체)
test = test.drop(columns=["PassengerId", "Name", "Ticket", "Cabin"])
test = test.fillna(train.Age.mean()) #⭐⭐⭐
# -> train data에 대한 평가를 하는 것이기에 train data의 결측치 대체값을 적용합니다.
test = test.fillna(train.Fare.mean())
# => 마찬가지로 train data의 결측치 대체값을 적용합니다.
# Categorical feature encoding
test_OHE = pd.get_dummies(data = test, columns = ['Sex', 'Embarked'])- test data에 같은 feature engineering을 적용해줍니다.
- 결측치 처리시, train 데이터의 결측치 대체값을 적용해야 합니다. test 데이터의 결측치 대체값을 사용한다면 test 데이터의 학습이 되어버리고, train 데이터 모델의 성능을 평가할 수 없게 됩니다.
2) Normalization(정규화)
temp = scaler.transform(test_OHE.loc[:, ["Age", 'Fare']])
test_OHE.Age = temp[:, 0]
test_OHE.Fare = temp[:, 1]3) prediction ➡️ 예측결과 반환
result = clf.predict(test_OHE)
result2 = clf2.predict(test_OHE)
result3 = clf3.predict(test_OHE)
result4 = clf4.predict(test_OHE)7. 결과 파일 생성 및 추출
1) 학습한 모델 Submission 파일에 적용
submission["Survived"] = result4
submission- 예측결과가 가장 좋은 result4값의 모델인 RandomForest로 생존자 예측(Survived)를 수행합니다.
- submission 파일의 "Survived" column에 RandomForest 모델로 예측한 결과값을 삽입합니다.
submission.to_csv(basepath + "submission.csv", index = False)- 결과 파일인 submission.csv를 생성합니다.
- Kaggle 제출시, "index = False"는 공식처럼 외우고 쓰기
kaggle 제출 결과
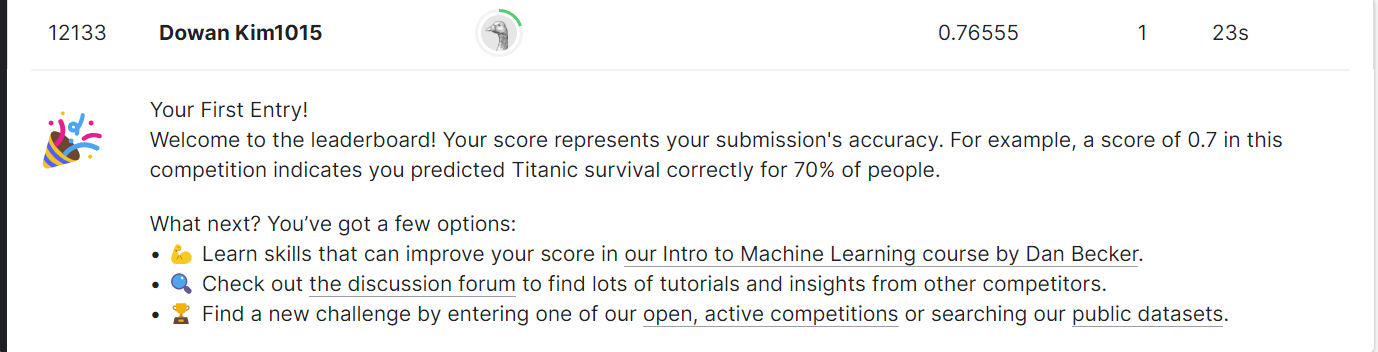
🙂 public score는 0.76555이고, 등수는 12085등이다.
🖥️ 사용한 코드 정리
- .isnull() : 데이터프레임 내의 결측값을 True로, 결측값이 아닌 값을 False로 반환합니다.
- .any(X) : 반복 가능한 데이터 x를 입력으로 받아 x의 요소 중 하나라도 참이 있으면 True를 리턴하고 x가 모두 거짓일 때만 False를 리턴
- axis = : 1일땐 열방향으로, 0일땐 행 방향으로 동작
- .fillna(X) : 데이터 내 결측값을 X로 채워서 처리합니다.
- .mean() : 해당 객체의 평균값
- .get_dummies(data = 데이터프레임객체, columns = [컬럼A, 컬럼B, ...]) : 가변수 생성
- predict() : 예측값 계산
- fit(): 데이터 변환을 위한 기존 정보 설정
- transform(): fit()을 통해 설정된 정보를 이용해 실제로 데이터를 변환
- MinMaxScaler() : 데이터 값을 0과 1 사이로 변환
💡시사점
- 전체적인 머신러닝의 간단한 Workflow를 익혔다
(데이터수집 -> Data preprocessing -> Feature engineering -> Training -> Test)- 프로젝트라고 하기에는 너무 간단한 것이여서 "실습"정도라고 하겠다.
- 코드를 다루는 것도 중요하지만 어떤 데이터를 활용하고, 전처리의 방식을 설정하는 것이 가장 중요하고 어려운 것 같다.
- 추후 머신러닝과 모델에 대해 더 자세히 배우고 익히면 데이터 튜닝과 모델링을 해서 titanic 프로젝트의 점수를 높여보겠다.

👍